 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedNLP: A Research Platform for Federated Learning in Natural Language Processing
Apr 18, 2021
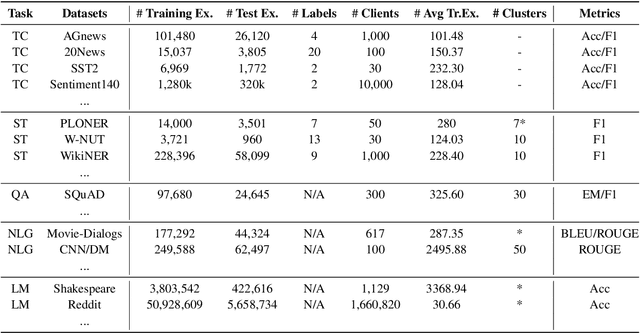
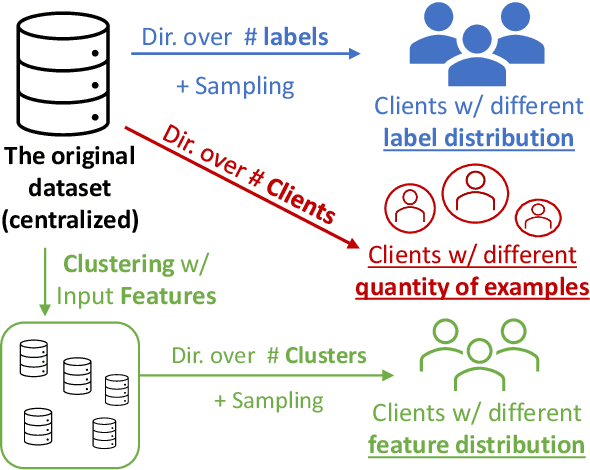
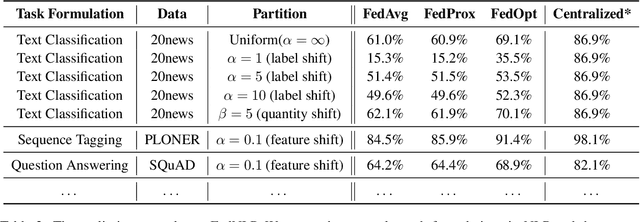
Increasing concerns and regulations about data privacy, necessitate the study of privacy-preserving methods for natural language processing (NLP) applications. Federated learning (FL) provides promising methods for a large number of clients (i.e., personal devices or organizations) to collaboratively learn a shared global model to benefit all clients, while allowing users to keep their data locally. To facilitate FL research in NLP, we present the FedNLP, a research platform for federated learning in NLP. FedNLP supports various popular task formulations in NLP such as text classification, sequence tagging, question answering, seq2seq generation, and language modeling. We also implement an interface between Transformer language models (e.g., BERT) and FL methods (e.g., FedAvg, FedOpt, etc.) for distributed training. The evaluation protocol of this interface supports a comprehensive collection of non-IID partitioning strategies. Our preliminary experiments with FedNLP reveal that there exists a large performance gap between learning on decentralized and centralized datasets -- opening intriguing and exciting future research directions aimed at developing FL methods suited to NLP tasks.
Understanding Overparameterization in Generative Adversarial Networks
Apr 12, 2021
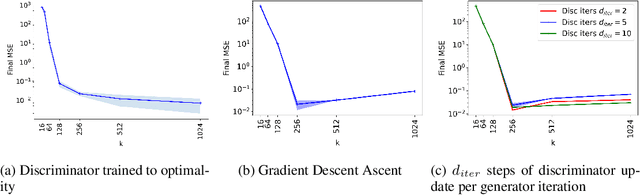
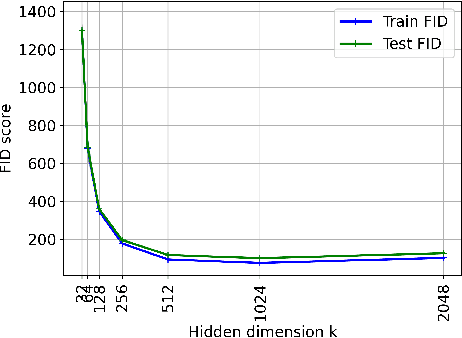
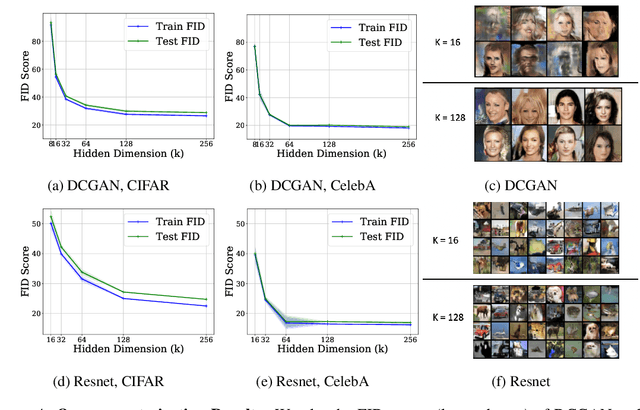
A broad class of unsupervised deep learning methods such as Generative Adversarial Networks (GANs) involve training of overparameterized models where the number of parameters of the model exceeds a certain threshold. A large body of work in supervised learning have shown the importance of model overparameterization in the convergence of the gradient descent (GD) to globally optimal solutions. In contrast, the unsupervised setting and GANs in particular involve non-convex concave mini-max optimization problems that are often trained using Gradient Descent/Ascent (GDA). The role and benefits of model overparameterization in the convergence of GDA to a global saddle point in non-convex concave problems is far less understood. In this work, we present a comprehensive analysis of the importance of model overparameterization in GANs both theoretically and empirically. We theoretically show that in an overparameterized GAN model with a $1$-layer neural network generator and a linear discriminator, GDA converges to a global saddle point of the underlying non-convex concave min-max problem. To the best of our knowledge, this is the first result for global convergence of GDA in such settings. Our theory is based on a more general result that holds for a broader class of nonlinear generators and discriminators that obey certain assumptions (including deeper generators and random feature discriminators). We also empirically study the role of model overparameterization in GANs using several large-scale experiments on CIFAR-10 and Celeb-A datasets. Our experiments show that overparameterization improves the quality of generated samples across various model architectures and datasets. Remarkably, we observe that overparameterization leads to faster and more stable convergence behavior of GDA across the board.
PipeTransformer: Automated Elastic Pipelining for Distributed Training of Transformers
Feb 12, 2021

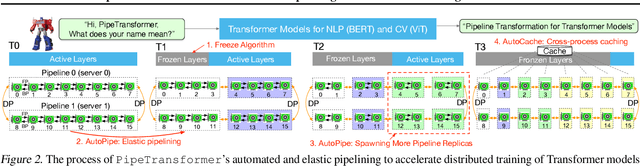
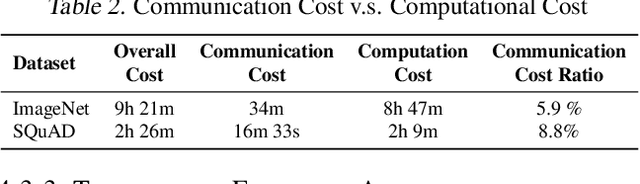
The size of Transformer models is growing at an unprecedented pace. It has only taken less than one year to reach trillion-level parameters after the release of GPT-3 (175B). Training such models requires both substantial engineering efforts and enormous computing resources, which are luxuries most research teams cannot afford. In this paper, we propose PipeTransformer, which leverages automated and elastic pipelining and data parallelism for efficient distributed training of Transformer models. PipeTransformer automatically adjusts the pipelining and data parallelism by identifying and freezing some layers during the training, and instead allocates resources for training of the remaining active layers. More specifically, PipeTransformer dynamically excludes converged layers from the pipeline, packs active layers into fewer GPUs, and forks more replicas to increase data-parallel width. We evaluate PipeTransformer using Vision Transformer (ViT) on ImageNet and BERT on GLUE and SQuAD datasets. Our results show that PipeTransformer attains a 2.4 fold speedup compared to the state-of-the-art baseline. We also provide various performance analyses for a more comprehensive understanding of our algorithmic and system-wise design. We also develop open-sourced flexible APIs for PipeTransformer, which offer a clean separation among the freeze algorithm, model definitions, and training accelerations, hence allowing it to be applied to other algorithms that require similar freezing strategies.
Theoretical Insights Into Multiclass Classification: A High-dimensional Asymptotic View
Nov 16, 2020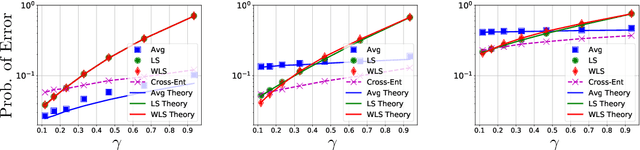
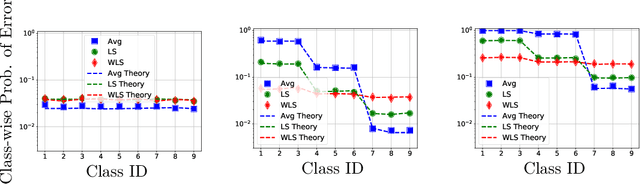
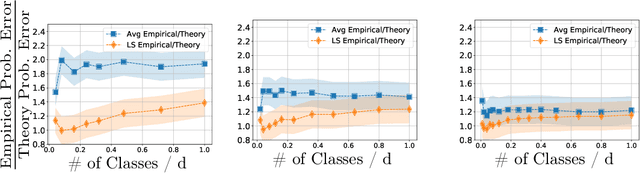
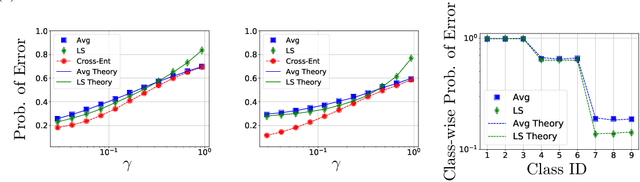
Contemporary machine learning applications often involve classification tasks with many classes. Despite their extensive use, a precise understanding of the statistical properties and behavior of classification algorithms is still missing, especially in modern regimes where the number of classes is rather large. In this paper, we take a step in this direction by providing the first asymptotically precise analysis of linear multiclass classification. Our theoretical analysis allows us to precisely characterize how the test error varies over different training algorithms, data distributions, problem dimensions as well as number of classes, inter/intra class correlations and class priors. Specifically, our analysis reveals that the classification accuracy is highly distribution-dependent with different algorithms achieving optimal performance for different data distributions and/or training/features sizes. Unlike linear regression/binary classification, the test error in multiclass classification relies on intricate functions of the trained model (e.g., correlation between some of the trained weights) whose asymptotic behavior is difficult to characterize. This challenge is already present in simple classifiers, such as those minimizing a square loss. Our novel theoretical techniques allow us to overcome some of these challenges. The insights gained may pave the way for a precise understanding of other classification algorithms beyond those studied in this paper.
Precise Statistical Analysis of Classification Accuracies for Adversarial Training
Oct 21, 2020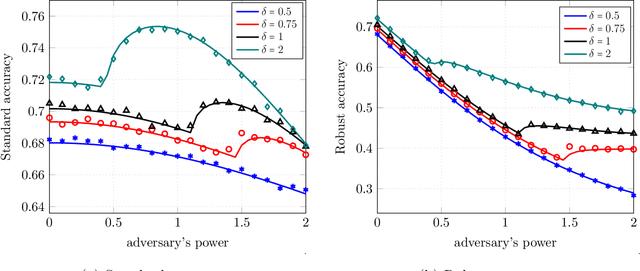
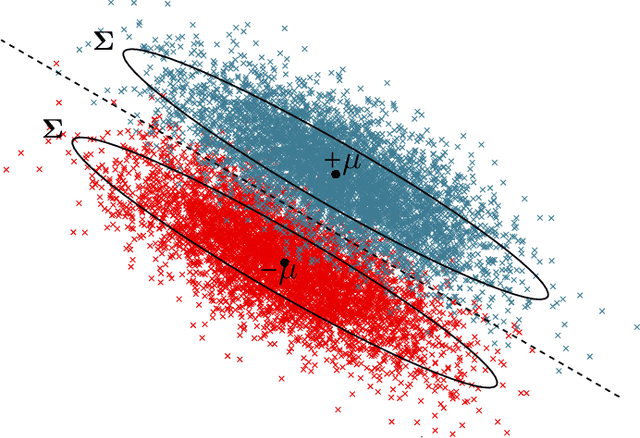
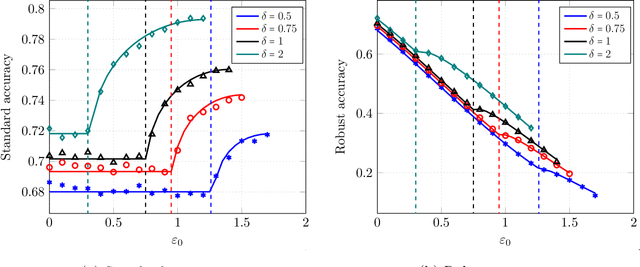
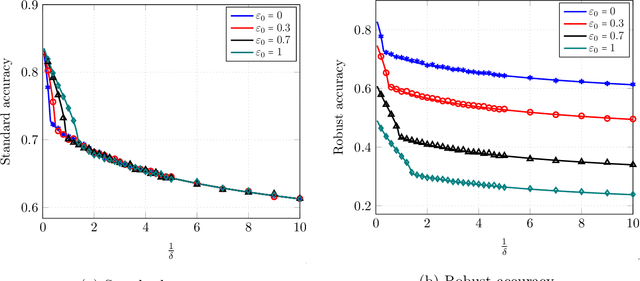
Despite the wide empirical success of modern machine learning algorithms and models in a multitude of applications, they are known to be highly susceptible to seemingly small indiscernible perturbations to the input data known as adversarial attacks. A variety of recent adversarial training procedures have been proposed to remedy this issue. Despite the success of such procedures at increasing accuracy on adversarially perturbed inputs or robust accuracy, these techniques often reduce accuracy on natural unperturbed inputs or standard accuracy. Complicating matters further the effect and trend of adversarial training procedures on standard and robust accuracy is rather counter intuitive and radically dependent on a variety of factors including the perceived form of the perturbation during training, size/quality of data, model overparameterization, etc. In this paper we focus on binary classification problems where the data is generated according to the mixture of two Gaussians with general anisotropic covariance matrices and derive a precise characterization of the standard and robust accuracy for a class of minimax adversarially trained models. We consider a general norm-based adversarial model, where the adversary can add perturbations of bounded $\ell_p$ norm to each input data, for an arbitrary $p\ge 1$. Our comprehensive analysis allows us to theoretically explain several intriguing empirical phenomena and provide a precise understanding of the role of different problem parameters on standard and robust accuracies.
Minimax Lower Bounds for Transfer Learning with Linear and One-hidden Layer Neural Networks
Jun 16, 2020

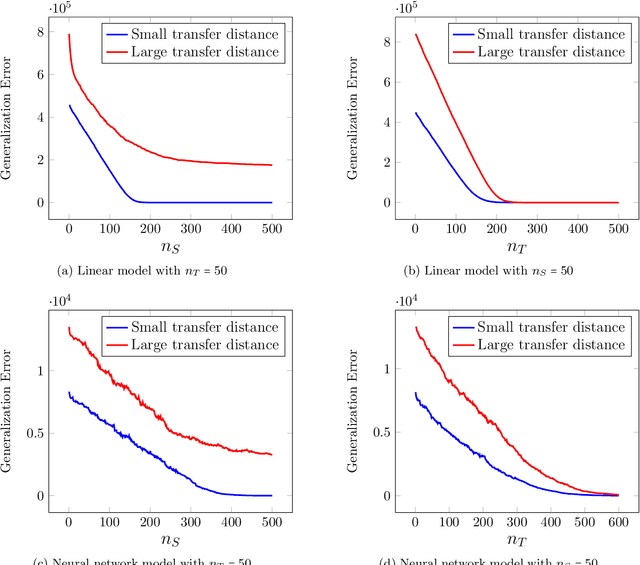
Transfer learning has emerged as a powerful technique for improving the performance of machine learning models on new domains where labeled training data may be scarce. In this approach a model trained for a source task, where plenty of labeled training data is available, is used as a starting point for training a model on a related target task with only few labeled training data. Despite recent empirical success of transfer learning approaches, the benefits and fundamental limits of transfer learning are poorly understood. In this paper we develop a statistical minimax framework to characterize the fundamental limits of transfer learning in the context of regression with linear and one-hidden layer neural network models. Specifically, we derive a lower-bound for the target generalization error achievable by any algorithm as a function of the number of labeled source and target data as well as appropriate notions of similarity between the source and target tasks. Our lower bound provides new insights into the benefits and limitations of transfer learning. We further corroborate our theoretical finding with various experiments.
Approximation Schemes for ReLU Regression
May 26, 2020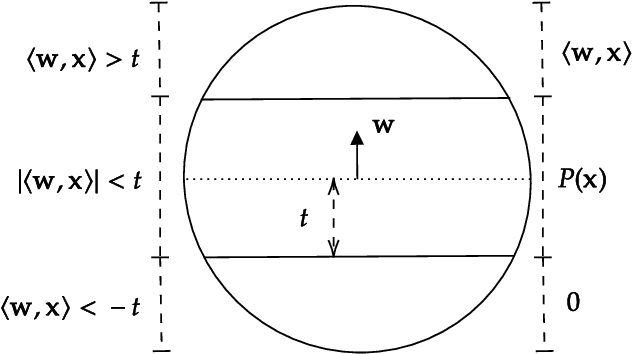
We consider the fundamental problem of ReLU regression, where the goal is to output the best fitting ReLU with respect to square loss given access to draws from some unknown distribution. We give the first efficient, constant-factor approximation algorithm for this problem assuming the underlying distribution satisfies some weak concentration and anti-concentration conditions (and includes, for example, all log-concave distributions). This solves the main open problem of Goel et al., who proved hardness results for any exact algorithm for ReLU regression (up to an additive $\epsilon$). Using more sophisticated techniques, we can improve our results and obtain a polynomial-time approximation scheme for any subgaussian distribution. Given the aforementioned hardness results, these guarantees can not be substantially improved. Our main insight is a new characterization of surrogate losses for nonconvex activations. While prior work had established the existence of convex surrogates for monotone activations, we show that properties of the underlying distribution actually induce strong convexity for the loss, allowing us to relate the global minimum to the activation's Chow parameters.
Compressive sensing with un-trained neural networks: Gradient descent finds the smoothest approximation
May 07, 2020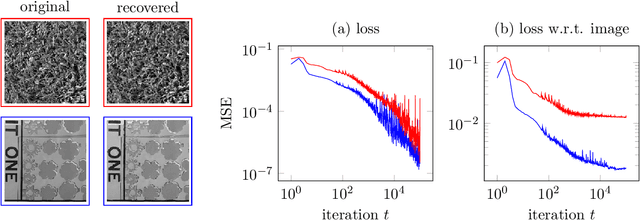
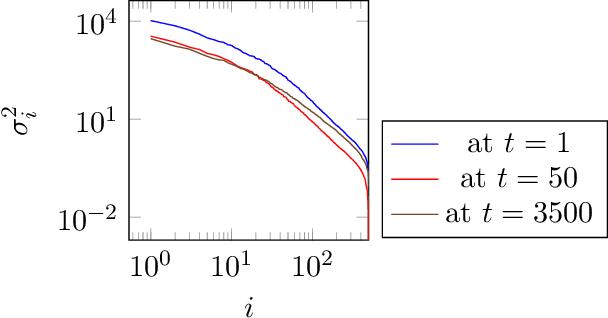
Un-trained convolutional neural networks have emerged as highly successful tools for image recovery and restoration. They are capable of solving standard inverse problems such as denoising and compressive sensing with excellent results by simply fitting a neural network model to measurements from a single image or signal without the need for any additional training data. For some applications, this critically requires additional regularization in the form of early stopping the optimization. For signal recovery from a few measurements, however, un-trained convolutional networks have an intriguing self-regularizing property: Even though the network can perfectly fit any image, the network recovers a natural image from few measurements when trained with gradient descent until convergence. In this paper, we provide numerical evidence for this property and study it theoretically. We show that---without any further regularization---an un-trained convolutional neural network can approximately reconstruct signals and images that are sufficiently structured, from a near minimal number of random measurements.
High-Dimensional Robust Mean Estimation via Gradient Descent
May 04, 2020We study the problem of high-dimensional robust mean estimation in the presence of a constant fraction of adversarial outliers. A recent line of work has provided sophisticated polynomial-time algorithms for this problem with dimension-independent error guarantees for a range of natural distribution families. In this work, we show that a natural non-convex formulation of the problem can be solved directly by gradient descent. Our approach leverages a novel structural lemma, roughly showing that any approximate stationary point of our non-convex objective gives a near-optimal solution to the underlying robust estimation task. Our work establishes an intriguing connection between algorithmic high-dimensional robust statistics and non-convex optimization, which may have broader applications to other robust estimation tasks.
Precise Tradeoffs in Adversarial Training for Linear Regression
Feb 24, 2020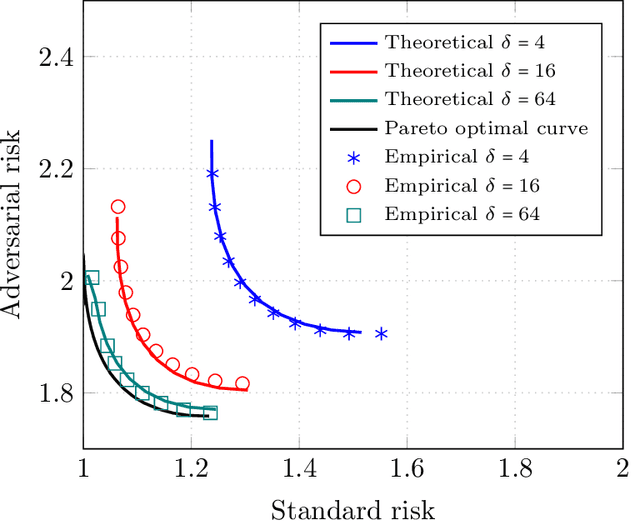
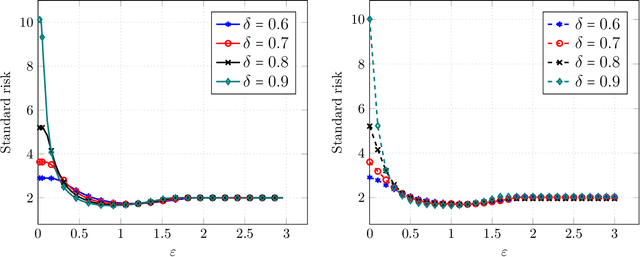
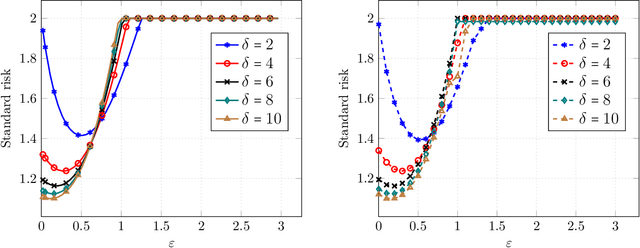
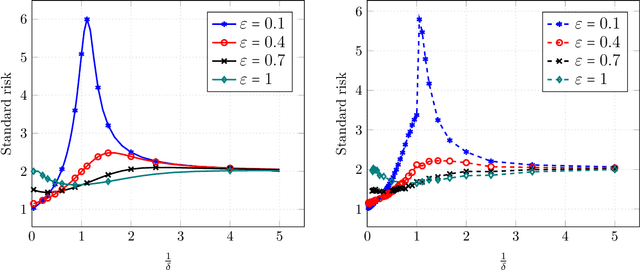
Despite breakthrough performance, modern learning models are known to be highly vulnerable to small adversarial perturbations in their inputs. While a wide variety of recent \emph{adversarial training} methods have been effective at improving robustness to perturbed inputs (robust accuracy), often this benefit is accompanied by a decrease in accuracy on benign inputs (standard accuracy), leading to a tradeoff between often competing objectives. Complicating matters further, recent empirical evidence suggest that a variety of other factors (size and quality of training data, model size, etc.) affect this tradeoff in somewhat surprising ways. In this paper we provide a precise and comprehensive understanding of the role of adversarial training in the context of linear regression with Gaussian features. In particular, we characterize the fundamental tradeoff between the accuracies achievable by any algorithm regardless of computational power or size of the training data. Furthermore, we precisely characterize the standard/robust accuracy and the corresponding tradeoff achieved by a contemporary mini-max adversarial training approach in a high-dimensional regime where the number of data points and the parameters of the model grow in proportion to each other. Our theory for adversarial training algorithms also facilitates the rigorous study of how a variety of factors (size and quality of training data, model overparametrization etc.) affect the tradeoff between these two competing accuracies.