 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBroken Words, Broken Performance: Effect of Tokenization on Performance of LLMs
Dec 26, 2025



Tokenization is the first step in training any Large Language Model (LLM), where the text is split into a sequence of tokens as per the model's fixed vocabulary. This tokenization in LLMs is different from the traditional tokenization in NLP where the text is split into a sequence of "natural" words. In LLMs, a natural word may also be broken into multiple tokens due to limited vocabulary size of the LLMs (e.g., Mistral's tokenizer splits "martial" into "mart" and "ial"). In this paper, we hypothesize that such breaking of natural words negatively impacts LLM performance on various NLP tasks. To quantify this effect, we propose a set of penalty functions that compute a tokenization penalty for a given text for a specific LLM, indicating how "bad" the tokenization is. We establish statistical significance of our hypothesis on multiple NLP tasks for a set of different LLMs.
Beyond Static Datasets: A Behavior-Driven Entity-Specific Simulation to Overcome Data Scarcity and Train Effective Crypto Anti-Money Laundering Models
Jan 01, 2025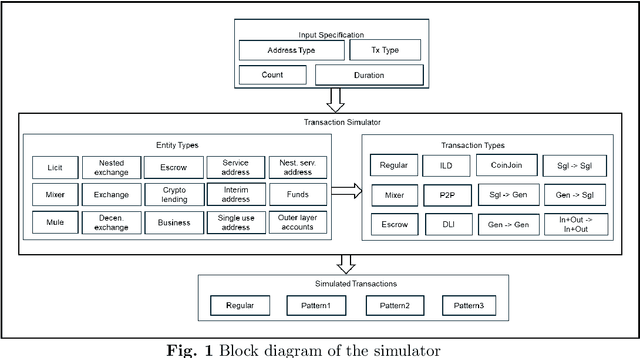
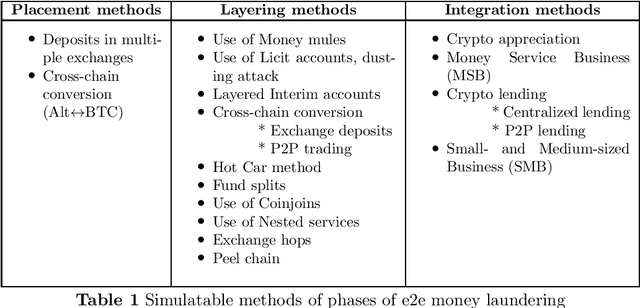
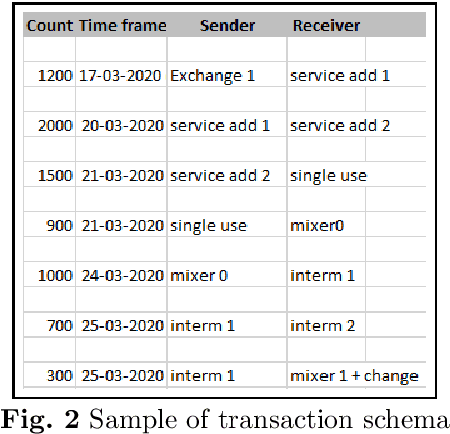
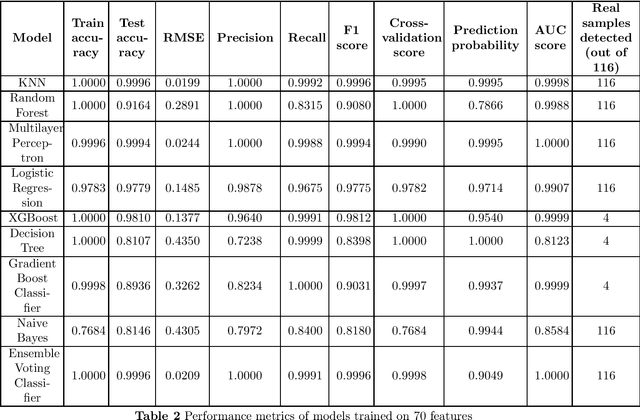
For different factors/reasons, ranging from inherent characteristics and features providing decentralization, enhanced privacy, ease of transactions, etc., to implied external hardships in enforcing regulations, contradictions in data sharing policies, etc., cryptocurrencies have been severely abused for carrying out numerous malicious and illicit activities including money laundering, darknet transactions, scams, terrorism financing, arm trades. However, money laundering is a key crime to be mitigated to also suspend the movement of funds from other illicit activities. Billions of dollars are annually being laundered. It is getting extremely difficult to identify money laundering in crypto transactions owing to many layering strategies available today, and rapidly evolving tactics, and patterns the launderers use to obfuscate the illicit funds. Many detection methods have been proposed ranging from naive approaches involving complete manual investigation to machine learning models. However, there are very limited datasets available for effectively training machine learning models. Also, the existing datasets are static and class-imbalanced, posing challenges for scalability and suitability to specific scenarios, due to lack of customization to varying requirements. This has been a persistent challenge in literature. In this paper, we propose behavior embedded entity-specific money laundering-like transaction simulation that helps in generating various transaction types and models the transactions embedding the behavior of several entities observed in this space. The paper discusses the design and architecture of the simulator, a custom dataset we generated using the simulator, and the performance of models trained on this synthetic data in detecting real addresses involved in money laundering.