 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Distributional Approach to Controlled Text Generation
Dec 21, 2020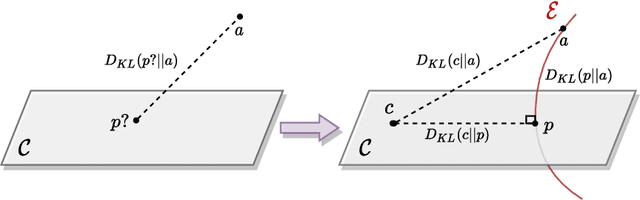

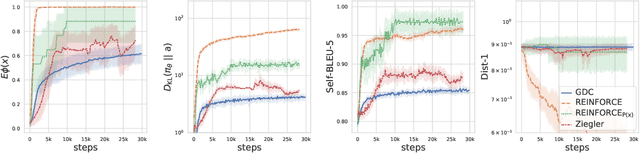
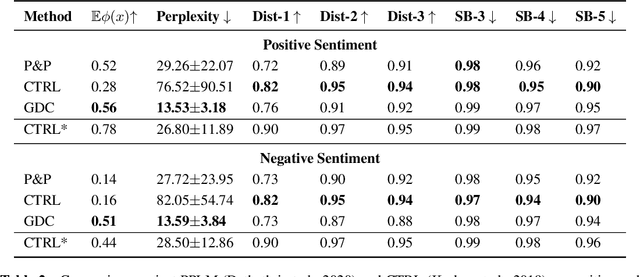
We propose a Distributional Approach to address Controlled Text Generation from pre-trained Language Models (LMs). This view permits to define, in a single formal framework, "pointwise" and "distributional" constraints over the target LM -- to our knowledge, this is the first approach with such generality -- while minimizing KL divergence with the initial LM distribution. The optimal target distribution is then uniquely determined as an explicit EBM (Energy-Based Model) representation. From that optimal representation we then train the target controlled autoregressive LM through an adaptive distributional variant of Policy Gradient. We conduct a first set of experiments over pointwise constraints showing the advantages of our approach over a set of baselines, in terms of obtaining a controlled LM balancing constraint satisfaction with divergence from the initial LM (GPT-2). We then perform experiments over distributional constraints, a unique feature of our approach, demonstrating its potential as a remedy to the problem of Bias in Language Models. Through an ablation study we show the effectiveness of our adaptive technique for obtaining faster convergence.
Distributional Reinforcement Learning for Energy-Based Sequential Models
Dec 18, 2019
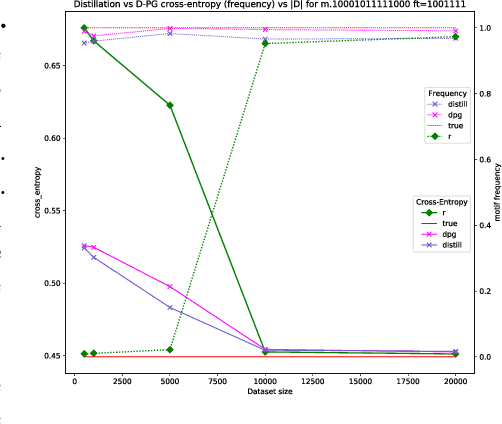
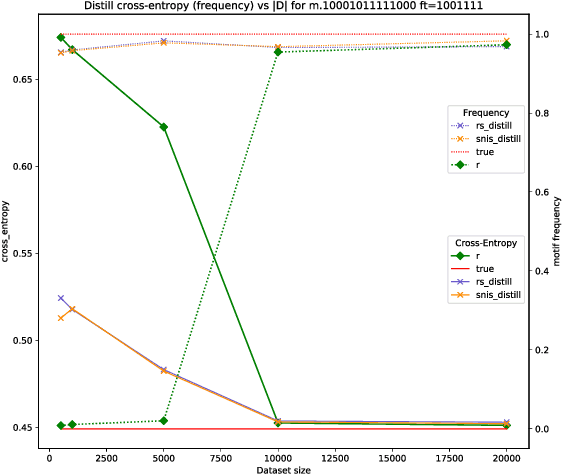
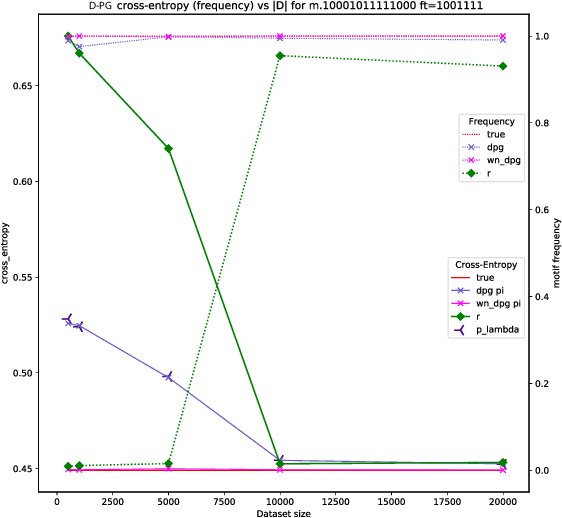
Global Autoregressive Models (GAMs) are a recent proposal [Parshakova et al., CoNLL 2019] for exploiting global properties of sequences for data-efficient learning of seq2seq models. In the first phase of training, an Energy-Based model (EBM) over sequences is derived. This EBM has high representational power, but is unnormalized and cannot be directly exploited for sampling. To address this issue [Parshakova et al., CoNLL 2019] proposes a distillation technique, which can only be applied under limited conditions. By relating this problem to Policy Gradient techniques in RL, but in a \emph{distributional} rather than \emph{optimization} perspective, we propose a general approach applicable to any sequential EBM. Its effectiveness is illustrated on GAM-based experiments.
Character-based NMT with Transformer
Nov 12, 2019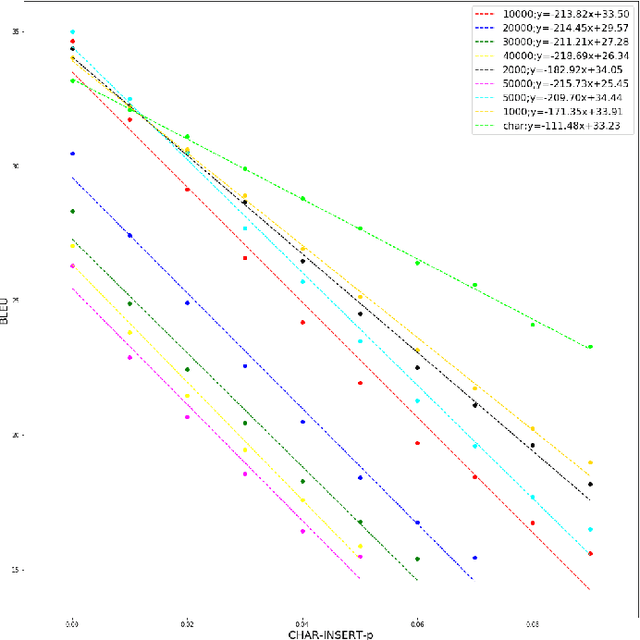
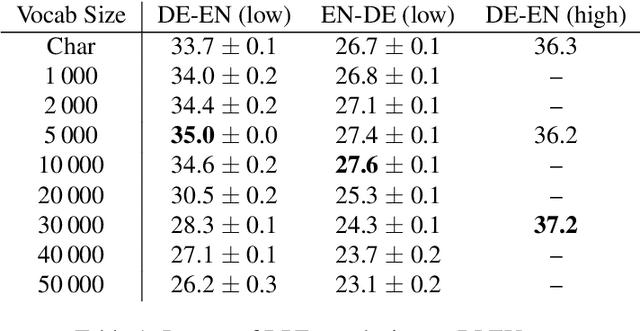
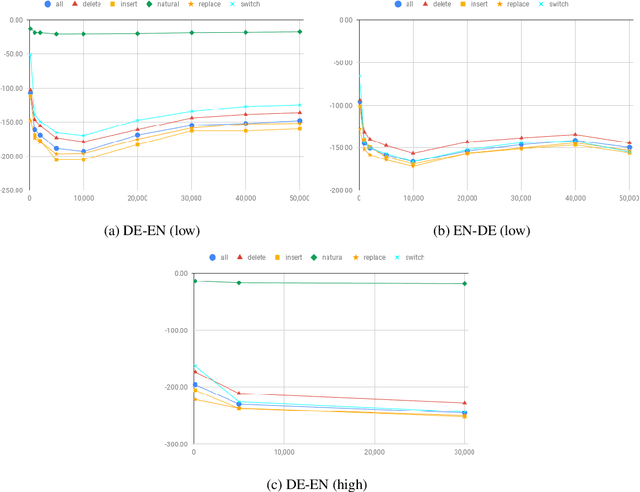
Character-based translation has several appealing advantages, but its performance is in general worse than a carefully tuned BPE baseline. In this paper we study the impact of character-based input and output with the Transformer architecture. In particular, our experiments on EN-DE show that character-based Transformer models are more robust than their BPE counterpart, both when translating noisy text, and when translating text from a different domain. To obtain comparable BLEU scores in clean, in-domain data and close the gap with BPE-based models we use known techniques to train deeper Transformer models.
Machine Translation of Restaurant Reviews: New Corpus for Domain Adaptation and Robustness
Oct 31, 2019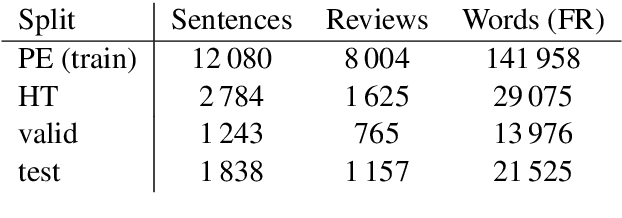


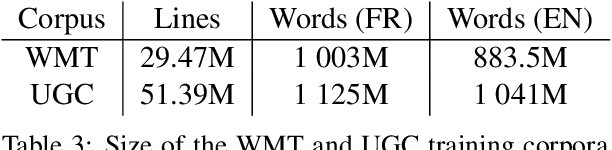
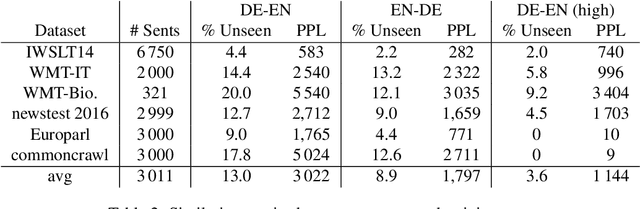
We share a French-English parallel corpus of Foursquare restaurant reviews (https://europe.naverlabs.com/research/natural-language-processing/machine-translation-of-restaurant-reviews), and define a new task to encourage research on Neural Machine Translation robustness and domain adaptation, in a real-world scenario where better-quality MT would be greatly beneficial. We discuss the challenges of such user-generated content, and train good baseline models that build upon the latest techniques for MT robustness. We also perform an extensive evaluation (automatic and human) that shows significant improvements over existing online systems. Finally, we propose task-specific metrics based on sentiment analysis or translation accuracy of domain-specific polysemous words.
Global Autoregressive Models for Data-Efficient Sequence Learning
Sep 19, 2019

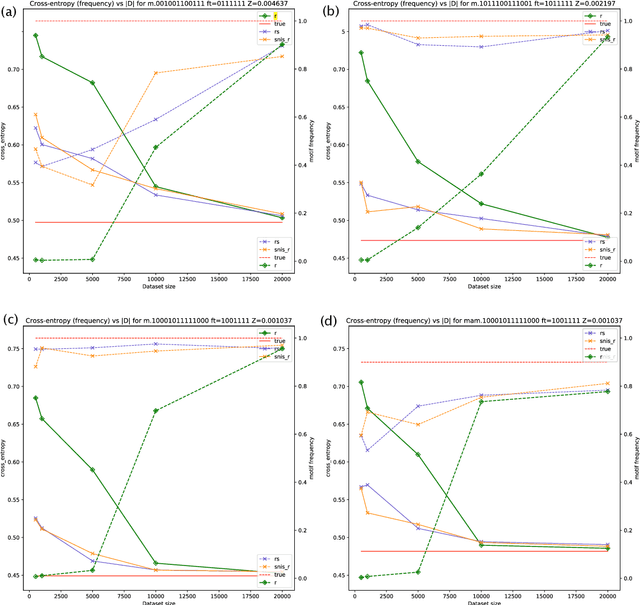
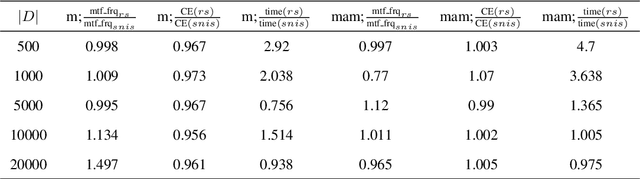
Standard autoregressive seq2seq models are easily trained by max-likelihood, but tend to show poor results under small-data conditions. We introduce a class of seq2seq models, GAMs (Global Autoregressive Models), which combine an autoregressive component with a log-linear component, allowing the use of global \textit{a priori} features to compensate for lack of data. We train these models in two steps. In the first step, we obtain an \emph{unnormalized} GAM that maximizes the likelihood of the data, but is improper for fast inference or evaluation. In the second step, we use this GAM to train (by distillation) a second autoregressive model that approximates the \emph{normalized} distribution associated with the GAM, and can be used for fast inference and evaluation. Our experiments focus on language modelling under synthetic conditions and show a strong perplexity reduction of using the second autoregressive model over the standard one.
Moment Matching Training for Neural Machine Translation: A Preliminary Study
Dec 28, 2018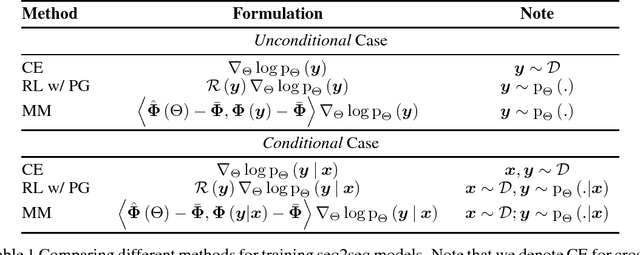


In previous works, neural sequence models have been shown to improve significantly if external prior knowledge can be provided, for instance by allowing the model to access the embeddings of explicit features during both training and inference. In this work, we propose a different point of view on how to incorporate prior knowledge in a principled way, using a moment matching framework. In this approach, the standard local cross-entropy training of the sequential model is combined with a moment matching training mode that encourages the equality of the expectations of certain predefined features between the model distribution and the empirical distribution. In particular, we show how to derive unbiased estimates of some stochastic gradients that are central to the training, and compare our framework with a formally related one: policy gradient training in reinforcement learning, pointing out some important differences in terms of the kinds of prior assumptions in both approaches. Our initial results are promising, showing the effectiveness of our proposed framework.
Symbolic Priors for RNN-based Semantic Parsing
Sep 20, 2018
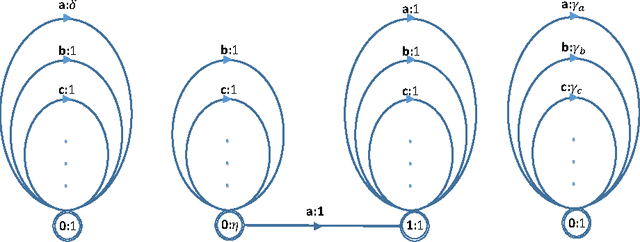

Seq2seq models based on Recurrent Neural Networks (RNNs) have recently received a lot of attention in the domain of Semantic Parsing for Question Answering. While in principle they can be trained directly on pairs (natural language utterances, logical forms), their performance is limited by the amount of available data. To alleviate this problem, we propose to exploit various sources of prior knowledge: the well-formedness of the logical forms is modeled by a weighted context-free grammar; the likelihood that certain entities present in the input utterance are also present in the logical form is modeled by weighted finite-state automata. The grammar and automata are combined together through an efficient intersection algorithm to form a soft guide ("background") to the RNN. We test our method on an extension of the Overnight dataset and show that it not only strongly improves over an RNN baseline, but also outperforms non-RNN models based on rich sets of hand-crafted features.
Log-Linear RNNs: Towards Recurrent Neural Networks with Flexible Prior Knowledge
Dec 16, 2016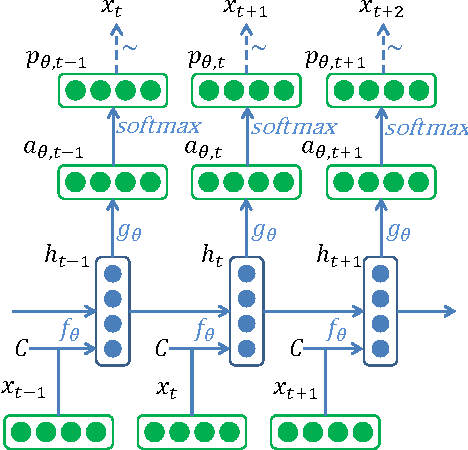

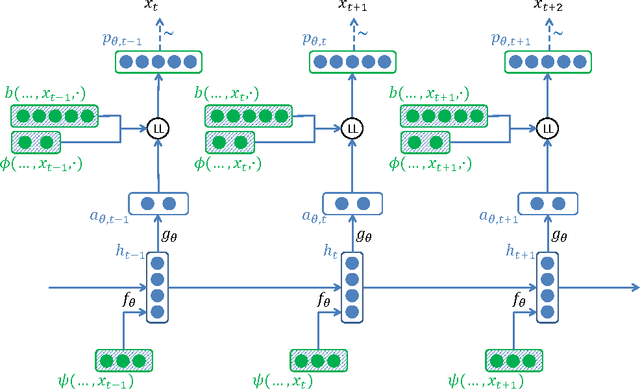

We introduce LL-RNNs (Log-Linear RNNs), an extension of Recurrent Neural Networks that replaces the softmax output layer by a log-linear output layer, of which the softmax is a special case. This conceptually simple move has two main advantages. First, it allows the learner to combat training data sparsity by allowing it to model words (or more generally, output symbols) as complex combinations of attributes without requiring that each combination is directly observed in the training data (as the softmax does). Second, it permits the inclusion of flexible prior knowledge in the form of a priori specified modular features, where the neural network component learns to dynamically control the weights of a log-linear distribution exploiting these features. We conduct experiments in the domain of language modelling of French, that exploit morphological prior knowledge and show an important decrease in perplexity relative to a baseline RNN. We provide other motivating iillustrations, and finally argue that the log-linear and the neural-network components contribute complementary strengths to the LL-RNN: the LL aspect allows the model to incorporate rich prior knowledge, while the NN aspect, according to the "representation learning" paradigm, allows the model to discover novel combination of characteristics.
LSTM-based Mixture-of-Experts for Knowledge-Aware Dialogues
May 05, 2016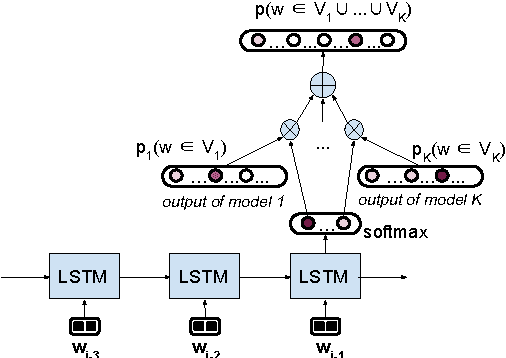

We introduce an LSTM-based method for dynamically integrating several word-prediction experts to obtain a conditional language model which can be good simultaneously at several subtasks. We illustrate this general approach with an application to dialogue where we integrate a neural chat model, good at conversational aspects, with a neural question-answering model, good at retrieving precise information from a knowledge-base, and show how the integration combines the strengths of the independent components. We hope that this focused contribution will attract attention on the benefits of using such mixtures of experts in NLP.
Assisting Composition of Email Responses: a Topic Prediction Approach
Oct 07, 2015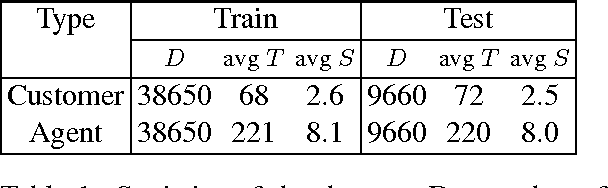
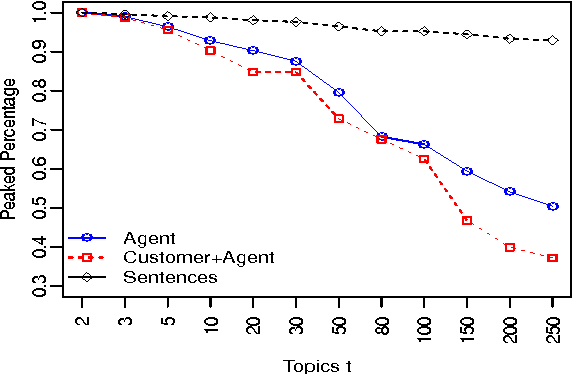
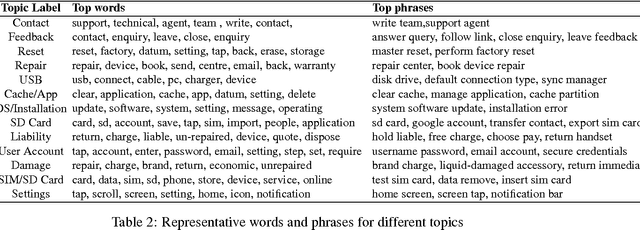
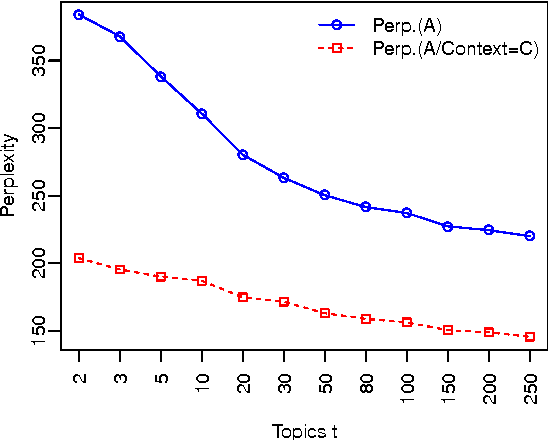
We propose an approach for helping agents compose email replies to customer requests. To enable that, we use LDA to extract latent topics from a collection of email exchanges. We then use these latent topics to label our data, obtaining a so-called "silver standard" topic labelling. We exploit this labelled set to train a classifier to: (i) predict the topic distribution of the entire agent's email response, based on features of the customer's email; and (ii) predict the topic distribution of the next sentence in the agent's reply, based on the customer's email features and on features of the agent's current sentence. The experimental results on a large email collection from a contact center in the tele- com domain show that the proposed ap- proach is effective in predicting the best topic of the agent's next sentence. In 80% of the cases, the correct topic is present among the top five recommended topics (out of fifty possible ones). This shows the potential of this method to be applied in an interactive setting, where the agent is presented a small list of likely topics to choose from for the next sentence.