 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Character Segmentation Using Projection Based Approach with Profile's Amplitude Filter
Jul 04, 2017

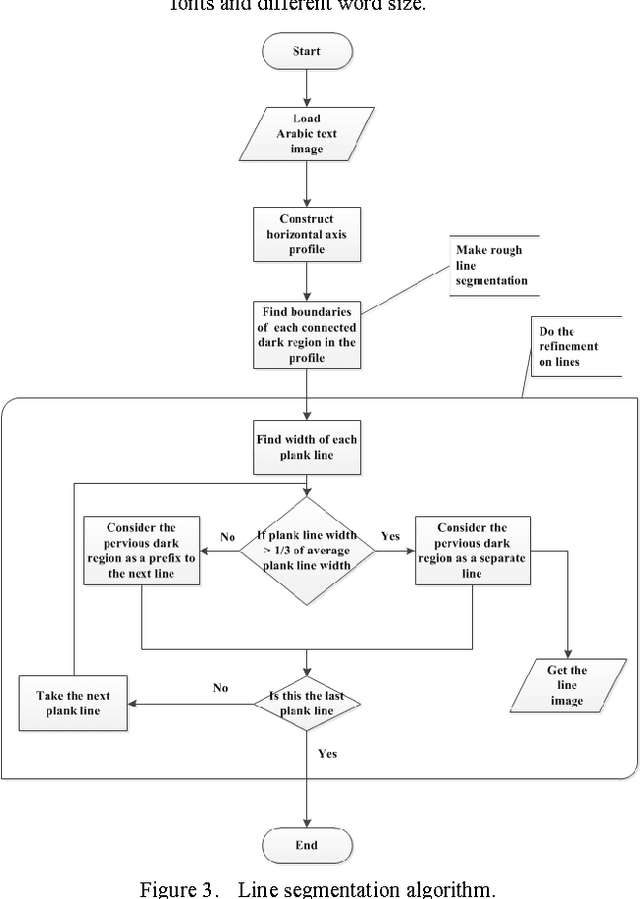

Arabic is one of the languages that present special challenges to Optical character recognition (OCR). The main challenge in Arabic is that it is mostly cursive. Therefore, a segmentation process must be carried out to determine where the character begins and where it ends. This step is essential for character recognition. This paper presents Arabic character segmentation algorithm. The proposed algorithm uses the projection-based approach concepts to separate lines, words, and characters. This is done using profile's amplitude filter and simple edge tool to find characters separations. Our algorithm shows promising performance when applied on different machine printed documents with different Arabic fonts.
Wavelet-Based Mel-Frequency Cepstral Coefficients for Speaker Identification using Hidden Markov Models
Mar 29, 2010
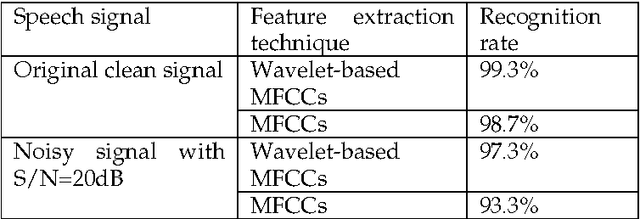
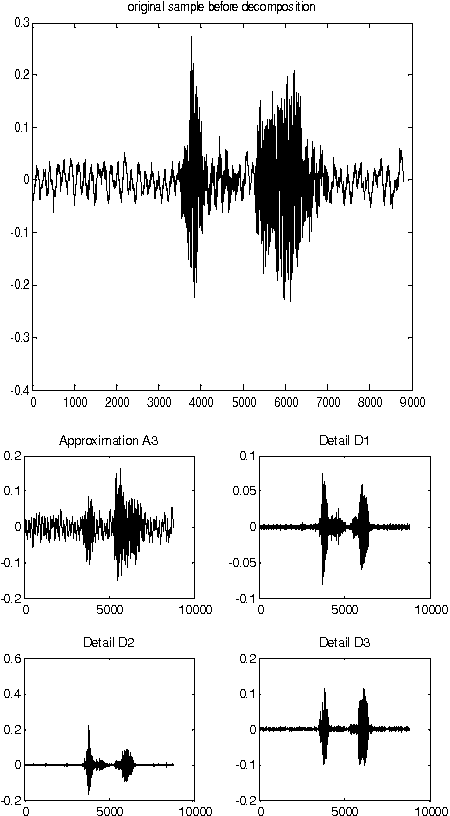
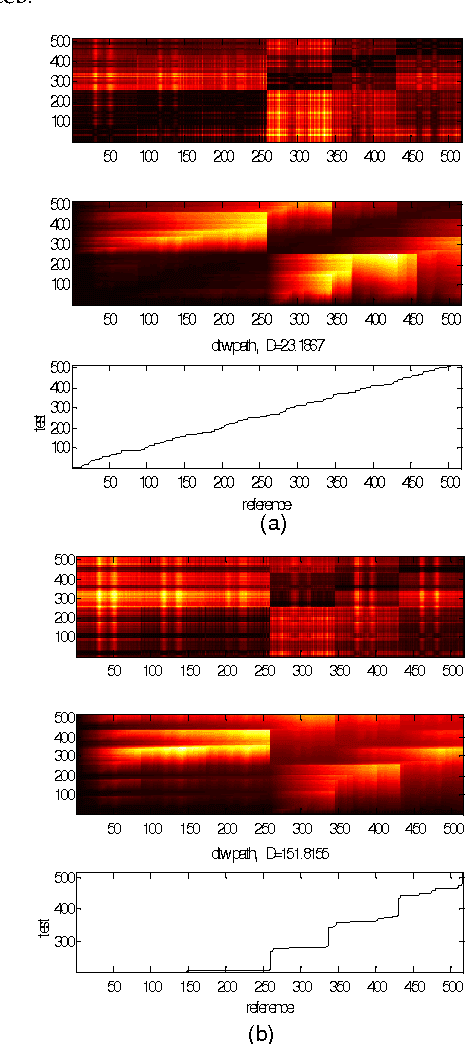
To improve the performance of speaker identification systems, an effective and robust method is proposed to extract speech features, capable of operating in noisy environment. Based on the time-frequency multi-resolution property of wavelet transform, the input speech signal is decomposed into various frequency channels. For capturing the characteristic of the signal, the Mel-Frequency Cepstral Coefficients (MFCCs) of the wavelet channels are calculated. Hidden Markov Models (HMMs) were used for the recognition stage as they give better recognition for the speaker's features than Dynamic Time Warping (DTW). Comparison of the proposed approach with the MFCCs conventional feature extraction method shows that the proposed method not only effectively reduces the influence of noise, but also improves recognition. A recognition rate of 99.3% was obtained using the proposed feature extraction technique compared to 98.7% using the MFCCs. When the test patterns were corrupted by additive white Gaussian noise with 20 dB S/N ratio, the recognition rate was 97.3% using the proposed method compared to 93.3% using the MFCCs.