 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Assistant Mold: Modeling Behavioral Variation in LLM Based Procedural Character Generation
Jan 06, 2026Procedural content generation has enabled vast virtual worlds through levels, maps, and quests, but large-scale character generation remains underexplored. We identify two alignment-induced biases in existing methods: a positive moral bias, where characters uniformly adopt agreeable stances (e.g. always saying lying is bad), and a helpful assistant bias, where characters invariably answer questions directly (e.g. never refusing or deflecting). While such tendencies suit instruction-following systems, they suppress dramatic tension and yield predictable characters, stemming from maximum likelihood training and assistant fine-tuning. To address this, we introduce PersonaWeaver, a framework that disentangles world-building (roles, demographics) from behavioral-building (moral stances, interactional styles), yielding characters with more diverse reactions and moral stances, as well as second-order diversity in stylistic markers like length, tone, and punctuation. Code: https://github.com/mqraitem/Persona-Weaver
Web Artifact Attacks Disrupt Vision Language Models
Mar 17, 2025Vision-language models (VLMs) (e.g., CLIP, LLaVA) are trained on large-scale, lightly curated web datasets, leading them to learn unintended correlations between semantic concepts and unrelated visual signals. These associations degrade model accuracy by causing predictions to rely on incidental patterns rather than genuine visual understanding. Prior work has weaponized these correlations as an attack vector to manipulate model predictions, such as inserting a deceiving class text onto the image in a typographic attack. These attacks succeed due to VLMs' text-heavy bias-a result of captions that echo visible words rather than describing content. However, this attack has focused solely on text that matches the target class exactly, overlooking a broader range of correlations, including non-matching text and graphical symbols, which arise from the abundance of branding content in web-scale data. To address this gap, we introduce artifact-based attacks: a novel class of manipulations that mislead models using both non-matching text and graphical elements. Unlike typographic attacks, these artifacts are not predefined, making them harder to defend against but also more challenging to find. We address this by framing artifact attacks as a search problem and demonstrate their effectiveness across five datasets, with some artifacts reinforcing each other to reach 100% attack success rates. These attacks transfer across models with up to 90% effectiveness, making it possible to attack unseen models. To defend against these attacks, we extend prior work's artifact aware prompting to the graphical setting. We see a moderate reduction of success rates of up to 15% relative to standard prompts, suggesting a promising direction for enhancing model robustness.
KiVA: Kid-inspired Visual Analogies for Testing Large Multimodal Models
Jul 25, 2024



This paper investigates visual analogical reasoning in large multimodal models (LMMs) compared to human adults and children. A "visual analogy" is an abstract rule inferred from one image and applied to another. While benchmarks exist for testing visual reasoning in LMMs, they require advanced skills and omit basic visual analogies that even young children can make. Inspired by developmental psychology, we propose a new benchmark of 1,400 visual transformations of everyday objects to test LMMs on visual analogical reasoning and compare them to children and adults. We structure the evaluation into three stages: identifying what changed (e.g., color, number, etc.), how it changed (e.g., added one object), and applying the rule to new scenarios. Our findings show that while models like GPT-4V, LLaVA-1.5, and MANTIS identify the "what" effectively, they struggle with quantifying the "how" and extrapolating this rule to new objects. In contrast, children and adults exhibit much stronger analogical reasoning at all three stages. Additionally, the strongest tested model, GPT-4V, performs better in tasks involving simple visual attributes like color and size, correlating with quicker human adult response times. Conversely, more complex tasks such as number, rotation, and reflection, which necessitate extensive cognitive processing and understanding of the 3D physical world, present more significant challenges. Altogether, these findings highlight the limitations of training models on data that primarily consists of 2D images and text.
SLANT: Spurious Logo ANalysis Toolkit
Jun 03, 2024



Online content is filled with logos, from ads and social media posts to website branding and product placements. Consequently, these logos are prevalent in the extensive web-scraped datasets used to pretrain Vision-Language Models, which are used for a wide array of tasks (content moderation, object classification). While these models have been shown to learn harmful correlations in various tasks, whether these correlations include logos remains understudied. Understanding this is especially important due to logos often being used by public-facing entities like brands and government agencies. To that end, we develop SLANT: A Spurious Logo ANalysis Toolkit. Our key finding is that some logos indeed lead to spurious incorrect predictions, for example, adding the Adidas logo to a photo of a person causes a model classify the person as greedy. SLANT contains a semi-automatic mechanism for mining such "spurious" logos. The mechanism consists of a comprehensive logo bank, CC12M-LogoBank, and an algorithm that searches the bank for logos that VLMs spuriously correlate with a user-provided downstream recognition target. We uncover various seemingly harmless logos that VL models correlate 1) with negative human adjectives 2) with the concept of `harmlessness'; causing models to misclassify harmful online content as harmless, and 3) with user-provided object concepts; causing lower recognition accuracy on ImageNet zero-shot classification. Furthermore, SLANT's logos can be seen as effective attacks against foundational models; an attacker could place a spurious logo on harmful content, causing the model to misclassify it as harmless. This threat is alarming considering the simplicity of logo attacks, increasing the attack surface of VL models. As a defense, we include in our Toolkit two effective mitigation strategies that seamlessly integrate with zero-shot inference of foundation models.
Vision-LLMs Can Fool Themselves with Self-Generated Typographic Attacks
Feb 01, 2024


Recently, significant progress has been made on Large Vision-Language Models (LVLMs); a new class of VL models that make use of large pre-trained language models. Yet, their vulnerability to Typographic attacks, which involve superimposing misleading text onto an image remain unstudied. Furthermore, prior work typographic attacks rely on sampling a random misleading class from a predefined set of classes. However, the random chosen class might not be the most effective attack. To address these issues, we first introduce a novel benchmark uniquely designed to test LVLMs vulnerability to typographic attacks. Furthermore, we introduce a new and more effective typographic attack: Self-Generated typographic attacks. Indeed, our method, given an image, make use of the strong language capabilities of models like GPT-4V by simply prompting them to recommend a typographic attack. Using our novel benchmark, we uncover that typographic attacks represent a significant threat against LVLM(s). Furthermore, we uncover that typographic attacks recommended by GPT-4V using our new method are not only more effective against GPT-4V itself compared to prior work attacks, but also against a host of less capable yet popular open source models like LLaVA, InstructBLIP, and MiniGPT4.
From Fake to Real : A two-stage training pipeline for mitigating spurious correlations with synthetic data
Aug 08, 2023Visual recognition models are prone to learning spurious correlations induced by an imbalanced training set where certain groups (\eg Females) are under-represented in certain classes (\eg Programmers). Generative models offer a promising direction in mitigating this bias by generating synthetic data for the minority samples and thus balancing the training set. However, prior work that uses these approaches overlooks that visual recognition models could often learn to differentiate between real and synthetic images and thus fail to unlearn the bias in the original dataset. In our work, we propose a novel two-stage pipeline to mitigate this issue where 1) we pre-train a model on a balanced synthetic dataset and then 2) fine-tune on the real data. Using this pipeline, we avoid training on both real and synthetic data, thus avoiding the bias between real and synthetic data. Moreover, we learn robust features against the bias in the first step that mitigate the bias in the second step. Moreover, our pipeline naturally integrates with bias mitigation methods; they can be simply applied to the fine-tuning step. As our experiments prove, our pipeline can further improve the performance of bias mitigation methods obtaining state-of-the-art performance on three large-scale datasets.
Bias Mimicking: A Simple Sampling Approach for Bias Mitigation
Oct 03, 2022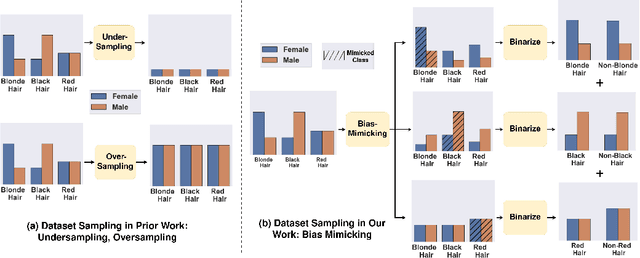

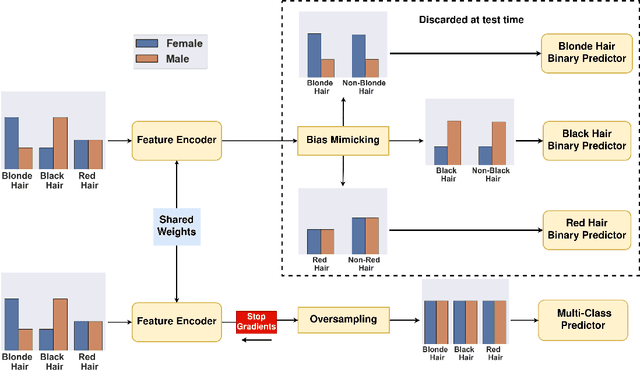

Prior work has shown that Visual Recognition datasets frequently under-represent sensitive groups (\eg Female) within a category (\eg Programmers). This dataset bias can lead to models that learn spurious correlations between class labels and sensitive attributes such as age, gender, or race. Most of the recent methods that address this problem require significant architectural changes or expensive hyper-parameter tuning. Alternatively, data re-sampling baselines from the class imbalance literature (\eg Undersampling, Upweighting), which can often be implemented in a single line of code and often have no hyperparameters, offer a cheaper and more efficient solution. However, we found that some of these baselines were missing from recent bias mitigation benchmarks. In this paper, we show that these simple methods are strikingly competitive with state-of-the-art bias mitigation methods on many datasets. Furthermore, we improve these methods by introducing a new class conditioned sampling method: Bias Mimicking. In cases where the baseline dataset re-sampling methods do not perform well, Bias Mimicking effectively bridges the performance gap and improves the total averaged accuracy of under-represented subgroups by over $3\%$ compared to prior work.
Learning to Reason from General Concepts to Fine-grained Tokens for Discriminative Phrase Detection
Dec 06, 2021



Phrase detection requires methods to identify if a phrase is relevant to an image and then localize it if applicable. A key challenge in training more discriminative phrase detection models is sampling hard-negatives. This is because few phrases are annotated of the nearly infinite variations that may be applicable. To address this problem, we introduce PFP-Net, a phrase detector that differentiates between phrases through two novel methods. First, we group together phrases of related objects into coarse groups of visually coherent concepts (eg animals vs automobiles), and then train our PFP-Net to discriminate between them according to their concept membership. Second, for phrases containing fine grained mutually-exclusive tokens (eg colors), we force the model into selecting only one applicable phrase for each region. We evaluate our approach on the Flickr30K Entities and RefCOCO+ datasets, where we improve mAP over the state-of-the-art by 1-1.5 points over all phrases on this challenging task. When considering only the phrases affected by our fine-grained reasoning module, we improve by 1-4 points on both datasets.
Bridging the Gap: Machine Learning to Resolve Improperly Modeled Dynamics
Aug 23, 2020
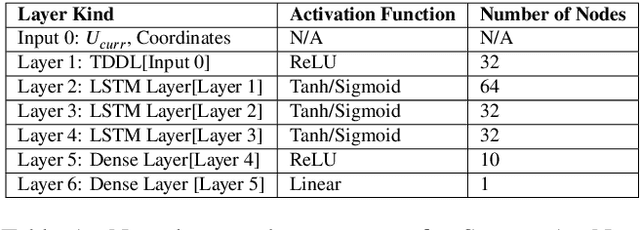

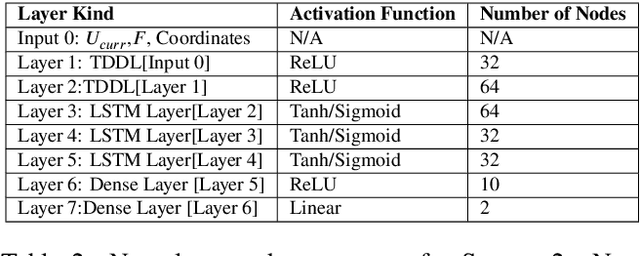
We present a data-driven modeling strategy to overcome improperly modeled dynamics for systems exhibiting complex spatio-temporal behaviors. We propose a Deep Learning framework to resolve the differences between the true dynamics of the system and the dynamics given by a model of the system that is either inaccurately or inadequately described. Our machine learning strategy leverages data generated from the improper system model and observational data from the actual system to create a neural network to model the dynamics of the actual system. We evaluate the proposed framework using numerical solutions obtained from three increasingly complex dynamical systems. Our results show that our system is capable of learning a data-driven model that provides accurate estimates of the system states both in previously unobserved regions as well as for future states. Our results show the power of state-of-the-art machine learning frameworks in estimating an accurate prior of the system's true dynamics that can be used for prediction up to a finite horizon.