 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Optimal Battery-Free Approach for Emission Reduction by Storing Solar Surplus in Building Thermal Mass
Mar 30, 2026Decarbonization in buildings calls for advanced control strategies that coordinate on-site renewables, grid electricity, and thermal demand. Literature approaches typically rely on demand side management strategies or on active energy storage, like batteries. However, the first solution often neglects carbon-aware objectives, and could lead to grid overload issues, while batteries entail environmental, end-of-life, and cost concerns. To overcome these limitations, we propose an optimal, carbon-aware optimization strategy that exploits the building's thermal mass as a passive storage, avoiding dedicated batteries. Specifically, when a surplus of renewable energy is available, our strategy computes the optimal share of surplus to store by temporarily adjusting the indoor temperature setpoint within comfort bounds. Thus, by explicitly accounting for forecasts of building energy consumption, solar production, and time-varying grid carbon intensity, our strategy enables emissions-aware load shifting while maintaining comfort. We evaluate the approach by simulating three TRNSYS models of the same system with different thermal mass. In all cases, the results show consistent reductions in grid electricity consumption with respect to a baseline that does not leverage surplus renewable generation. These findings highlight the potential of thermal-mass-based control for building decarbonization.
Explainable Condition Monitoring via Probabilistic Anomaly Detection Applied to Helicopter Transmissions
Mar 09, 2026We present a novel Explainable methodology for Condition Monitoring, relying on healthy data only. Since faults are rare events, we propose to focus on learning the probability distribution of healthy observations only, and detect Anomalies at runtime. This objective is achieved via the definition of probabilistic measures of deviation from nominality, which allow to detect and anticipate faults. The Bayesian perspective underpinning our approach allows us to perform Uncertainty Quantification to inform decisions. At the same time, we provide descriptive tools to enhance the interpretability of the results, supporting the deployment of the proposed strategy also in safety-critical applications. The methodology is validated experimentally on two use cases: a publicly available benchmark for Predictive Maintenance, and a real-world Helicopter Transmission dataset collected over multiple years. In both applications, the method achieves competitive detection performance with respect to state-of-the-art anomaly detection methods.
CoCoAFusE: Beyond Mixtures of Experts via Model Fusion
May 02, 2025Many learning problems involve multiple patterns and varying degrees of uncertainty dependent on the covariates. Advances in Deep Learning (DL) have addressed these issues by learning highly nonlinear input-output dependencies. However, model interpretability and Uncertainty Quantification (UQ) have often straggled behind. In this context, we introduce the Competitive/Collaborative Fusion of Experts (CoCoAFusE), a novel, Bayesian Covariates-Dependent Modeling technique. CoCoAFusE builds on the very philosophy behind Mixtures of Experts (MoEs), blending predictions from several simple sub-models (or "experts") to achieve high levels of expressiveness while retaining a substantial degree of local interpretability. Our formulation extends that of a classical Mixture of Experts by contemplating the fusion of the experts' distributions in addition to their more usual mixing (i.e., superimposition). Through this additional feature, CoCoAFusE better accommodates different scenarios for the intermediate behavior between generating mechanisms, resulting in tighter credible bounds on the response variable. Indeed, only resorting to mixing, as in classical MoEs, may lead to multimodality artifacts, especially over smooth transitions. Instead, CoCoAFusE can avoid these artifacts even under the same structure and priors for the experts, leading to greater expressiveness and flexibility in modeling. This new approach is showcased extensively on a suite of motivating numerical examples and a collection of real-data ones, demonstrating its efficacy in tackling complex regression problems where uncertainty is a key quantity of interest.
SINDy vs Hard Nonlinearities and Hidden Dynamics: a Benchmarking Study
Mar 01, 2024In this work we analyze the effectiveness of the Sparse Identification of Nonlinear Dynamics (SINDy) technique on three benchmark datasets for nonlinear identification, to provide a better understanding of its suitability when tackling real dynamical systems. While SINDy can be an appealing strategy for pursuing physics-based learning, our analysis highlights difficulties in dealing with unobserved states and non-smooth dynamics. Due to the ubiquity of these features in real systems in general, and control applications in particular, we complement our analysis with hands-on approaches to tackle these issues in order to exploit SINDy also in these challenging contexts.
Explainable data-driven modeling via mixture of experts: towards effective blending of grey and black-box models
Jan 30, 2024



Traditional models grounded in first principles often struggle with accuracy as the system's complexity increases. Conversely, machine learning approaches, while powerful, face challenges in interpretability and in handling physical constraints. Efforts to combine these models often often stumble upon difficulties in finding a balance between accuracy and complexity. To address these issues, we propose a comprehensive framework based on a "mixture of experts" rationale. This approach enables the data-based fusion of diverse local models, leveraging the full potential of first-principle-based priors. Our solution allows independent training of experts, drawing on techniques from both machine learning and system identification, and it supports both collaborative and competitive learning paradigms. To enhance interpretability, we penalize abrupt variations in the expert's combination. Experimental results validate the effectiveness of our approach in producing an interpretable combination of models closely resembling the target phenomena.
Analysis and development of a novel algorithm for the in-vehicle hand-usage of a smartphone
Aug 30, 2018
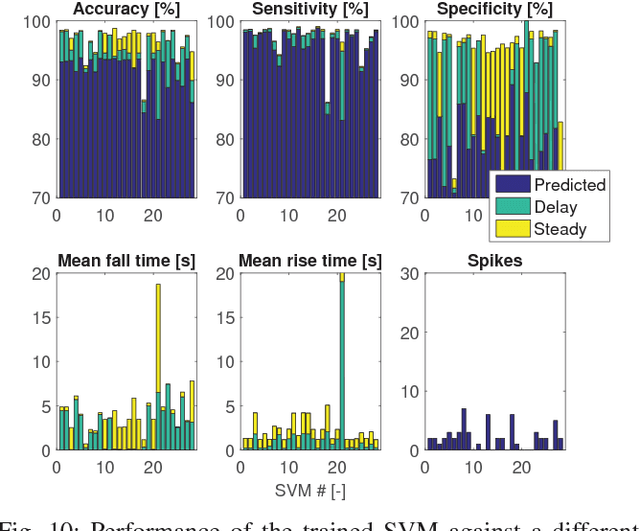

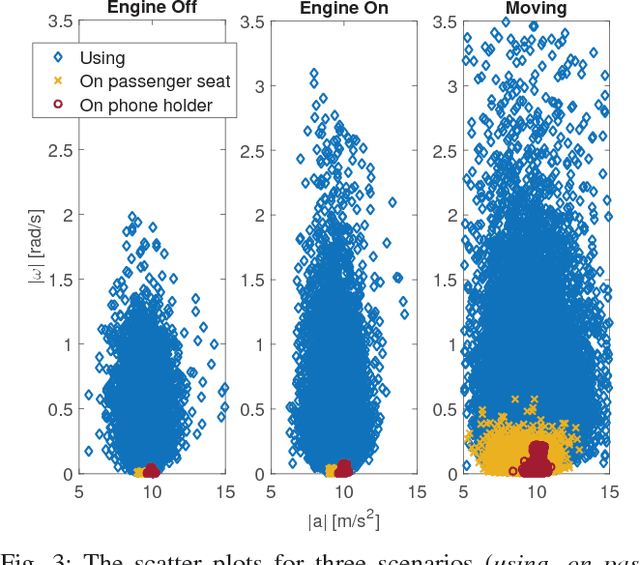
Smartphone usage while driving is unanimously considered to be a really dangerous habit due to strong correlation with road accidents. In this paper, the problem of detecting whether the driver is using the phone during a trip is addressed. To do this, high-frequency data from the triaxial inertial measurement unit (IMU) integrated in almost all modern phone is processed without relying on external inputs so as to provide a self-contained approach. By resorting to a frequency-domain analysis, it is possible to extract from the raw signals the useful information needed to detect when the driver is using the phone, without being affected by the effects that vehicle motion has on the same signals. The selected features are used to train a Support Vector Machine (SVM) algorithm. The performance of the proposed approach are analyzed and tested on experimental data collected during mixed naturalistic driving scenarios, proving the effectiveness of the proposed approach.