 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Temporal Embedding of Objects in Video Data
Aug 23, 2024In video analysis, understanding the temporal context is crucial for recognizing object interactions, event patterns, and contextual changes over time. The proposed model leverages adjacency and semantic similarities between objects from neighboring video frames to construct context-aware temporal object embeddings. Unlike traditional methods that rely solely on visual appearance, our temporal embedding model considers the contextual relationships between objects, creating a meaningful embedding space where temporally connected object's vectors are positioned in proximity. Empirical studies demonstrate that our context-aware temporal embeddings can be used in conjunction with conventional visual embeddings to enhance the effectiveness of downstream applications. Moreover, the embeddings can be used to narrate a video using a Large Language Model (LLM). This paper describes the intricate details of the proposed objective function to generate context-aware temporal object embeddings for video data and showcases the potential applications of the generated embeddings in video analysis and object classification tasks.
Tracking the Evolution of Words with Time-reflective Text Representations
Jul 12, 2018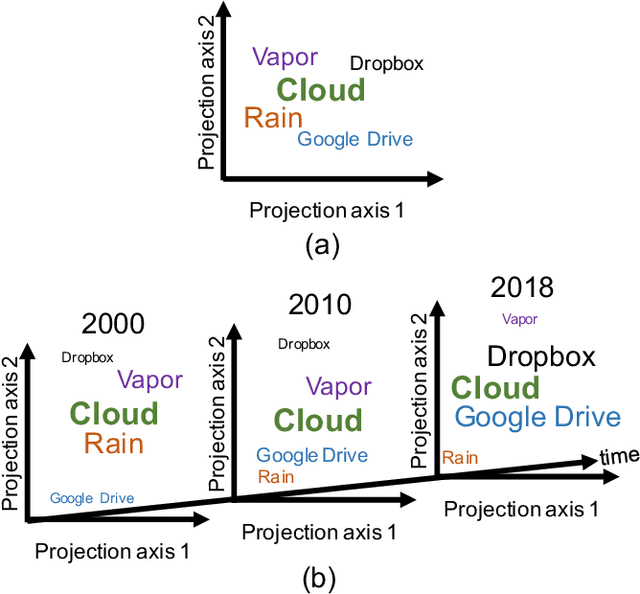
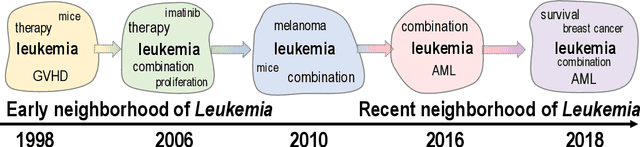
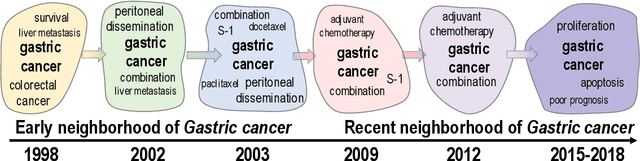
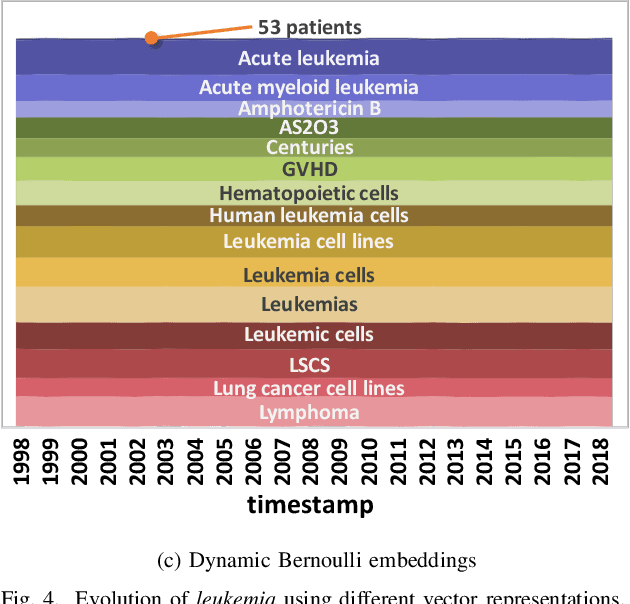
More than 80% of today's data is unstructured in nature, and these unstructured datasets evolving over time. A large part of the evolving unstructured data are text documents generated by media outlets, scholarly articles in digital libraries, and social media. Vector space models have been developed to analyze text documents using data mining and machine learning algorithms. While ample vector space models exist for text data, the evolution aspect of evolving text corpora is still missing in vector-based representations. The advent of word embeddings has given a way to create a contextual vector space, but the embeddings do not consider the temporal aspects of the feature space successfully yet. The inclusion of the time aspect in the feature space will provide vectors for every natural language element, such as words or entities, at every timestamp. Such temporal word vectors will provide the ability to track how the meaning of a word changes over time, in terms of the changes in its neighborhood. Moreover, a time-reflective text representation will pave the way to a new set of text analytic abilities involving time series for text collections. In this paper, we present the potential benefits of a time-reflective vector space model for temporal text data that is able to capture short and long-term changes in the meaning of words. We compare our approach with the limited literature on dynamic embeddings. We present qualitative and quantitative evaluations using semantic evolution tracking as the target application.
Is a Picture Worth Ten Thousand Words in a Review Dataset?
Jun 23, 2016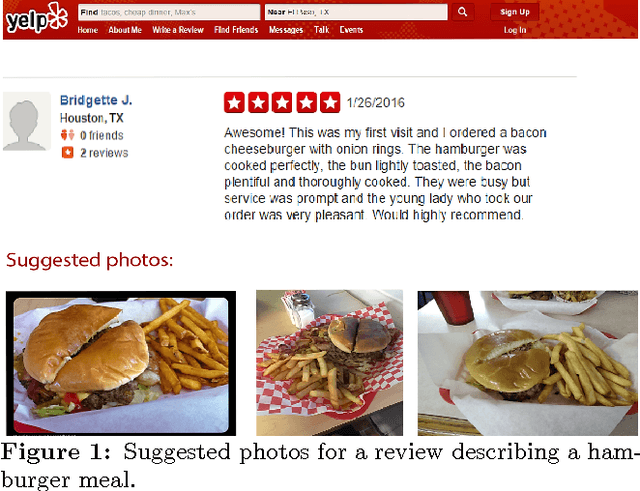
While textual reviews have become prominent in many recommendation-based systems, automated frameworks to provide relevant visual cues against text reviews where pictures are not available is a new form of task confronted by data mining and machine learning researchers. Suggestions of pictures that are relevant to the content of a review could significantly benefit the users by increasing the effectiveness of a review. We propose a deep learning-based framework to automatically: (1) tag the images available in a review dataset, (2) generate a caption for each image that does not have one, and (3) enhance each review by recommending relevant images that might not be uploaded by the corresponding reviewer. We evaluate the proposed framework using the Yelp Challenge Dataset. While a subset of the images in this particular dataset are correctly captioned, the majority of the pictures do not have any associated text. Moreover, there is no mapping between reviews and images. Each image has a corresponding business-tag where the picture was taken, though. The overall data setting and unavailability of crucial pieces required for a mapping make the problem of recommending images for reviews a major challenge. Qualitative and quantitative evaluations indicate that our proposed framework provides high quality enhancements through automatic captioning, tagging, and recommendation for mapping reviews and images.
Efficiently Discovering Hammock Paths from Induced Similarity Networks
Feb 17, 2010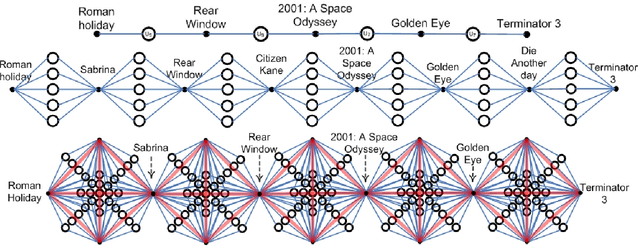
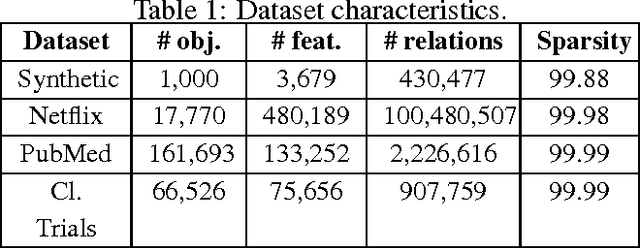
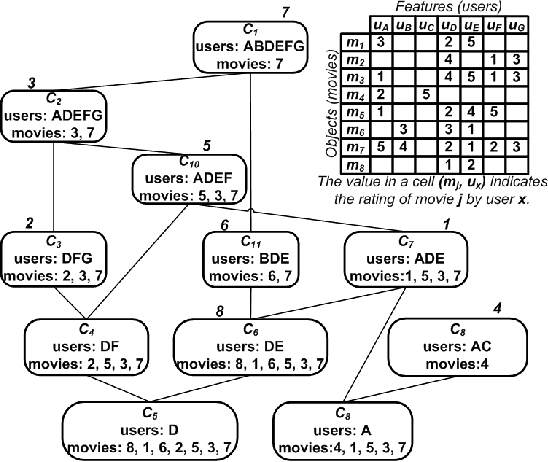

Similarity networks are important abstractions in many information management applications such as recommender systems, corpora analysis, and medical informatics. For instance, by inducing similarity networks between movies rated similarly by users, or between documents containing common terms, and or between clinical trials involving the same themes, we can aim to find the global structure of connectivities underlying the data, and use the network as a basis to make connections between seemingly disparate entities. In the above applications, composing similarities between objects of interest finds uses in serendipitous recommendation, in storytelling, and in clinical diagnosis, respectively. We present an algorithmic framework for traversing similarity paths using the notion of `hammock' paths which are generalization of traditional paths. Our framework is exploratory in nature so that, given starting and ending objects of interest, it explores candidate objects for path following, and heuristics to admissibly estimate the potential for paths to lead to a desired destination. We present three diverse applications: exploring movie similarities in the Netflix dataset, exploring abstract similarities across the PubMed corpus, and exploring description similarities in a database of clinical trials. Experimental results demonstrate the potential of our approach for unstructured knowledge discovery in similarity networks.