 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBroken Words, Broken Performance: Effect of Tokenization on Performance of LLMs
Dec 26, 2025



Tokenization is the first step in training any Large Language Model (LLM), where the text is split into a sequence of tokens as per the model's fixed vocabulary. This tokenization in LLMs is different from the traditional tokenization in NLP where the text is split into a sequence of "natural" words. In LLMs, a natural word may also be broken into multiple tokens due to limited vocabulary size of the LLMs (e.g., Mistral's tokenizer splits "martial" into "mart" and "ial"). In this paper, we hypothesize that such breaking of natural words negatively impacts LLM performance on various NLP tasks. To quantify this effect, we propose a set of penalty functions that compute a tokenization penalty for a given text for a specific LLM, indicating how "bad" the tokenization is. We establish statistical significance of our hypothesis on multiple NLP tasks for a set of different LLMs.
Explainable Statute Prediction via Attention-based Model and LLM Prompting
Dec 26, 2025



In this paper, we explore the problem of automatic statute prediction where for a given case description, a subset of relevant statutes are to be predicted. Here, the term "statute" refers to a section, a sub-section, or an article of any specific Act. Addressing this problem would be useful in several applications such as AI-assistant for lawyers and legal question answering system. For better user acceptance of such Legal AI systems, we believe the predictions should also be accompanied by human understandable explanations. We propose two techniques for addressing this problem of statute prediction with explanations -- (i) AoS (Attention-over-Sentences) which uses attention over sentences in a case description to predict statutes relevant for it and (ii) LLMPrompt which prompts an LLM to predict as well as explain relevance of a certain statute. AoS uses smaller language models, specifically sentence transformers and is trained in a supervised manner whereas LLMPrompt uses larger language models in a zero-shot manner and explores both standard as well as Chain-of-Thought (CoT) prompting techniques. Both these models produce explanations for their predictions in human understandable forms. We compare statute prediction performance of both the proposed techniques with each other as well as with a set of competent baselines, across two popular datasets. Also, we evaluate the quality of the generated explanations through an automated counter-factual manner as well as through human evaluation.
Mining Supervisor Evaluation and Peer Feedback in Performance Appraisals
Dec 04, 2017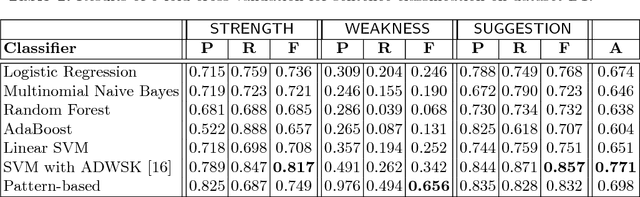
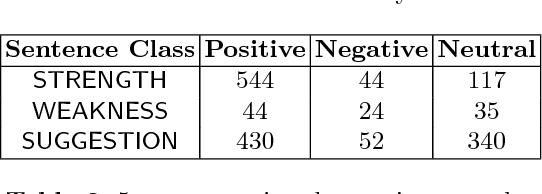
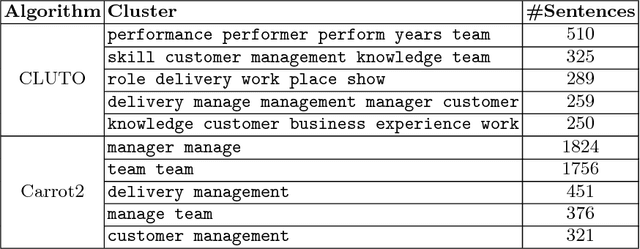
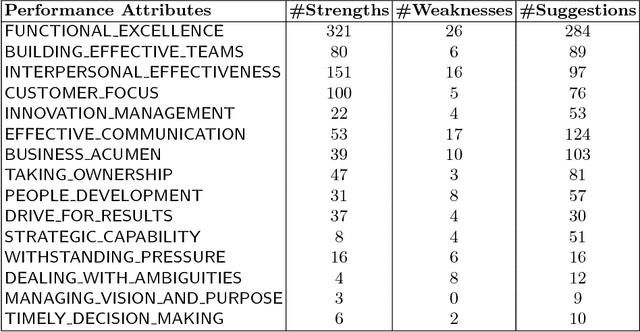
Performance appraisal (PA) is an important HR process to periodically measure and evaluate every employee's performance vis-a-vis the goals established by the organization. A PA process involves purposeful multi-step multi-modal communication between employees, their supervisors and their peers, such as self-appraisal, supervisor assessment and peer feedback. Analysis of the structured data and text produced in PA is crucial for measuring the quality of appraisals and tracking actual improvements. In this paper, we apply text mining techniques to produce insights from PA text. First, we perform sentence classification to identify strengths, weaknesses and suggestions of improvements found in the supervisor assessments and then use clustering to discover broad categories among them. Next we use multi-class multi-label classification techniques to match supervisor assessments to predefined broad perspectives on performance. Finally, we propose a short-text summarization technique to produce a summary of peer feedback comments for a given employee and compare it with manual summaries. All techniques are illustrated using a real-life dataset of supervisor assessment and peer feedback text produced during the PA of 4528 employees in a large multi-national IT company.