 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust and Multilingual Speech Representations
Jan 29, 2020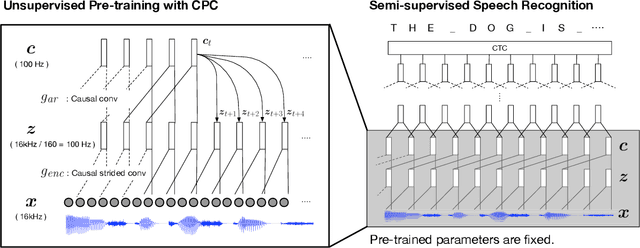
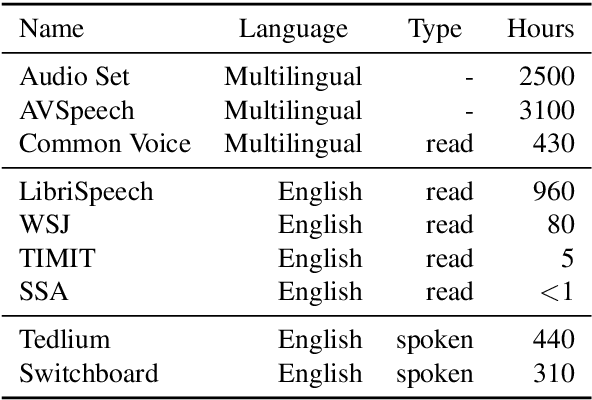
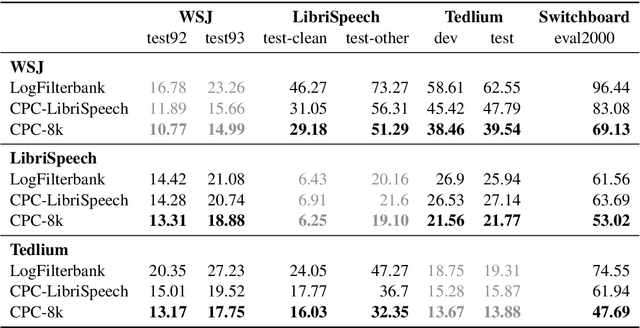
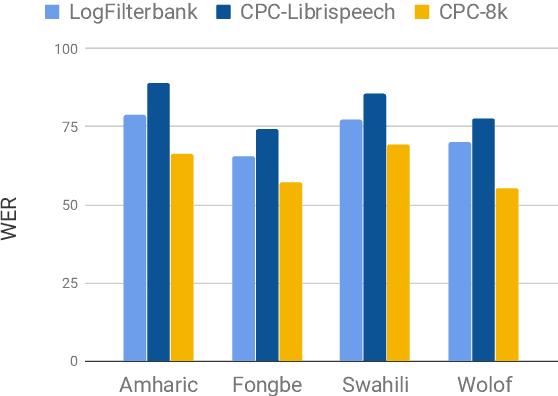
Unsupervised speech representation learning has shown remarkable success at finding representations that correlate with phonetic structures and improve downstream speech recognition performance. However, most research has been focused on evaluating the representations in terms of their ability to improve the performance of speech recognition systems on read English (e.g. Wall Street Journal and LibriSpeech). This evaluation methodology overlooks two important desiderata that speech representations should have: robustness to domain shifts and transferability to other languages. In this paper we learn representations from up to 8000 hours of diverse and noisy speech data and evaluate the representations by looking at their robustness to domain shifts and their ability to improve recognition performance in many languages. We find that our representations confer significant robustness advantages to the resulting recognition systems: we see significant improvements in out-of-domain transfer relative to baseline feature sets and the features likewise provide improvements in 25 phonetically diverse languages including tonal languages and low-resource languages.
On the Sensitivity of Adversarial Robustness to Input Data Distributions
Feb 22, 2019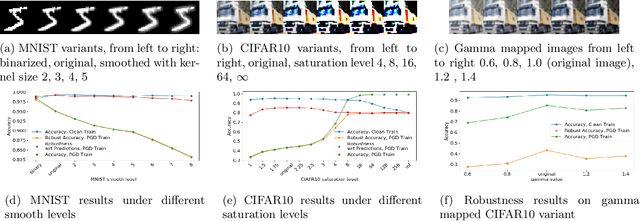
Neural networks are vulnerable to small adversarial perturbations. Existing literature largely focused on understanding and mitigating the vulnerability of learned models. In this paper, we demonstrate an intriguing phenomenon about the most popular robust training method in the literature, adversarial training: Adversarial robustness, unlike clean accuracy, is sensitive to the input data distribution. Even a semantics-preserving transformations on the input data distribution can cause a significantly different robustness for the adversarial trained model that is both trained and evaluated on the new distribution. Our discovery of such sensitivity on data distribution is based on a study which disentangles the behaviors of clean accuracy and robust accuracy of the Bayes classifier. Empirical investigations further confirm our finding. We construct semantically-identical variants for MNIST and CIFAR10 respectively, and show that standardly trained models achieve comparable clean accuracies on them, but adversarially trained models achieve significantly different robustness accuracies. This counter-intuitive phenomenon indicates that input data distribution alone can affect the adversarial robustness of trained neural networks, not necessarily the tasks themselves. Lastly, we discuss the practical implications on evaluating adversarial robustness, and make initial attempts to understand this complex phenomenon.
advertorch v0.1: An Adversarial Robustness Toolbox based on PyTorch
Feb 20, 2019advertorch is a toolbox for adversarial robustness research. It contains various implementations for attacks, defenses and robust training methods. advertorch is built on PyTorch (Paszke et al., 2017), and leverages the advantages of the dynamic computational graph to provide concise and efficient reference implementations. The code is licensed under the LGPL license and is open sourced at https://github.com/BorealisAI/advertorch .
Automatic Selection of t-SNE Perplexity
Aug 10, 2017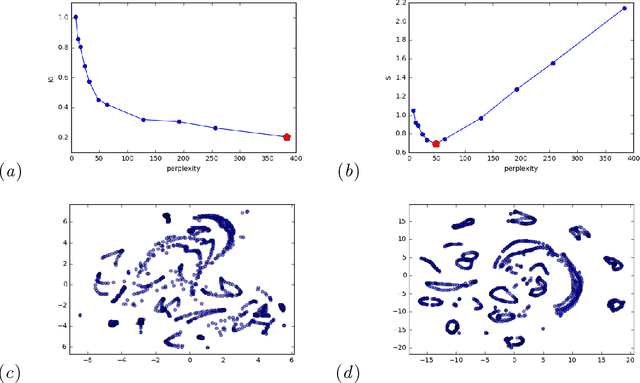
t-Distributed Stochastic Neighbor Embedding (t-SNE) is one of the most widely used dimensionality reduction methods for data visualization, but it has a perplexity hyperparameter that requires manual selection. In practice, proper tuning of t-SNE perplexity requires users to understand the inner working of the method as well as to have hands-on experience. We propose a model selection objective for t-SNE perplexity that requires negligible extra computation beyond that of the t-SNE itself. We empirically validate that the perplexity settings found by our approach are consistent with preferences elicited from human experts across a number of datasets. The similarities of our approach to Bayesian information criteria (BIC) and minimum description length (MDL) are also analyzed.