 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotic Theory for Graphical SLOPE: Precision Estimation and Pattern Convergence
Apr 14, 2026This paper studies Graphical SLOPE for precision matrix estimation, with emphasis on its ability to recover both sparsity and clusters of edges with equal or similar strength. In a fixed-dimensional regime, we establish that the root-$n$ scaled estimation error converges to the unique minimizer of a strictly convex optimization problem defined through the directional derivative of the SLOPE penalty. We also establish convergence of the induced SLOPE pattern, thereby obtaining an asymptotic characterization of the clustering structure selected by the estimator. A comparison with GLASSO shows that the grouping property of SLOPE can substantially improve estimation accuracy when the precision matrix exhibits structured edge patterns. To assess the effect of departures from Gaussianity, we then analyze Gaussian-loss precision matrix estimation under elliptical distributions. In this setting, we derive the limiting distribution and quantify the inflation in variability induced by heavy tails relative to the Gaussian benchmark. We also study TSLOPE, based on the multivariate $t$-loss, and derive its limiting distribution. The results show that TSLOPE offers clear advantages over GSLOPE under heavy-tailed data-generating mechanisms. Simulation evidence suggests that these qualitative conclusions persist in high-dimensional settings, and an empirical application shows that SLOPE-based estimators, especially TSLOPE, can uncover economically meaningful clustered dependence structures.
The Strong Screening Rule for SLOPE
May 07, 2020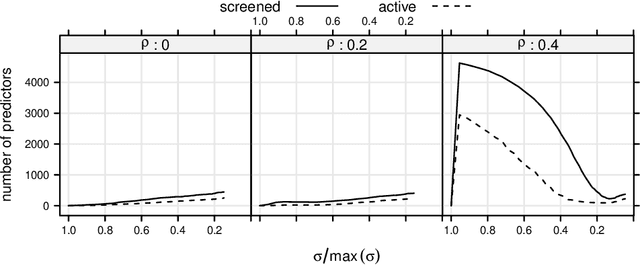
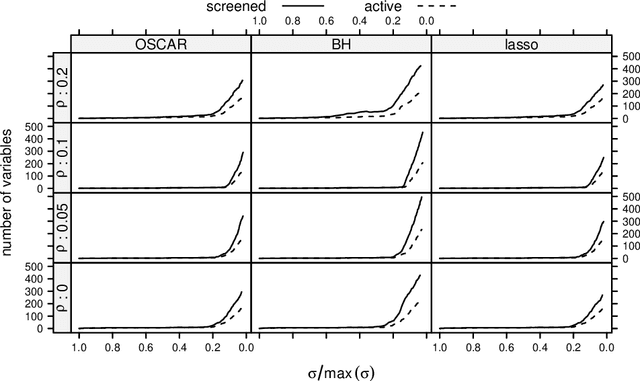
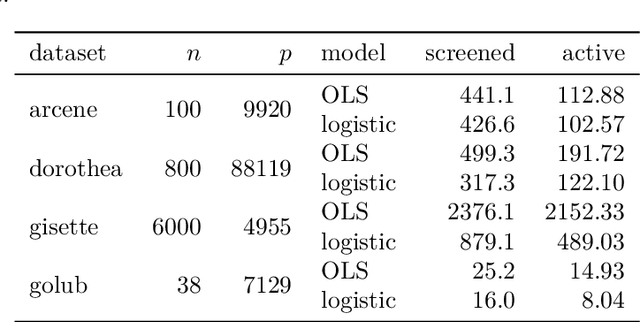
Extracting relevant features from data sets where the number of observations ($n$) is much smaller then the number of predictors ($p$) is a major challenge in modern statistics. Sorted L-One Penalized Estimation (SLOPE), a generalization of the lasso, is a promising method within this setting. Current numerical procedures for SLOPE, however, lack the efficiency that respective tools for the lasso enjoy, particularly in the context of estimating a complete regularization path. A key component in the efficiency of the lasso is predictor screening rules: rules that allow predictors to be discarded before estimating the model. This is the first paper to establish such a rule for SLOPE. We develop a screening rule for SLOPE by examining its subdifferential and show that this rule is a generalization of the strong rule for the lasso. Our rule is heuristic, which means that it may discard predictors erroneously. We present conditions under which this may happen and show that such situations are rare and easily safeguarded against by a simple check of the optimality conditions. Our numerical experiments show that the rule performs well in practice, leading to improvements by orders of magnitude for data in the $p \gg n$ domain, as well as incurring no additional computational overhead when $n \gg p$. We also examine the effect of correlation structures in the design matrix on the rule and discuss algorithmic strategies for employing the rule. Finally, we provide an efficient implementation of the rule in our R package SLOPE.