 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Successor Representation for Robust Transfer
Feb 13, 2026The successor representation (SR) provides a powerful framework for decoupling predictive dynamics from rewards, enabling rapid generalisation across reward configurations. However, the classical SR is limited by its inherent policy dependence: policies change due to ongoing learning, environmental non-stationarities, and changes in task demands, making established predictive representations obsolete. Furthermore, in topologically complex environments, SRs suffer from spectral diffusion, leading to dense and overlapping features that scale poorly. Here we propose the Hierarchical Successor Representation (HSR) for overcoming these limitations. By incorporating temporal abstractions into the construction of predictive representations, HSR learns stable state features which are robust to task-induced policy changes. Applying non-negative matrix factorisation (NMF) to the HSR yields a sparse, low-rank state representation that facilitates highly sample-efficient transfer to novel tasks in multi-compartmental environments. Further analysis reveals that HSR-NMF discovers interpretable topological structures, providing a policy-agnostic hierarchical map that effectively bridges model-free optimality and model-based flexibility. Beyond providing a useful basis for task-transfer, we show that HSR's temporally extended predictive structure can also be leveraged to drive efficient exploration, effectively scaling to large, procedurally generated environments.
A flexible Bayesian non-parametric mixture model reveals multiple dependencies of swap errors in visual working memory
May 02, 2025Human behavioural data in psychophysics has been used to elucidate the underlying mechanisms of many cognitive processes, such as attention, sensorimotor integration, and perceptual decision making. Visual working memory has particularly benefited from this approach: analyses of VWM errors have proven crucial for understanding VWM capacity and coding schemes, in turn constraining neural models of both. One poorly understood class of VWM errors are swap errors, whereby participants recall an uncued item from memory. Swap errors could arise from erroneous memory encoding, noisy storage, or errors at retrieval time - previous research has mostly implicated the latter two. However, these studies made strong a priori assumptions on the detailed mechanisms and/or parametric form of errors contributed by these sources. Here, we pursue a data-driven approach instead, introducing a Bayesian non-parametric mixture model of swap errors (BNS) which provides a flexible descriptive model of swapping behaviour, such that swaps are allowed to depend on both the probed and reported features of every stimulus item. We fit BNS to the trial-by-trial behaviour of human participants and show that it recapitulates the strong dependence of swaps on cue similarity in multiple datasets. Critically, BNS reveals that this dependence coexists with a non-monotonic modulation in the report feature dimension for a random dot motion direction-cued, location-reported dataset. The form of the modulation inferred by BNS opens new questions about the importance of memory encoding in causing swap errors in VWM, a distinct source to the previously suggested binding and cueing errors. Our analyses, combining qualitative comparisons of the highly interpretable BNS parameter structure with rigorous quantitative model comparison and recovery methods, show that previous interpretations of swap errors may have been incomplete.
Bayesian Active Learning for Classification and Preference Learning
Dec 24, 2011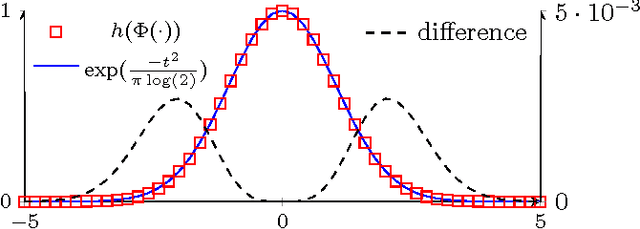
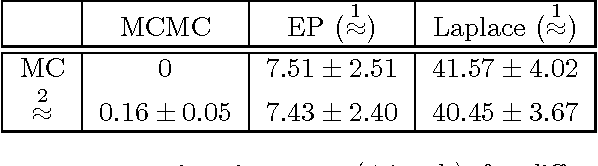
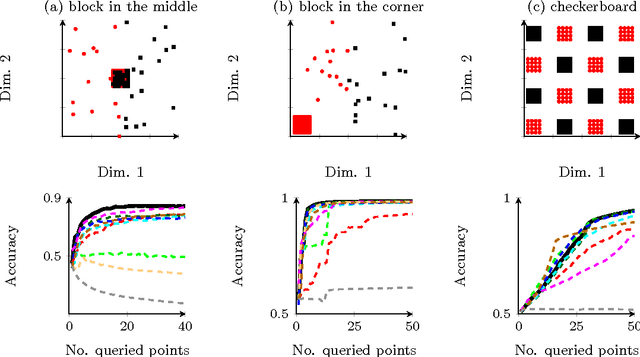
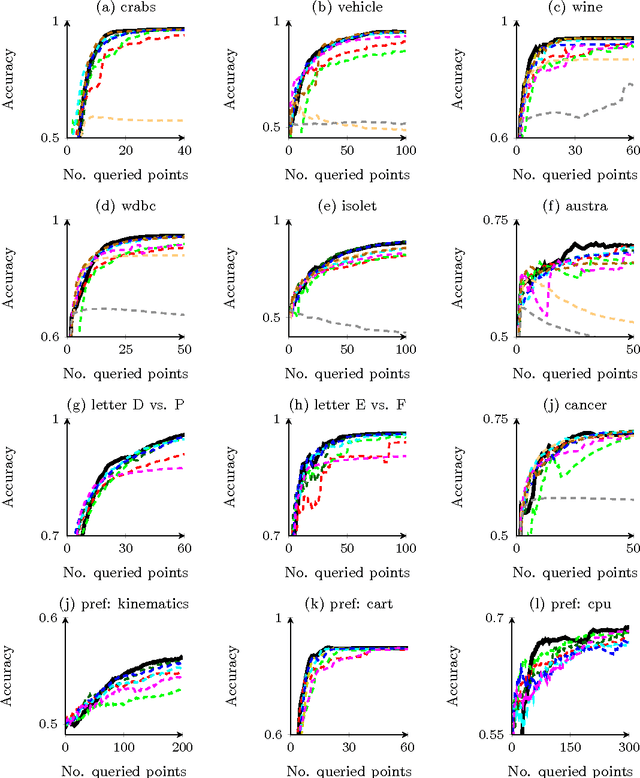
Information theoretic active learning has been widely studied for probabilistic models. For simple regression an optimal myopic policy is easily tractable. However, for other tasks and with more complex models, such as classification with nonparametric models, the optimal solution is harder to compute. Current approaches make approximations to achieve tractability. We propose an approach that expresses information gain in terms of predictive entropies, and apply this method to the Gaussian Process Classifier (GPC). Our approach makes minimal approximations to the full information theoretic objective. Our experimental performance compares favourably to many popular active learning algorithms, and has equal or lower computational complexity. We compare well to decision theoretic approaches also, which are privy to more information and require much more computational time. Secondly, by developing further a reformulation of binary preference learning to a classification problem, we extend our algorithm to Gaussian Process preference learning.