 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Prediction for Risk-Controlled Medical Entity Extraction Across Clinical Domains
Mar 01, 2026Large Language Models (LLMs) are increasingly used for medical entity extraction, yet their confidence scores are often miscalibrated, limiting safe deployment in clinical settings. We present a conformal prediction framework that provides finite-sample coverage guarantees for LLM-based extraction across two clinical domains. First, we extract structured entities from 1,000 FDA drug labels across eight sections using GPT-4.1, verified via FactScore-based atomic statement evaluation (97.7\% accuracy over 128,906 entities). Second, we extract radiological entities from MIMIC-CXR reports using the RadGraph schema with GPT-4.1 and Llama-4-Maverick, evaluated against physician annotations (entity F1: 0.81 to 0.84). Our central finding is that miscalibration direction reverses across domains: on well-structured FDA labels, models are underconfident, requiring modest conformal thresholds ($τ\approx 0.06$), while on free-text radiology reports, models are overconfident, demanding strict thresholds ($τ$ up to 0.99). Despite this heterogeneity, conformal prediction achieves target coverage ($\geq 90\%$) in both settings with manageable rejection rates (9--13\%). These results demonstrate that calibration is not a global model property but depends on document structure, extraction category, and model architecture, motivating domain-specific conformal calibration for safe clinical deployment.
Structured Extraction of Real World Medical Knowledge using LLMs for Summarization and Search
Dec 16, 2024Creation and curation of knowledge graphs can accelerate disease discovery and analysis in real-world data. While disease ontologies aid in biological data annotation, codified categories (SNOMED-CT, ICD10, CPT) may not capture patient condition nuances or rare diseases. Multiple disease definitions across data sources complicate ontology mapping and disease clustering. We propose creating patient knowledge graphs using large language model extraction techniques, allowing data extraction via natural language rather than rigid ontological hierarchies. Our method maps to existing ontologies (MeSH, SNOMED-CT, RxNORM, HPO) to ground extracted entities. Using a large ambulatory care EHR database with 33.6M patients, we demonstrate our method through the patient search for Dravet syndrome, which received ICD10 recognition in October 2020. We describe our construction of patient-specific knowledge graphs and symptom-based patient searches. Using confirmed Dravet syndrome ICD10 codes as ground truth, we employ LLM-based entity extraction to characterize patients in grounded ontologies. We then apply this method to identify Beta-propeller protein-associated neurodegeneration (BPAN) patients, demonstrating real-world discovery where no ground truth exists.
Towards Automated Penetration Testing: Introducing LLM Benchmark, Analysis, and Improvements
Oct 22, 2024



Hacking poses a significant threat to cybersecurity, inflicting billions of dollars in damages annually. To mitigate these risks, ethical hacking, or penetration testing, is employed to identify vulnerabilities in systems and networks. Recent advancements in large language models (LLMs) have shown potential across various domains, including cybersecurity. However, there is currently no comprehensive, open, end-to-end automated penetration testing benchmark to drive progress and evaluate the capabilities of these models in security contexts. This paper introduces a novel open benchmark for LLM-based automated penetration testing, addressing this critical gap. We first evaluate the performance of LLMs, including GPT-4o and Llama 3.1-405B, using the state-of-the-art PentestGPT tool. Our findings reveal that while Llama 3.1 demonstrates an edge over GPT-4o, both models currently fall short of performing fully automated, end-to-end penetration testing. Next, we advance the state-of-the-art and present ablation studies that provide insights into improving the PentestGPT tool. Our research illuminates the challenges LLMs face in each aspect of Pentesting, e.g. enumeration, exploitation, and privilege escalation. This work contributes to the growing body of knowledge on AI-assisted cybersecurity and lays the foundation for future research in automated penetration testing using large language models.
Secure Multiparty Generative AI
Sep 27, 2024



As usage of generative AI tools skyrockets, the amount of sensitive information being exposed to these models and centralized model providers is alarming. For example, confidential source code from Samsung suffered a data leak as the text prompt to ChatGPT encountered data leakage. An increasing number of companies are restricting the use of LLMs (Apple, Verizon, JPMorgan Chase, etc.) due to data leakage or confidentiality issues. Also, an increasing number of centralized generative model providers are restricting, filtering, aligning, or censoring what can be used. Midjourney and RunwayML, two of the major image generation platforms, restrict the prompts to their system via prompt filtering. Certain political figures are restricted from image generation, as well as words associated with women's health care, rights, and abortion. In our research, we present a secure and private methodology for generative artificial intelligence that does not expose sensitive data or models to third-party AI providers. Our work modifies the key building block of modern generative AI algorithms, e.g. the transformer, and introduces confidential and verifiable multiparty computations in a decentralized network to maintain the 1) privacy of the user input and obfuscation to the output of the model, and 2) introduce privacy to the model itself. Additionally, the sharding process reduces the computational burden on any one node, enabling the distribution of resources of large generative AI processes across multiple, smaller nodes. We show that as long as there exists one honest node in the decentralized computation, security is maintained. We also show that the inference process will still succeed if only a majority of the nodes in the computation are successful. Thus, our method offers both secure and verifiable computation in a decentralized network.
E3: Ensemble of Expert Embedders for Adapting Synthetic Image Detectors to New Generators Using Limited Data
Apr 12, 2024As generative AI progresses rapidly, new synthetic image generators continue to emerge at a swift pace. Traditional detection methods face two main challenges in adapting to these generators: the forensic traces of synthetic images from new techniques can vastly differ from those learned during training, and access to data for these new generators is often limited. To address these issues, we introduce the Ensemble of Expert Embedders (E3), a novel continual learning framework for updating synthetic image detectors. E3 enables the accurate detection of images from newly emerged generators using minimal training data. Our approach does this by first employing transfer learning to develop a suite of expert embedders, each specializing in the forensic traces of a specific generator. Then, all embeddings are jointly analyzed by an Expert Knowledge Fusion Network to produce accurate and reliable detection decisions. Our experiments demonstrate that E3 outperforms existing continual learning methods, including those developed specifically for synthetic image detection.
Explanation Container in Case-Based Biomedical Question-Answering
Dec 22, 2021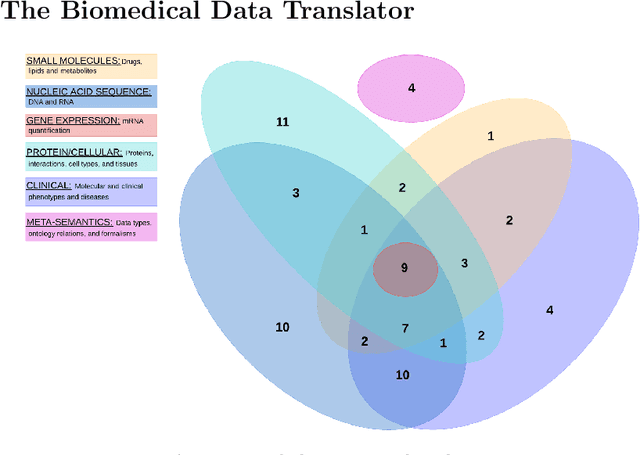
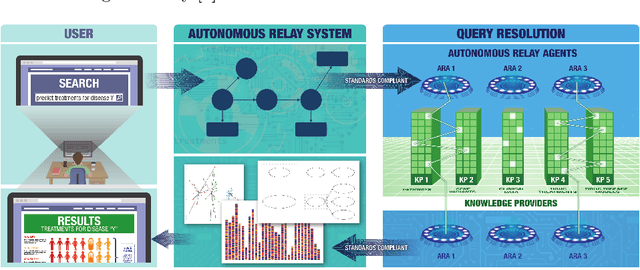
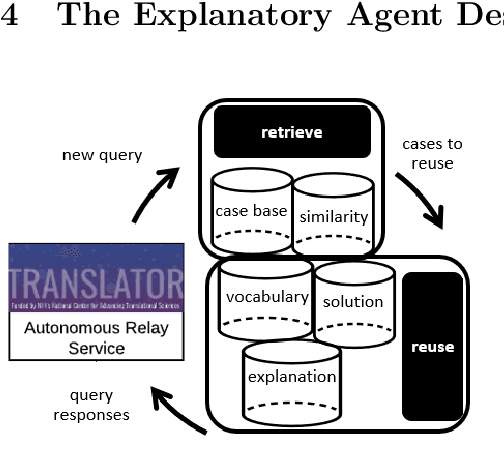
The National Center for Advancing Translational Sciences(NCATS) Biomedical Data Translator (Translator) aims to attenuate problems faced by translational scientists. Translator is a multi-agent architecture consisting of six autonomous relay agents (ARAs) and eight knowledge providers (KPs). In this paper, we present the design of the Explanatory Agent (xARA), a case-based ARA that answers biomedical queries by accessing multiple KPs, ranking results, and explaining the ranking of results. The Explanatory Agent is designed with five knowledge containers that include the four original knowledge containers and one additional container for explanation - the Explanation Container. The Explanation Container is case-based and designed with its own knowledge containers.
Knowledge-based XAI through CBR: There is more to explanations than models can tell
Aug 23, 2021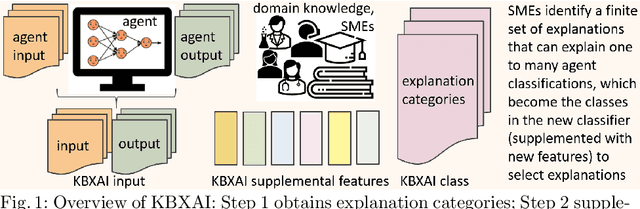

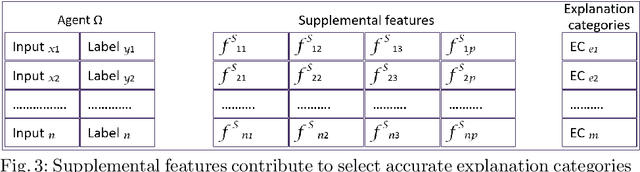
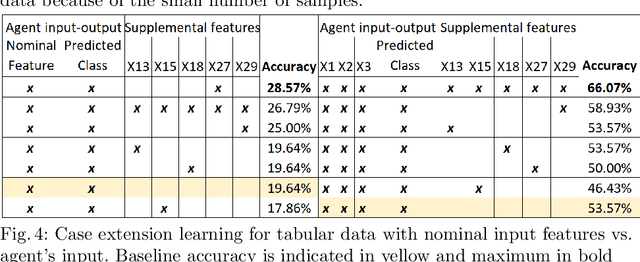
The underlying hypothesis of knowledge-based explainable artificial intelligence is the data required for data-centric artificial intelligence agents (e.g., neural networks) are less diverse in contents than the data required to explain the decisions of such agents to humans. The idea is that a classifier can attain high accuracy using data that express a phenomenon from one perspective whereas the audience of explanations can entail multiple stakeholders and span diverse perspectives. We hence propose to use domain knowledge to complement the data used by agents. We formulate knowledge-based explainable artificial intelligence as a supervised data classification problem aligned with the CBR methodology. In this formulation, the inputs are case problems composed of both the inputs and outputs of the data-centric agent and case solutions, the outputs, are explanation categories obtained from domain knowledge and subject matter experts. This formulation does not typically lead to an accurate classification, preventing the selection of the correct explanation category. Knowledge-based explainable artificial intelligence extends the data in this formulation by adding features aligned with domain knowledge that can increase accuracy when selecting explanation categories.