 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResNetVLLM-2: Addressing ResNetVLLM's Multi-Modal Hallucinations
Apr 20, 2025Large Language Models (LLMs) have transformed natural language processing (NLP) tasks, but they suffer from hallucination, generating plausible yet factually incorrect content. This issue extends to Video-Language Models (VideoLLMs), where textual descriptions may inaccurately represent visual content, resulting in multi-modal hallucinations. In this paper, we address hallucination in ResNetVLLM, a video-language model combining ResNet visual encoders with LLMs. We introduce a two-step protocol: (1) a faithfulness detection strategy that uses a modified Lynx model to assess semantic alignment between generated captions and ground-truth video references, and (2) a hallucination mitigation strategy using Retrieval-Augmented Generation (RAG) with an ad-hoc knowledge base dynamically constructed during inference. Our enhanced model, ResNetVLLM-2, reduces multi-modal hallucinations by cross-verifying generated content against external knowledge, improving factual consistency. Evaluation on the ActivityNet-QA benchmark demonstrates a substantial accuracy increase from 54.8% to 65.3%, highlighting the effectiveness of our hallucination detection and mitigation strategies in enhancing video-language model reliability.
ResNetVLLM -- Multi-modal Vision LLM for the Video Understanding Task
Apr 20, 2025In this paper, we introduce ResNetVLLM (ResNet Vision LLM), a novel cross-modal framework for zero-shot video understanding that integrates a ResNet-based visual encoder with a Large Language Model (LLM. ResNetVLLM addresses the challenges associated with zero-shot video models by avoiding reliance on pre-trained video understanding models and instead employing a non-pretrained ResNet to extract visual features. This design ensures the model learns visual and semantic representations within a unified architecture, enhancing its ability to generate accurate and contextually relevant textual descriptions from video inputs. Our experimental results demonstrate that ResNetVLLM achieves state-of-the-art performance in zero-shot video understanding (ZSVU) on several benchmarks, including MSRVTT-QA, MSVD-QA, TGIF-QA FrameQA, and ActivityNet-QA.
A Comprehensive Study of Vision Transformers in Image Classification Tasks
Dec 05, 2023



Image Classification is a fundamental task in the field of computer vision that frequently serves as a benchmark for gauging advancements in Computer Vision. Over the past few years, significant progress has been made in image classification due to the emergence of deep learning. However, challenges still exist, such as modeling fine-grained visual information, high computation costs, the parallelism of the model, and inconsistent evaluation protocols across datasets. In this paper, we conduct a comprehensive survey of existing papers on Vision Transformers for image classification. We first introduce the popular image classification datasets that influenced the design of models. Then, we present Vision Transformers models in chronological order, starting with early attempts at adapting attention mechanism to vision tasks followed by the adoption of vision transformers, as they have demonstrated success in capturing intricate patterns and long-range dependencies within images. Finally, we discuss open problems and shed light on opportunities for image classification to facilitate new research ideas.
An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels
Mar 21, 2022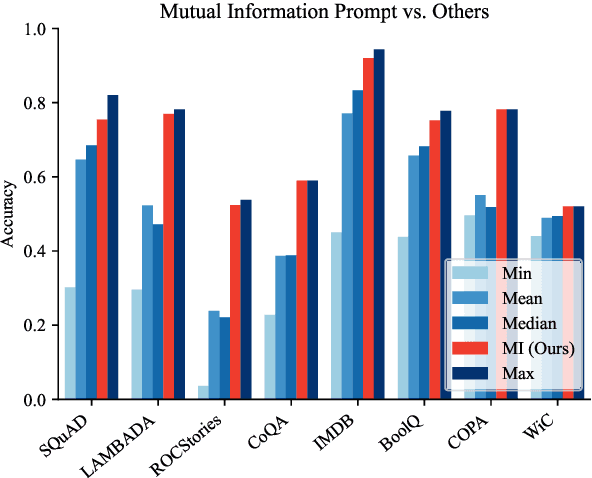
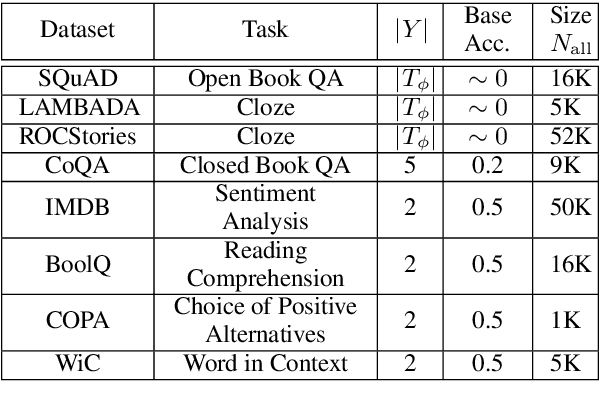
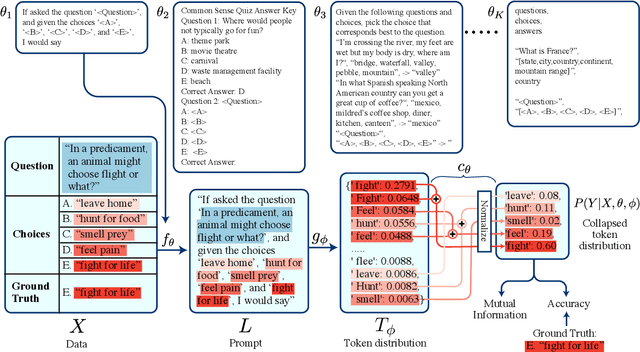
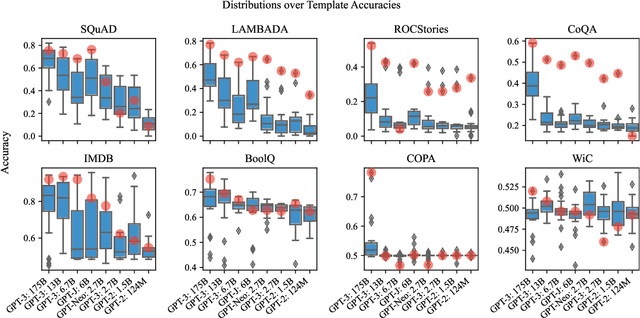
Pre-trained language models derive substantial linguistic and factual knowledge from the massive corpora on which they are trained, and prompt engineering seeks to align these models to specific tasks. Unfortunately, existing prompt engineering methods require significant amounts of labeled data, access to model parameters, or both. We introduce a new method for selecting prompt templates \textit{without labeled examples} and \textit{without direct access to the model}. Specifically, over a set of candidate templates, we choose the template that maximizes the mutual information between the input and the corresponding model output. Across 8 datasets representing 7 distinct NLP tasks, we show that when a template has high mutual information, it also has high accuracy on the task. On the largest model, selecting prompts with our method gets 90\% of the way from the average prompt accuracy to the best prompt accuracy and requires no ground truth labels.
A Transfer Learning End-to-End Arabic Text-To-Speech Deep Architecture
Jul 22, 2020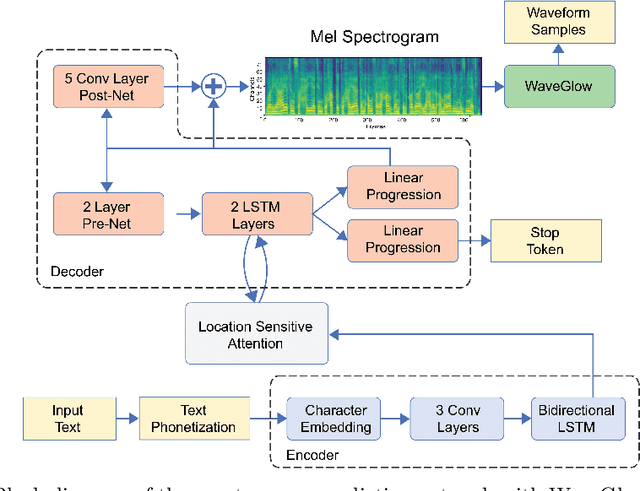
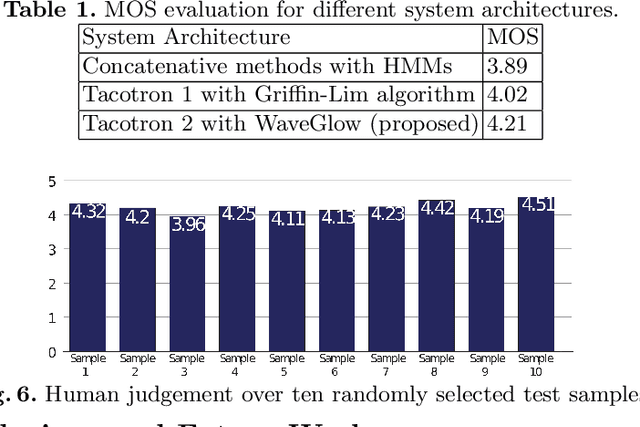
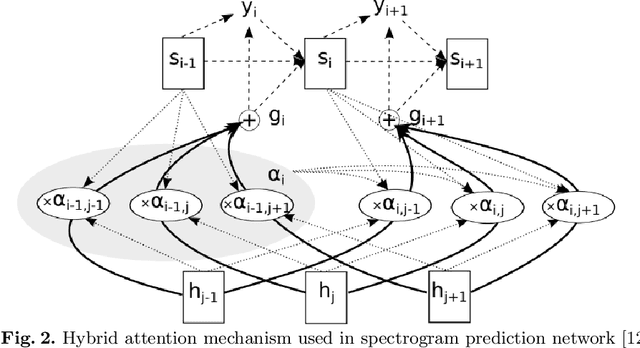
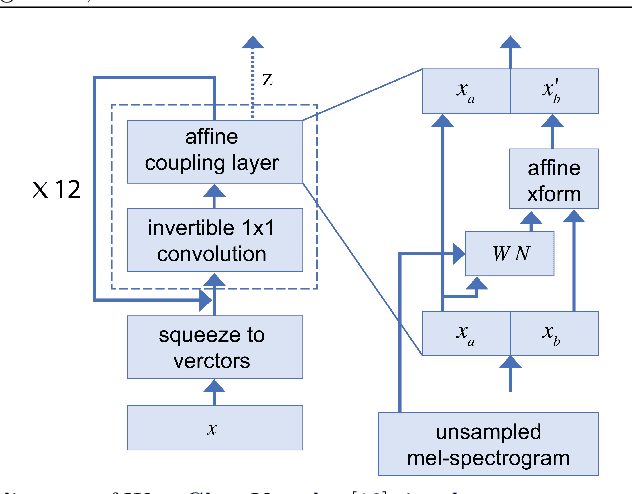
Speech synthesis is the artificial production of human speech. A typical text-to-speech system converts a language text into a waveform. There exist many English TTS systems that produce mature, natural, and human-like speech synthesizers. In contrast, other languages, including Arabic, have not been considered until recently. Existing Arabic speech synthesis solutions are slow, of low quality, and the naturalness of synthesized speech is inferior to the English synthesizers. They also lack essential speech key factors such as intonation, stress, and rhythm. Different works were proposed to solve those issues, including the use of concatenative methods such as unit selection or parametric methods. However, they required a lot of laborious work and domain expertise. Another reason for such poor performance of Arabic speech synthesizers is the lack of speech corpora, unlike English that has many publicly available corpora and audiobooks. This work describes how to generate high quality, natural, and human-like Arabic speech using an end-to-end neural deep network architecture. This work uses just $\langle$ text, audio $\rangle$ pairs with a relatively small amount of recorded audio samples with a total of 2.41 hours. It illustrates how to use English character embedding despite using diacritic Arabic characters as input and how to preprocess these audio samples to achieve the best results.