 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraint-Aware Optimization for Robust Protein Stability Prediction
Jun 06, 2026Multimodal $ΔΔG$ predictors integrating protein language models with inverse-folding representations achieve strong in-distribution accuracy on the Megascale dataset but exhibit limited robustness on out-of-distribution (OOD) proteins, persistent forward-reverse bias on paired-mutation benchmarks, and under-representation of rare stabilizing mutations. Existing approaches address these limitations primarily through additional architectural components, leaving optimization-level intervention comparatively underexplored. We introduce a constraint-aware optimization framework combining Balanced Mean Squared Error, a Siamese anti-symmetric regularizer, and a novel OOD-margin consistency loss on the per-position feature representation, requiring no architectural changes to the SPURS backbone. Across eleven benchmarks and three random seeds, the framework improves Spearman correlation on S669 from 0.486 to 0.540 ($σ=0.002$ across seeds), matching the published SPURS baseline (0.50) without architectural modification, and on S461 from 0.653 to 0.711, with consistent smaller gains on five additional OOD datasets. A controlled diagnostic on Ssym reveals that anti-symmetric training does not eliminate systematic forward-reverse bias, indicating that gains arise through implicit regularization rather than exact thermodynamic constraint enforcement.
Towards Emotionally Intelligent and Responsible Reinforcement Learning
Nov 13, 2025Personalized decision systems in healthcare and behavioral support often rely on static rule-based or engagement-maximizing heuristics that overlook users' emotional context and ethical constraints. Such approaches risk recommending insensitive or unsafe interventions, especially in domains involving serious mental illness, substance use disorders, or depression. To address this limitation, we propose a Responsible Reinforcement Learning (RRL) framework that integrates emotional and contextual understanding with ethical considerations into the sequential decision-making process. RRL formulates personalization as a Constrained Markov Decision Process (CMDP), where the agent optimizes engagement and adherence while ensuring emotional alignment and ethical safety. We introduce a multi-objective reward function that explicitly balances short-term behavioral engagement with long-term user well-being, and define an emotion-informed state representation that captures fluctuations in emotional readiness, affect, and risk. The proposed architecture can be instantiated with any RL algorithm (e.g., DQN, PPO) augmented with safety constraints or Lagrangian regularization. Conceptually, this framework operationalizes empathy and responsibility within machine learning policy optimization, bridging safe RL, affective computing and responsible AI. We discuss the implications of this approach for human-centric domains such as behavioral health, education, and digital therapeutics, and outline simulation-based validation paths for future empirical work. This paper aims to initiate a methodological conversation about ethically aligned reinforcement learning for emotionally aware and trustworthy personalization systems.
DENSE: Longitudinal Progress Note Generation with Temporal Modeling of Heterogeneous Clinical Notes Across Hospital Visits
Jul 18, 2025Progress notes are among the most clinically meaningful artifacts in an Electronic Health Record (EHR), offering temporally grounded insights into a patient's evolving condition, treatments, and care decisions. Despite their importance, they are severely underrepresented in large-scale EHR datasets. For instance, in the widely used Medical Information Mart for Intensive Care III (MIMIC-III) dataset, only about $8.56\%$ of hospital visits include progress notes, leaving gaps in longitudinal patient narratives. In contrast, the dataset contains a diverse array of other note types, each capturing different aspects of care. We present DENSE (Documenting Evolving Progress Notes from Scattered Evidence), a system designed to align with clinical documentation workflows by simulating how physicians reference past encounters while drafting progress notes. The system introduces a fine-grained note categorization and a temporal alignment mechanism that organizes heterogeneous notes across visits into structured, chronological inputs. At its core, DENSE leverages a clinically informed retrieval strategy to identify temporally and semantically relevant content from both current and prior visits. This retrieved evidence is used to prompt a large language model (LLM) to generate clinically coherent and temporally aware progress notes. We evaluate DENSE on a curated cohort of patients with multiple visits and complete progress note documentation. The generated notes demonstrate strong longitudinal fidelity, achieving a temporal alignment ratio of $1.089$, surpassing the continuity observed in original notes. By restoring narrative coherence across fragmented documentation, our system supports improved downstream tasks such as summarization, predictive modeling, and clinical decision support, offering a scalable solution for LLM-driven note synthesis in real-world healthcare settings.
D3FL: Data Distribution and Detrending for Robust Federated Learning in Non-linear Time-series Data
Jul 15, 2025With advancements in computing and communication technologies, the Internet of Things (IoT) has seen significant growth. IoT devices typically collect data from various sensors, such as temperature, humidity, and energy meters. Much of this data is temporal in nature. Traditionally, data from IoT devices is centralized for analysis, but this approach introduces delays and increased communication costs. Federated learning (FL) has emerged as an effective alternative, allowing for model training across distributed devices without the need to centralize data. In many applications, such as smart home energy and environmental monitoring, the data collected by IoT devices across different locations can exhibit significant variation in trends and seasonal patterns. Accurately forecasting such non-stationary, non-linear time-series data is crucial for applications like energy consumption estimation and weather forecasting. However, these data variations can severely impact prediction accuracy. The key contributions of this paper are: (1) Investigating how non-linear, non-stationary time-series data distributions, like generalized extreme value (gen-extreme) and log norm distributions, affect FL performance. (2) Analyzing how different detrending techniques for non-linear time-series data influence the forecasting model's performance in a FL setup. We generated several synthetic time-series datasets using non-linear data distributions and trained an LSTM-based forecasting model using both centralized and FL approaches. Additionally, we evaluated the impact of detrending on real-world datasets with non-linear time-series data distributions. Our experimental results show that: (1) FL performs worse than centralized approaches when dealing with non-linear data distributions. (2) The use of appropriate detrending techniques improves FL performance, reducing loss across different data distributions.
CLI-RAG: A Retrieval-Augmented Framework for Clinically Structured and Context Aware Text Generation with LLMs
Jul 09, 2025Large language models (LLMs), including zero-shot and few-shot paradigms, have shown promising capabilities in clinical text generation. However, real-world applications face two key challenges: (1) patient data is highly unstructured, heterogeneous, and scattered across multiple note types and (2) clinical notes are often long and semantically dense, making naive prompting infeasible due to context length constraints and the risk of omitting clinically relevant information. We introduce CLI-RAG (Clinically Informed Retrieval-Augmented Generation), a domain-specific framework for structured and clinically grounded text generation using LLMs. It incorporates a novel hierarchical chunking strategy that respects clinical document structure and introduces a task-specific dual-stage retrieval mechanism. The global stage identifies relevant note types using evidence-based queries, while the local stage extracts high-value content within those notes creating relevance at both document and section levels. We apply the system to generate structured progress notes for individual hospital visits using 15 clinical note types from the MIMIC-III dataset. Experiments show that it preserves temporal and semantic alignment across visits, achieving an average alignment score of 87.7%, surpassing the 80.7% baseline from real clinician-authored notes. The generated outputs also demonstrate high consistency across LLMs, reinforcing deterministic behavior essential for reproducibility, reliability, and clinical trust.
LETS-GZSL: A Latent Embedding Model for Time Series Generalized Zero Shot Learning
Jul 25, 2022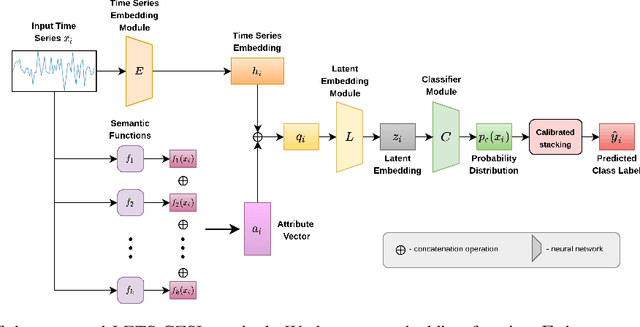
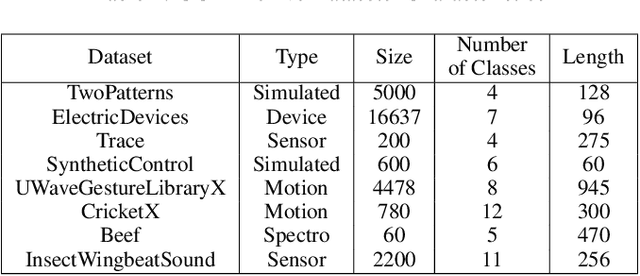
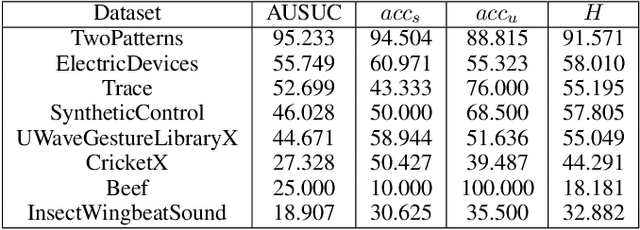
One of the recent developments in deep learning is generalized zero-shot learning (GZSL), which aims to recognize objects from both seen and unseen classes, when only the labeled examples from seen classes are provided. Over the past couple of years, GZSL has picked up traction and several models have been proposed to solve this problem. Whereas an extensive amount of research on GZSL has been carried out in fields such as computer vision and natural language processing, no such research has been carried out to deal with time series data. GZSL is used for applications such as detecting abnormalities from ECG and EEG data and identifying unseen classes from sensor, spectrograph and other devices' data. In this regard, we propose a Latent Embedding for Time Series - GZSL (LETS-GZSL) model that can solve the problem of GZSL for time series classification (TSC). We utilize an embedding-based approach and combine it with attribute vectors to predict the final class labels. We report our results on the widely popular UCR archive datasets. Our framework is able to achieve a harmonic mean value of at least 55% on most of the datasets except when the number of unseen classes is greater than 3 or the amount of data is very low (less than 100 training examples).
Similarity Learning based Few Shot Learning for ECG Time Series Classification
Jan 31, 2022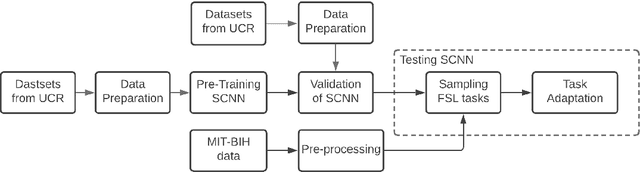
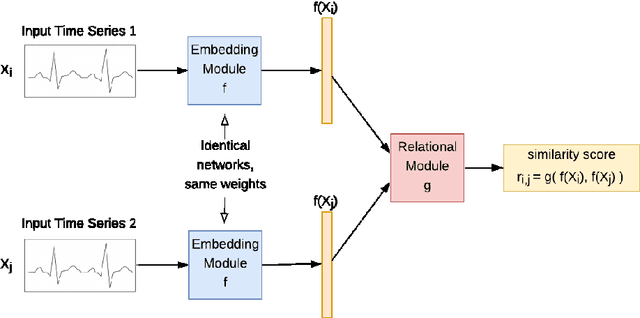

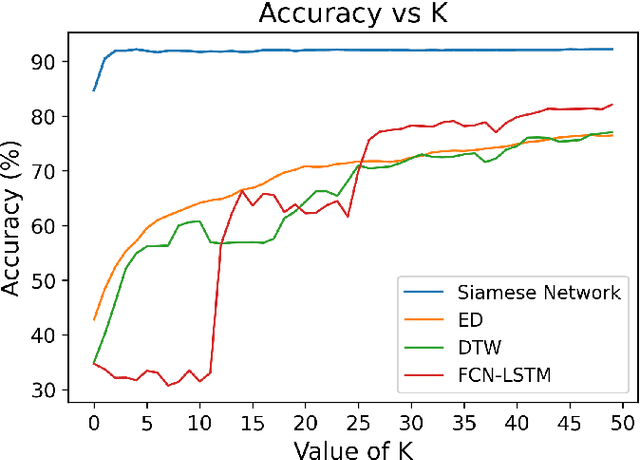
Using deep learning models to classify time series data generated from the Internet of Things (IoT) devices requires a large amount of labeled data. However, due to constrained resources available in IoT devices, it is often difficult to accommodate training using large data sets. This paper proposes and demonstrates a Similarity Learning-based Few Shot Learning for ECG arrhythmia classification using Siamese Convolutional Neural Networks. Few shot learning resolves the data scarcity issue by identifying novel classes from very few labeled examples. Few Shot Learning relies first on pretraining the model on a related relatively large database, and then the learning is used for further adaptation towards few examples available per class. Our experiments evaluate the performance accuracy with respect to K (number of instances per class) for ECG time series data classification. The accuracy with 5- shot learning is 92.25% which marginally improves with further increase in K. We also compare the performance of our method against other well-established similarity learning techniques such as Dynamic Time Warping (DTW), Euclidean Distance (ED), and a deep learning model - Long Short Term Memory Fully Convolutional Network (LSTM-FCN) with the same amount of data and conclude that our method outperforms them for a limited dataset size. For K=5, the accuracies obtained are 57%, 54%, 33%, and 92% approximately for ED, DTW, LSTM-FCN, and SCNN, respectively.
Use of Remote Sensing Data to Identify Air Pollution Signatures in India
Dec 01, 2020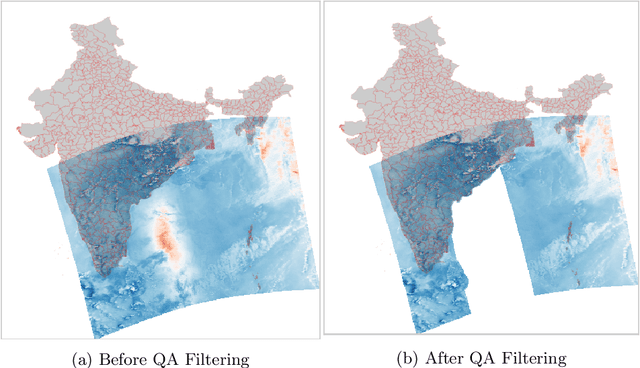
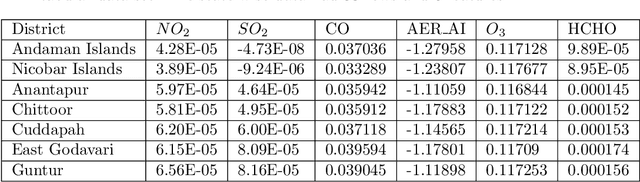
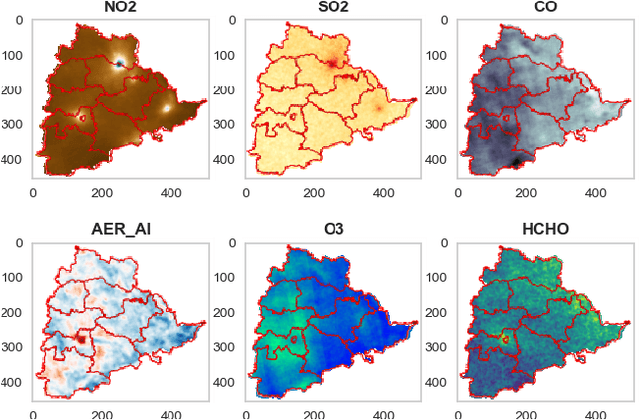
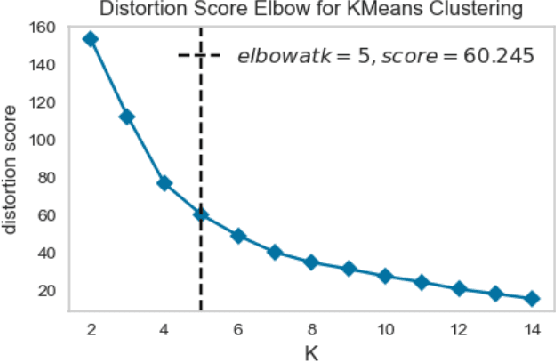
Air quality has major impact on a country's socio-economic position and identifying major air pollution sources is at the heart of tackling the issue. Spatially and temporally distributed air quality data acquisition across a country as varied as India has been a challenge to such analysis. The launch of the Sentinel-5P satellite has helped in the observation of a wider variety of air pollutants than measured before at a global scale on a daily basis. In this chapter, spatio-temporal multi pollutant data retrieved from Sentinel-5P satellite is used to cluster states as well as districts in India and associated average monthly pollution signature and trends depicted by each of the clusters are derived and presented.The clustering signatures can be used to identify states and districts based on the types of pollutants emitted by various pollution sources.
NANCY: Neural Adaptive Network Coding methodologY for video distribution over wireless networks
Aug 21, 2020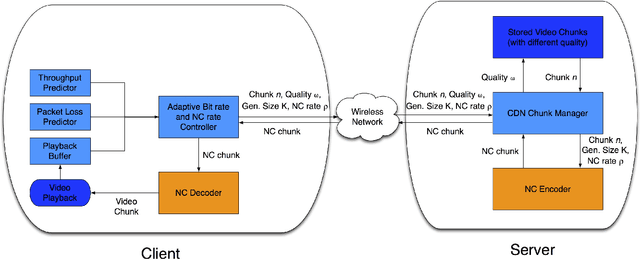
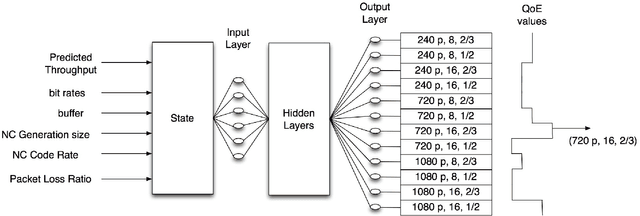
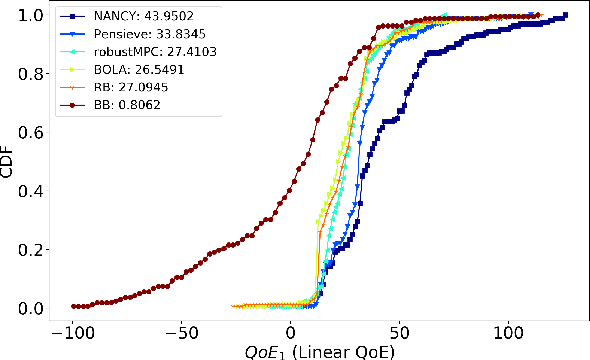
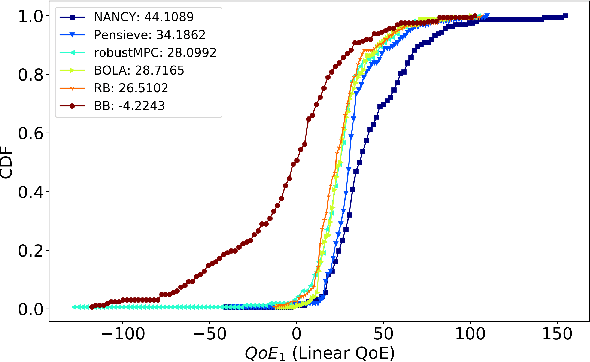
This paper presents NANCY, a system that generates adaptive bit rates (ABR) for video and adaptive network coding rates (ANCR) using reinforcement learning (RL) for video distribution over wireless networks. NANCY trains a neural network model with rewards formulated as quality of experience (QoE) metrics. It performs joint optimization in order to select: (i) adaptive bit rates for future video chunks to counter variations in available bandwidth and (ii) adaptive network coding rates to encode the video chunk slices to counter packet losses in wireless networks. We present the design and implementation of NANCY, and evaluate its performance compared to state-of-the-art video rate adaptation algorithms including Pensieve and robustMPC. Our results show that NANCY provides 29.91% and 60.34% higher average QoE than Pensieve and robustMPC, respectively.