 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of High-dimensional Time Series in Spectral Domain using Explainable Features
Aug 15, 2024Interpretable classification of time series presents significant challenges in high dimensions. Traditional feature selection methods in the frequency domain often assume sparsity in spectral density matrices (SDMs) or their inverses, which can be restrictive for real-world applications. In this article, we propose a model-based approach for classifying high-dimensional stationary time series by assuming sparsity in the difference between inverse SDMs. Our approach emphasizes the interpretability of model parameters, making it especially suitable for fields like neuroscience, where understanding differences in brain network connectivity across various states is crucial. The estimators for model parameters demonstrate consistency under appropriate conditions. We further propose using standard deep learning optimizers for parameter estimation, employing techniques such as mini-batching and learning rate scheduling. Additionally, we introduce a method to screen the most discriminatory frequencies for classification, which exhibits the sure screening property under general conditions. The flexibility of the proposed model allows the significance of covariates to vary across frequencies, enabling nuanced inferences and deeper insights into the underlying problem. The novelty of our method lies in the interpretability of the model parameters, addressing critical needs in neuroscience. The proposed approaches have been evaluated on simulated examples and the `Alert-vs-Drowsy' EEG dataset.
Stylized Projected GAN: A Novel Architecture for Fast and Realistic Image Generation
Jul 30, 2023Generative Adversarial Networks are used for generating the data using a generator and a discriminator, GANs usually produce high-quality images, but training GANs in an adversarial setting is a difficult task. GANs require high computation power and hyper-parameter regularization for converging. Projected GANs tackle the training difficulty of GANs by using transfer learning to project the generated and real samples into a pre-trained feature space. Projected GANs improve the training time and convergence but produce artifacts in the generated images which reduce the quality of the generated samples, we propose an optimized architecture called Stylized Projected GANs which integrates the mapping network of the Style GANs with Skip Layer Excitation of Fast GAN. The integrated modules are incorporated within the generator architecture of the Fast GAN to mitigate the problem of artifacts in the generated images.
Granger Causality using Neural Networks
Aug 07, 2022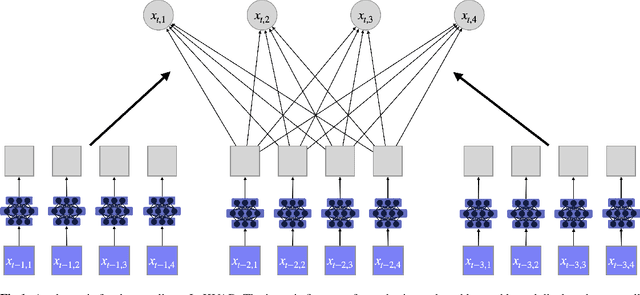
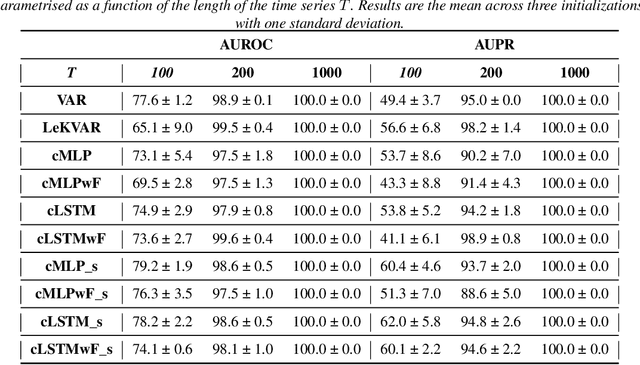
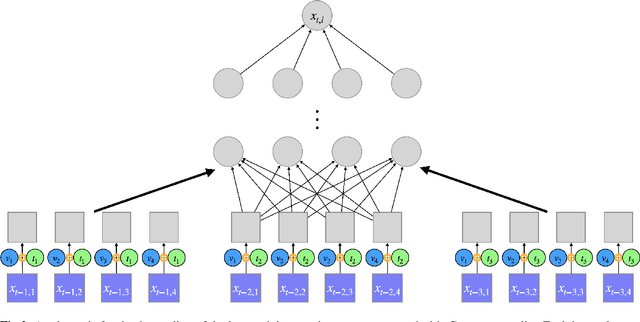
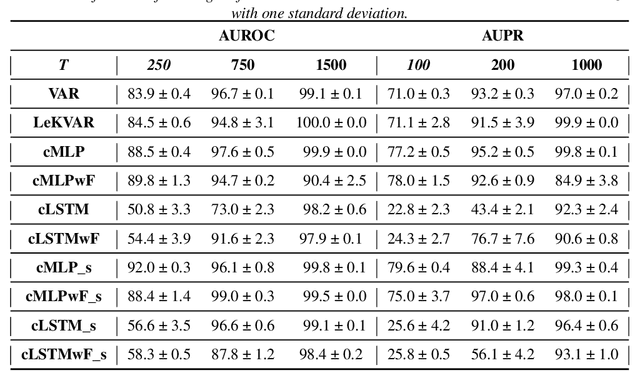
The Granger Causality (GC) test is a famous statistical hypothesis test for investigating if the past of one time series affects the future of the other. It helps in answering the question whether one time series is helpful in forecasting. Standard traditional approaches to Granger causality detection commonly assume linear dynamics, but such simplification does not hold in many real-world applications, e.g., neuroscience or genomics that are inherently non-linear. In such cases, imposing linear models such as Vector Autoregressive (VAR) models can lead to inconsistent estimation of true Granger Causal interactions. Machine Learning (ML) can learn the hidden patterns in the datasets specifically Deep Learning (DL) has shown tremendous promise in learning the non-linear dynamics of complex systems. Recent work of Tank et al propose to overcome the issue of linear simplification in VAR models by using neural networks combined with sparsity-inducing penalties on the learn-able weights. In this work, we build upon ideas introduced by Tank et al. We propose several new classes of models that can handle underlying non-linearity. Firstly, we present the Learned Kernal VAR(LeKVAR) model-an extension of VAR models that also learns kernel parametrized by a neural net. Secondly, we show one can directly decouple lags and individual time series importance via decoupled penalties. This decoupling provides better scaling and allows us to embed lag selection into RNNs. Lastly, we propose a new training algorithm that supports mini-batching, and it is compatible with commonly used adaptive optimizers such as Adam.he proposed techniques are evaluated on several simulated datasets inspired by real-world applications.We also apply these methods to the Electro-Encephalogram (EEG) data for an epilepsy patient to study the evolution of GC before , during and after seizure across the 19 EEG channels.