 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Classical-Quantum architecture for vectorised image classification of hand-written sketches
Jul 08, 2024



Quantum machine learning (QML) investigates how quantum phenomena can be exploited in order to learn data in an alternative way, \textit{e.g.} by means of a quantum computer. While recent results evidence that QML models can potentially surpass their classical counterparts' performance in specific tasks, quantum technology hardware is still unready to reach quantum advantage in tasks of significant relevance to the broad scope of the computer science community. Recent advances indicate that hybrid classical-quantum models can readily attain competitive performances at low architecture complexities. Such investigations are often carried out for image-processing tasks, and are notably constrained to modelling \textit{raster images}, represented as a grid of two-dimensional pixels. Here, we introduce vector-based representation of sketch drawings as a test-bed for QML models. Such a lower-dimensional data structure results handful to benchmark model's performance, particularly in current transition times, where classical simulations of quantum circuits are naturally limited in the number of qubits, and quantum hardware is not readily available to perform large-scale experiments. We report some encouraging results for primitive hybrid classical-quantum architectures, in a canonical sketch recognition problem.
Automatic re-calibration of quantum devices by reinforcement learning
Apr 16, 2024During their operation, due to shifts in environmental conditions, devices undergo various forms of detuning from their optimal settings. Typically, this is addressed through control loops, which monitor variables and the device performance, to maintain settings at their optimal values. Quantum devices are particularly challenging since their functionality relies on precisely tuning their parameters. At the same time, the detailed modeling of the environmental behavior is often computationally unaffordable, while a direct measure of the parameters defining the system state is costly and introduces extra noise in the mechanism. In this study, we investigate the application of reinforcement learning techniques to develop a model-free control loop for continuous recalibration of quantum device parameters. Furthermore, we explore the advantages of incorporating minimal environmental noise models. As an example, the application to numerical simulations of a Kennedy receiver-based long-distance quantum communication protocol is presented.
A semi-agnostic ansatz with variable structure for quantum machine learning
Mar 11, 2021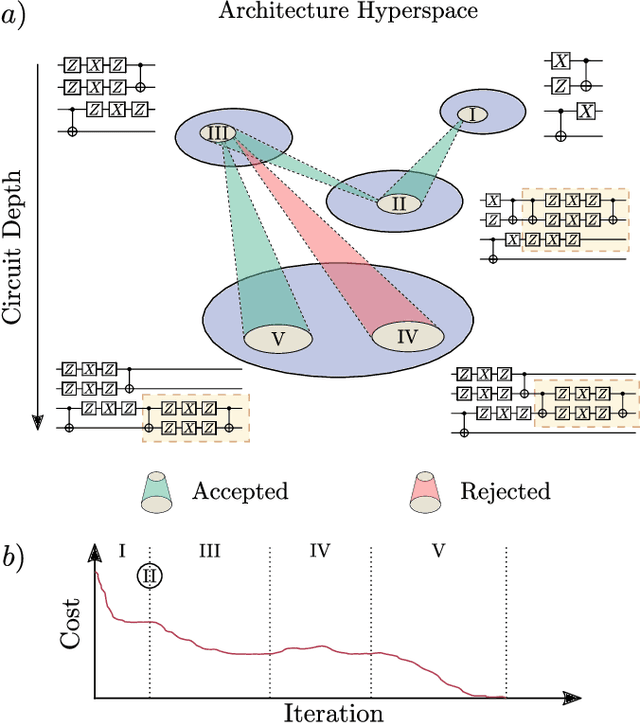
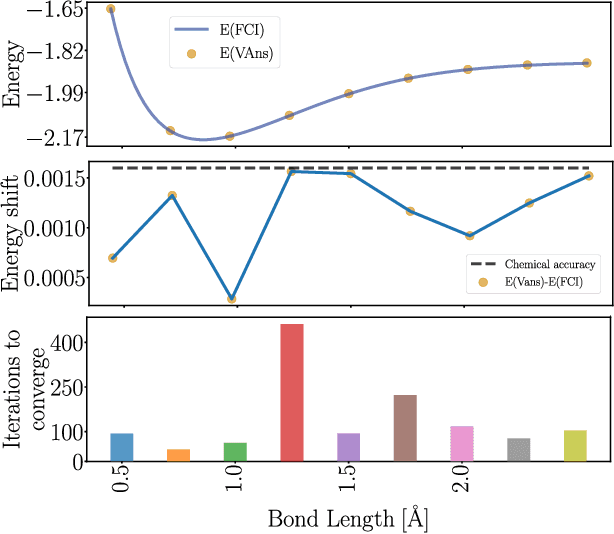
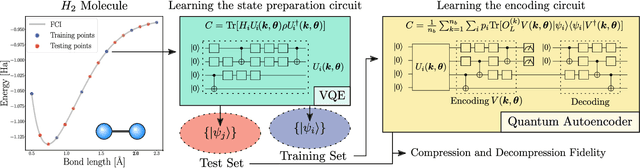
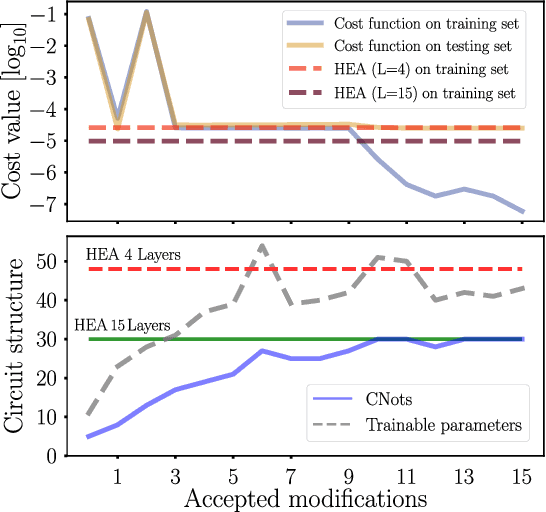
Quantum machine learning (QML) offers a powerful, flexible paradigm for programming near-term quantum computers, with applications in chemistry, metrology, materials science, data science, and mathematics. Here, one trains an ansatz, in the form of a parameterized quantum circuit, to accomplish a task of interest. However, challenges have recently emerged suggesting that deep ansatzes are difficult to train, due to flat training landscapes caused by randomness or by hardware noise. This motivates our work, where we present a variable structure approach to build ansatzes for QML. Our approach, called VAns (Variable Ansatz), applies a set of rules to both grow and (crucially) remove quantum gates in an informed manner during the optimization. Consequently, VAns is ideally suited to mitigate trainability and noise-related issues by keeping the ansatz shallow. We employ VAns in the variational quantum eigensolver for condensed matter and quantum chemistry applications and also in the quantum autoencoder for data compression, showing successful results in all cases.
Real-time calibration of coherent-state receivers: learning by trial and error
Jan 28, 2020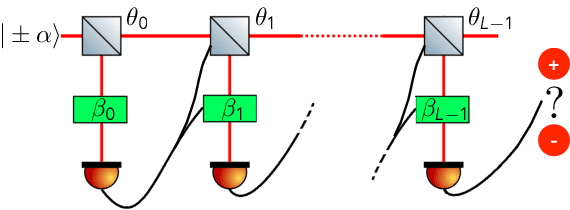
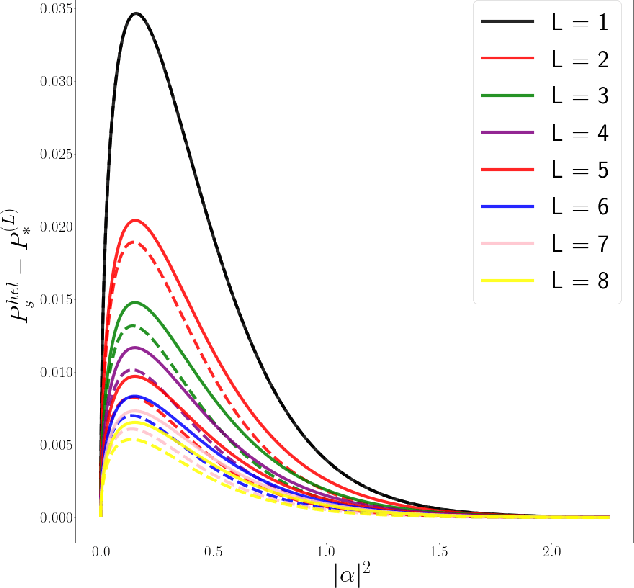
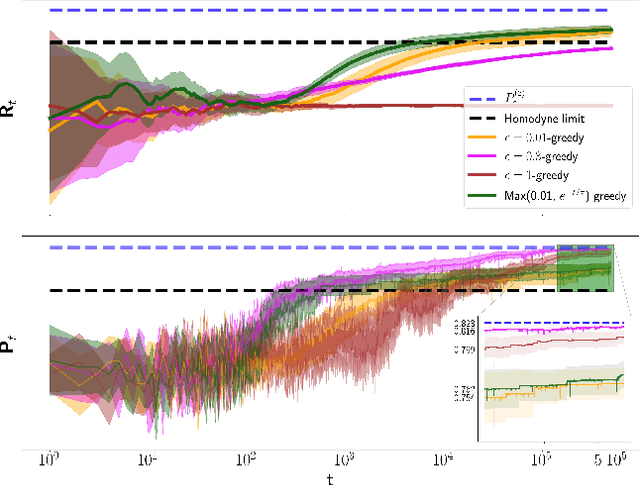
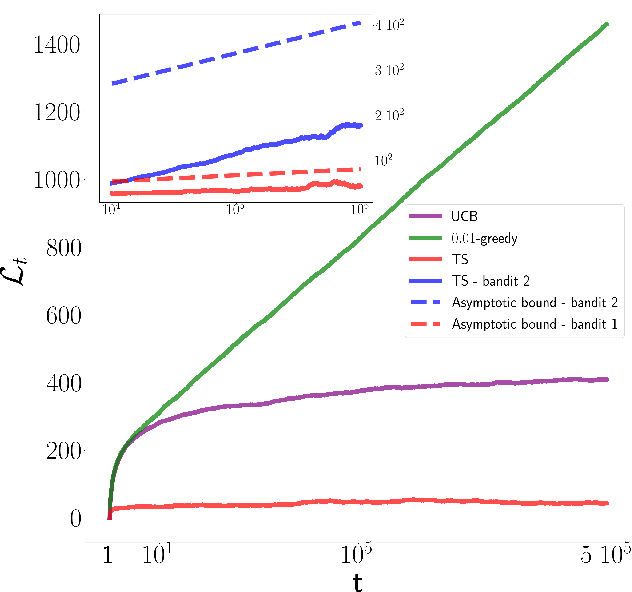
The optimal discrimination of coherent states of light with current technology is a key problem in classical and quantum communication, whose solution would enable the realization of efficient receivers for long-distance communications in free-space and optical fiber channels. In this article, we show that reinforcement learning (RL) protocols allow an agent to learn near-optimal coherent-state receivers made of passive linear optics, photodetectors and classical adaptive control. Each agent is trained and tested in real time over several runs of independent discrimination experiments and has no knowledge about the energy of the states nor the receiver setup nor the quantum-mechanical laws governing the experiments. Based exclusively on the observed photodetector outcomes, the agent adaptively chooses among a set of ~3 10^3 possible receiver setups, and obtains a reward at the end of each experiment if its guess is correct. At variance with previous applications of RL in quantum physics, the information gathered in each run is intrinsically stochastic and thus insufficient to evaluate exactly the performance of the chosen receiver. Nevertheless, we present families of agents that: (i) discover a receiver beating the best Gaussian receiver after ~3 10^2 experiments; (ii) surpass the cumulative reward of the best Gaussian receiver after ~10^3 experiments; (iii) simultaneously discover a near-optimal receiver and attain its cumulative reward after ~10^5 experiments. Our results show that RL techniques are suitable for on-line control of quantum receivers and can be employed for long-distance communications over potentially unknown channels.