 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Concept Learning for Uncovering Latent Themes in Large Text Collections
May 08, 2023



Experts across diverse disciplines are often interested in making sense of large text collections. Traditionally, this challenge is approached either by noisy unsupervised techniques such as topic models, or by following a manual theme discovery process. In this paper, we expand the definition of a theme to account for more than just a word distribution, and include generalized concepts deemed relevant by domain experts. Then, we propose an interactive framework that receives and encodes expert feedback at different levels of abstraction. Our framework strikes a balance between automation and manual coding, allowing experts to maintain control of their study while reducing the manual effort required.
Conceptor-Aided Debiasing of Contextualized Embeddings
Nov 20, 2022Pre-trained language models reflect the inherent social biases of their training corpus. Many methods have been proposed to mitigate this issue, but they often fail to debias or they sacrifice model accuracy. We use conceptors--a soft projection method--to identify and remove the bias subspace in contextual embeddings in BERT and GPT. We propose two methods of applying conceptors (1) bias subspace projection by post-processing; and (2) a new architecture, conceptor-intervened BERT (CI-BERT), which explicitly incorporates the conceptor projection into all layers during training. We find that conceptor post-processing achieves state-of-the-art debiasing results while maintaining or improving BERT's performance on the GLUE benchmark. Although CI-BERT's training takes all layers' bias into account and can outperform its post-processing counterpart in bias mitigation, CI-BERT reduces the language model accuracy. We also show the importance of carefully constructing the bias subspace. The best results are obtained by removing outliers from the list of biased words, intersecting them (using the conceptor AND operation), and computing their embeddings using the sentences from a cleaner corpus.
StyLEx: Explaining Styles with Lexicon-Based Human Perception
Oct 14, 2022
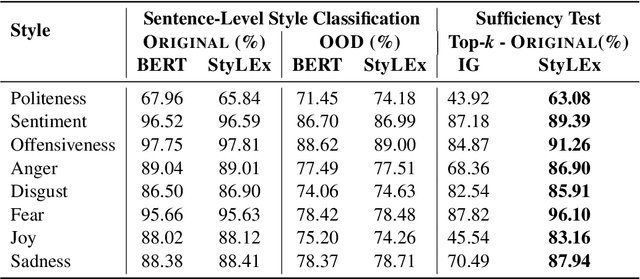
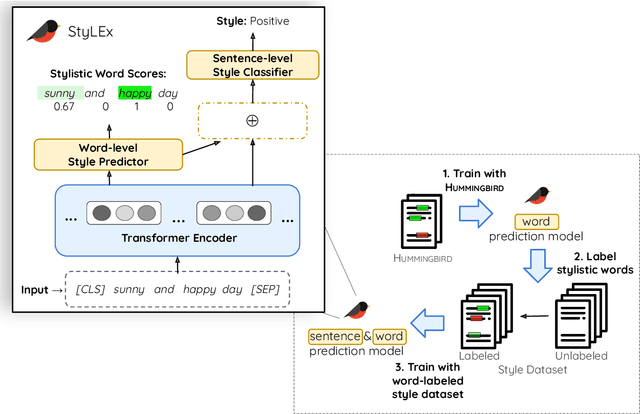
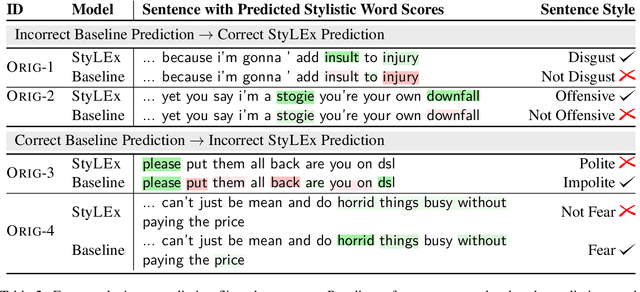
Style plays a significant role in how humans express themselves and communicate with others. Large pre-trained language models produce impressive results on various style classification tasks. However, they often learn spurious domain-specific words to make predictions. This incorrect word importance learned by the model often leads to ambiguous token-level explanations which do not align with human perception of linguistic styles. To tackle this challenge, we introduce StyLEx, a model that learns annotated human perceptions of stylistic lexica and uses these stylistic words as additional information for predicting the style of a sentence. Our experiments show that StyLEx can provide human-like stylistic lexical explanations without sacrificing the performance of sentence-level style prediction on both original and out-of-domain datasets. Explanations from StyLEx show higher sufficiency, and plausibility when compared to human annotations, and are also more understandable by human judges compared to the existing widely-used saliency baseline.
Empathic Conversations: A Multi-level Dataset of Contextualized Conversations
May 25, 2022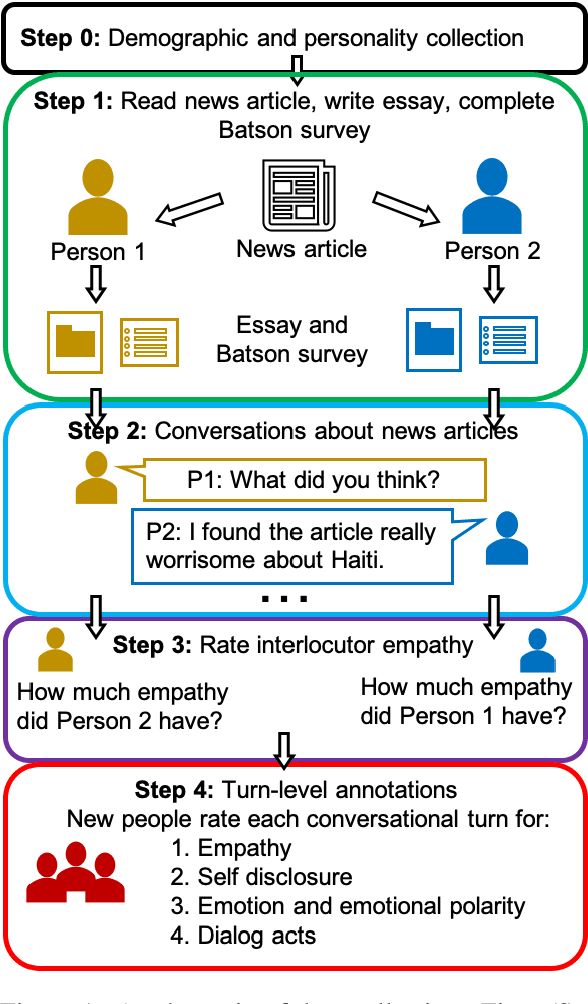
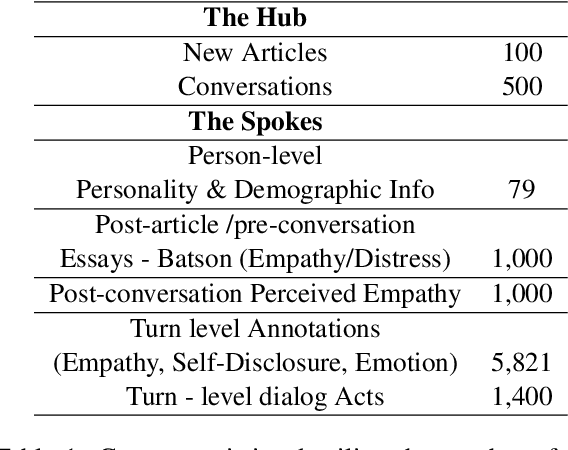
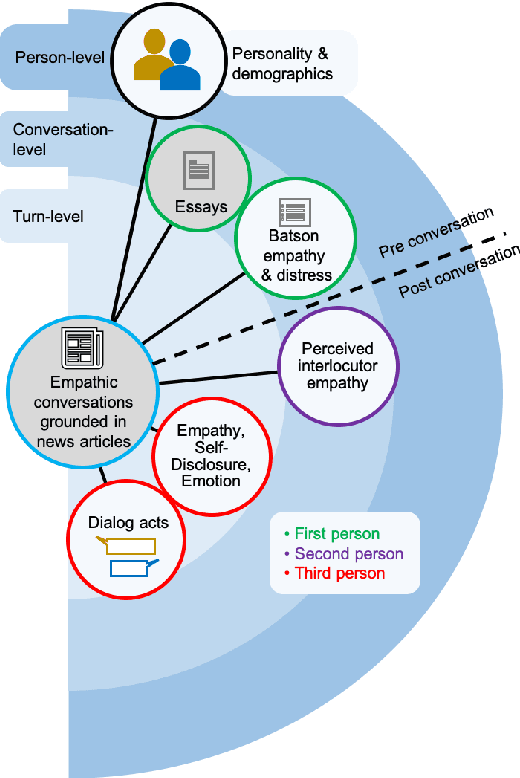
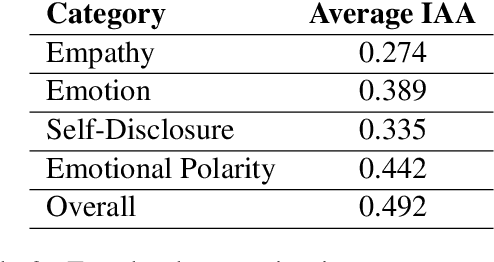
Empathy is a cognitive and emotional reaction to an observed situation of others. Empathy has recently attracted interest because it has numerous applications in psychology and AI, but it is unclear how different forms of empathy (e.g., self-report vs counterpart other-report, concern vs. distress) interact with other affective phenomena or demographics like gender and age. To better understand this, we created the {\it Empathic Conversations} dataset of annotated negative, empathy-eliciting dialogues in which pairs of participants converse about news articles. People differ in their perception of the empathy of others. These differences are associated with certain characteristics such as personality and demographics. Hence, we collected detailed characterization of the participants' traits, their self-reported empathetic response to news articles, their conversational partner other-report, and turn-by-turn third-party assessments of the level of self-disclosure, emotion, and empathy expressed. This dataset is the first to present empathy in multiple forms along with personal distress, emotion, personality characteristics, and person-level demographic information. We present baseline models for predicting some of these features from conversations.
A Holistic Framework for Analyzing the COVID-19 Vaccine Debate
May 03, 2022


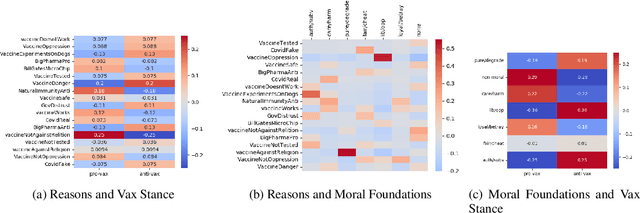
The Covid-19 pandemic has led to infodemic of low quality information leading to poor health decisions. Combating the outcomes of this infodemic is not only a question of identifying false claims, but also reasoning about the decisions individuals make. In this work we propose a holistic analysis framework connecting stance and reason analysis, and fine-grained entity level moral sentiment analysis. We study how to model the dependencies between the different level of analysis and incorporate human insights into the learning process. Experiments show that our framework provides reliable predictions even in the low-supervision settings.
Cross-Platform Difference in Facebook and Text Messages Language Use: Illustrated by Depression Diagnosis
Feb 09, 2022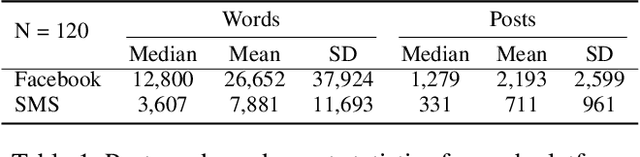
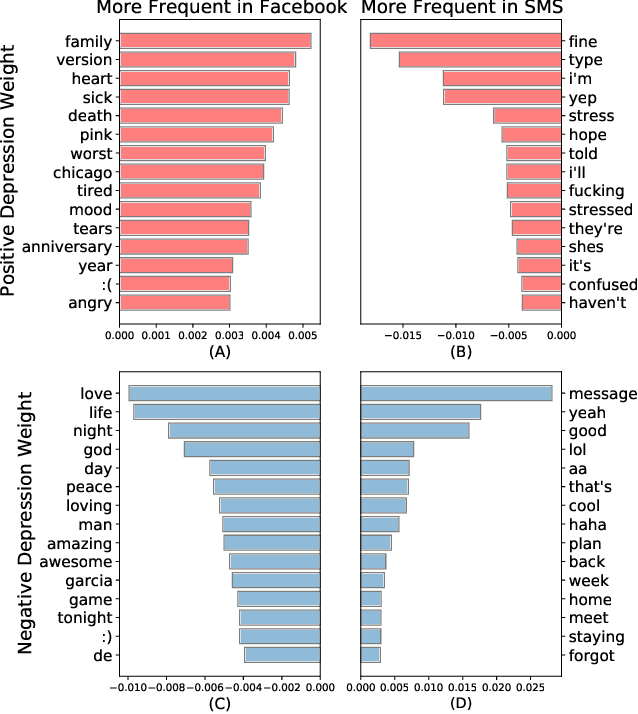
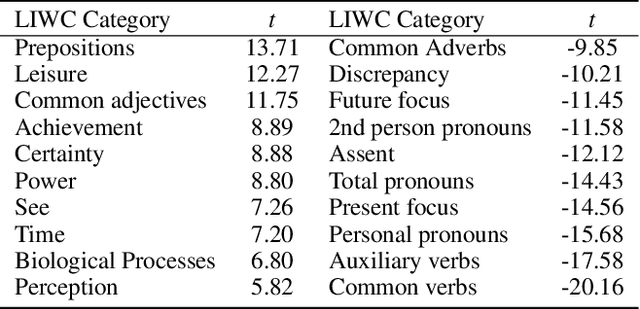

How does language differ across one's Facebook status updates vs. one's text messages (SMS)? In this study, we show how Facebook and SMS use differs in psycho-linguistic characteristics and how these differences drive downstream analyses with an illustration of depression diagnosis. We use a sample of consenting participants who shared Facebook status updates, SMS data, and answered a standard psychological depression screener. We quantify domain differences using psychologically driven lexical methods and find that language on Facebook involves more personal concerns, experiences, and content features while the language in SMS contains more informal and style features. Next, we estimate depression from both text domains, using a depression model trained on Facebook data, and find a drop in accuracy when predicting self-reported depression assessments from the SMS-based depression estimates. Finally, we evaluate a simple domain adaption correction based on words driving the cross-platform differences and applied it to the SMS-derived depression estimates, resulting in significant improvement in prediction. Our work shows the Facebook vs. SMS difference in language use and suggests the necessity of cross-domain adaption for text-based predictions.
Prospective Learning: Back to the Future
Jan 19, 2022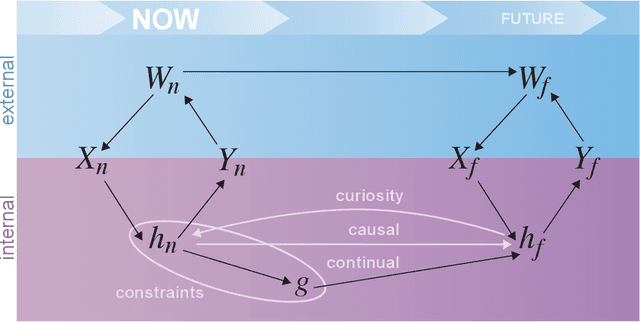

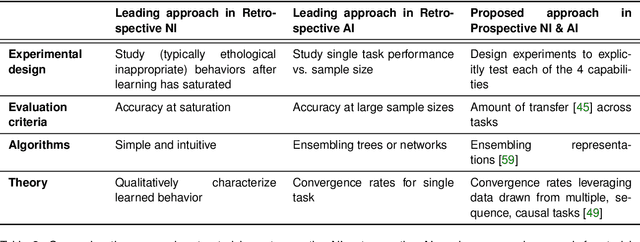
Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.
Social Media Reveals Urban-Rural Differences in Stress across China
Nov 03, 2021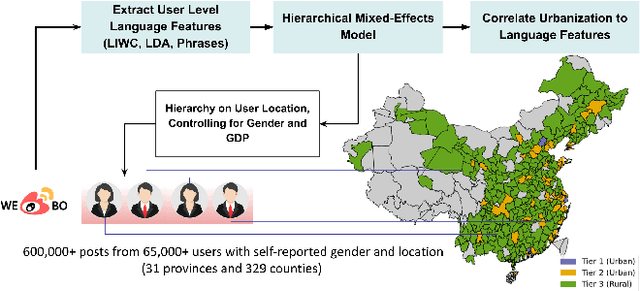
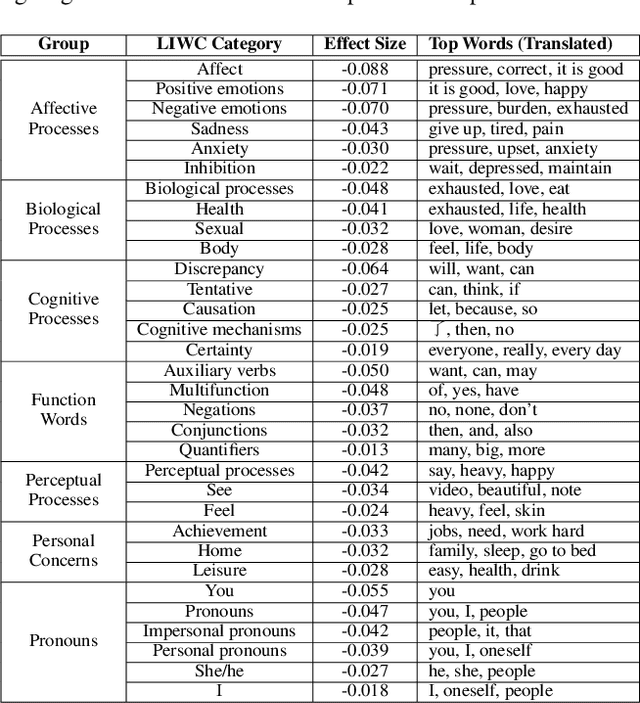
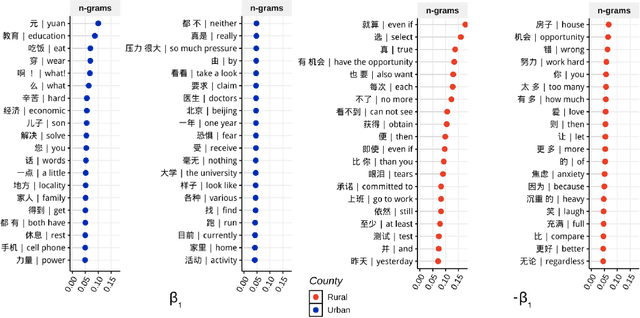
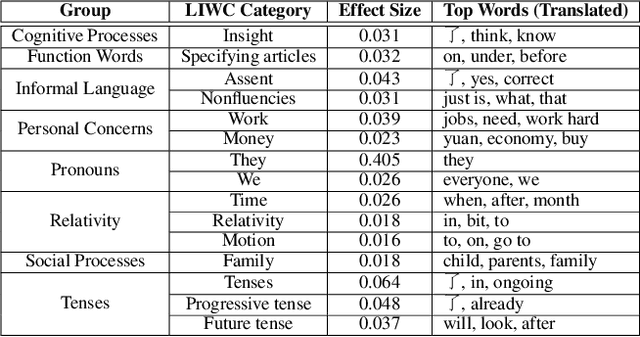
Modeling differential stress expressions in urban and rural regions in China can provide a better understanding of the effects of urbanization on psychological well-being in a country that has rapidly grown economically in the last two decades. This paper studies linguistic differences in the experiences and expressions of stress in urban-rural China from Weibo posts from over 65,000 users across 329 counties using hierarchical mixed-effects models. We analyzed phrases, topical themes, and psycho-linguistic word choices in Weibo posts mentioning stress to better understand appraisal differences surrounding psychological stress in urban and rural communities in China; we then compared them with large-scale polls from Gallup. After controlling for socioeconomic and gender differences, we found that rural communities tend to express stress in emotional and personal themes such as relationships, health, and opportunity while users in urban areas express stress using relative, temporal, and external themes such as work, politics, and economics. These differences exist beyond controlling for GDP and urbanization, indicating a fundamentally different lifestyle between rural and urban residents in very specific environments, arguably having different sources of stress. We found corroborative trends in physical, financial, and social wellness with urbanization in Gallup polls.
Does BERT Learn as Humans Perceive? Understanding Linguistic Styles through Lexica
Sep 06, 2021
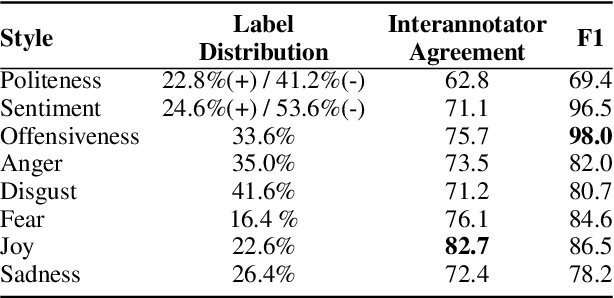

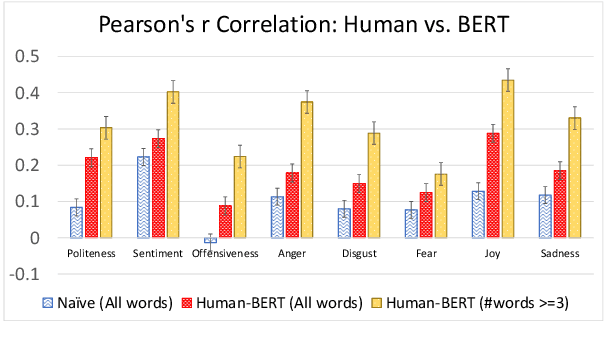
People convey their intention and attitude through linguistic styles of the text that they write. In this study, we investigate lexicon usages across styles throughout two lenses: human perception and machine word importance, since words differ in the strength of the stylistic cues that they provide. To collect labels of human perception, we curate a new dataset, Hummingbird, on top of benchmarking style datasets. We have crowd workers highlight the representative words in the text that makes them think the text has the following styles: politeness, sentiment, offensiveness, and five emotion types. We then compare these human word labels with word importance derived from a popular fine-tuned style classifier like BERT. Our results show that the BERT often finds content words not relevant to the target style as important words used in style prediction, but humans do not perceive the same way even though for some styles (e.g., positive sentiment and joy) human- and machine-identified words share significant overlap for some styles.
Toward Micro-Dialect Identification in Diaglossic and Code-Switched Environments
Oct 10, 2020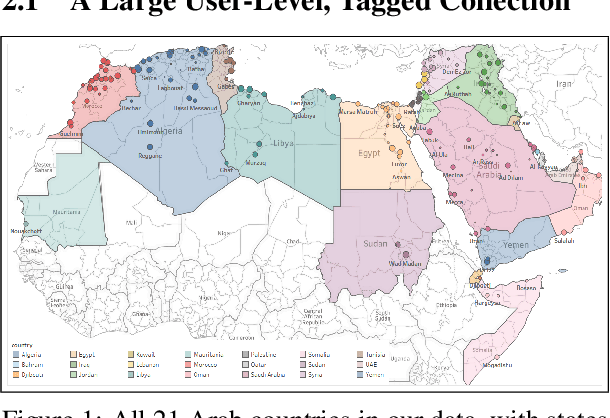
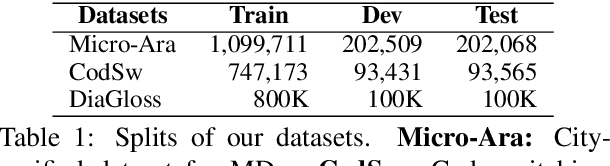

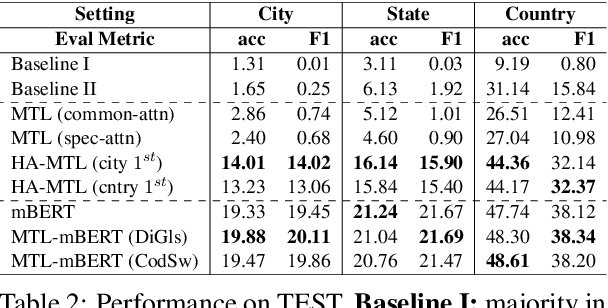
Although the prediction of dialects is an important language processing task, with a wide range of applications, existing work is largely limited to coarse-grained varieties. Inspired by geolocation research, we propose the novel task of Micro-Dialect Identification (MDI) and introduce MARBERT, a new language model with striking abilities to predict a fine-grained variety (as small as that of a city) given a single, short message. For modeling, we offer a range of novel spatially and linguistically-motivated multi-task learning models. To showcase the utility of our models, we introduce a new, large-scale dataset of Arabic micro-varieties (low-resource) suited to our tasks. MARBERT predicts micro-dialects with 9.9% F1, ~76X better than a majority class baseline. Our new language model also establishes new state-of-the-art on several external tasks.