 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBranch-Train-Merge: Embarrassingly Parallel Training of Expert Language Models
Aug 05, 2022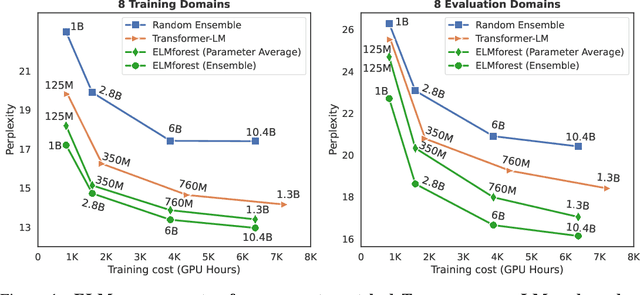
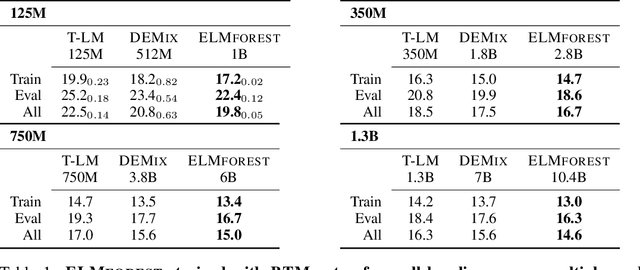
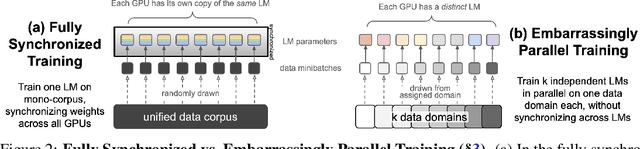

We present Branch-Train-Merge (BTM), a communication-efficient algorithm for embarrassingly parallel training of large language models (LLMs). We show it is possible to independently train subparts of a new class of LLMs on different subsets of the data, eliminating the massive multi-node synchronization currently required to train LLMs. BTM learns a set of independent expert LMs (ELMs), each specialized to a different textual domain, such as scientific or legal text. These ELMs can be added and removed to update data coverage, ensembled to generalize to new domains, or averaged to collapse back to a single LM for efficient inference. New ELMs are learned by branching from (mixtures of) ELMs in the current set, further training the parameters on data for the new domain, and then merging the resulting model back into the set for future use. Experiments show that BTM improves in- and out-of-domain perplexities as compared to GPT-style Transformer LMs, when controlling for training cost. Through extensive analysis, we show that these results are robust to different ELM initialization schemes, but require expert domain specialization; LM ensembles with random data splits do not perform well. We also present a study of scaling BTM into a new corpus of 64 domains (192B whitespace-separated tokens in total); the resulting LM (22.4B total parameters) performs as well as a Transformer LM trained with 2.5 times more compute. These gains grow with the number of domains, suggesting more aggressive parallelism could be used to efficiently train larger models in future work.
Questions Are All You Need to Train a Dense Passage Retriever
Jun 21, 2022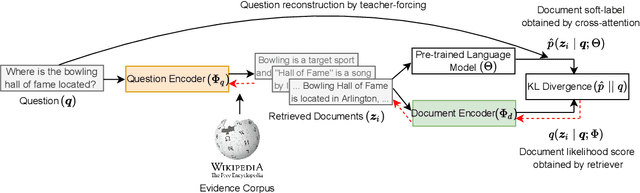
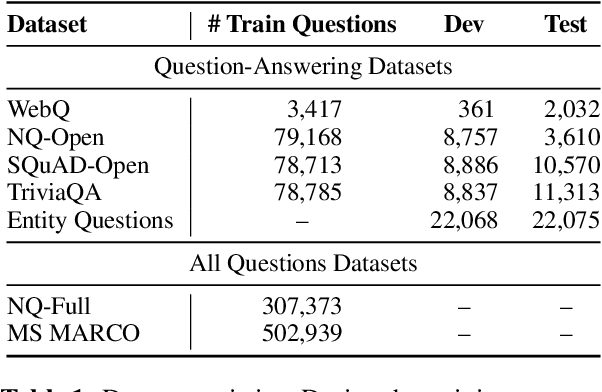
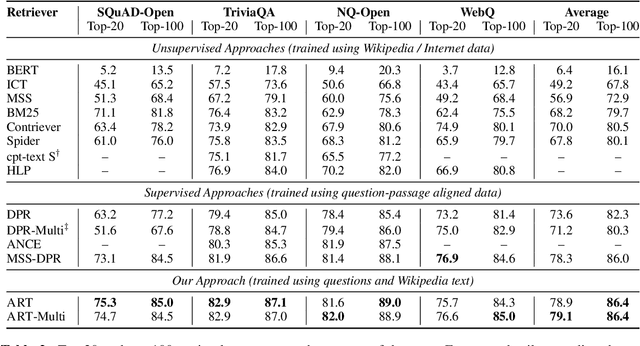
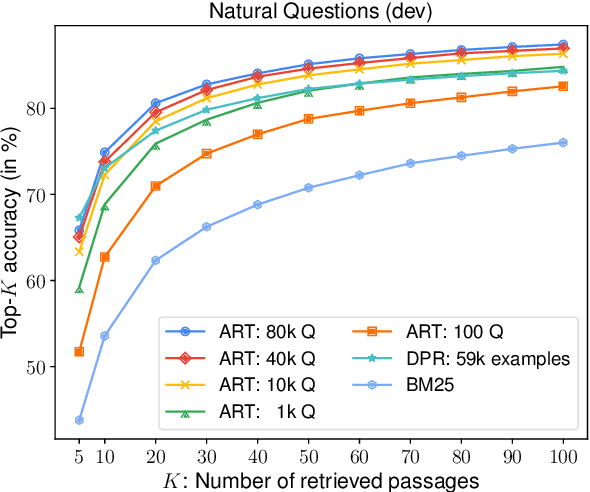
We introduce ART, a new corpus-level autoencoding approach for training dense retrieval models that does not require any labeled training data. Dense retrieval is a central challenge for open-domain tasks, such as Open QA, where state-of-the-art methods typically require large supervised datasets with custom hard-negative mining and denoising of positive examples. ART, in contrast, only requires access to unpaired inputs and outputs (e.g. questions and potential answer documents). It uses a new document-retrieval autoencoding scheme, where (1) an input question is used to retrieve a set of evidence documents, and (2) the documents are then used to compute the probability of reconstructing the original question. Training for retrieval based on question reconstruction enables effective unsupervised learning of both document and question encoders, which can be later incorporated into complete Open QA systems without any further finetuning. Extensive experiments demonstrate that ART obtains state-of-the-art results on multiple QA retrieval benchmarks with only generic initialization from a pre-trained language model, removing the need for labeled data and task-specific losses.
LegoNN: Building Modular Encoder-Decoder Models
Jun 07, 2022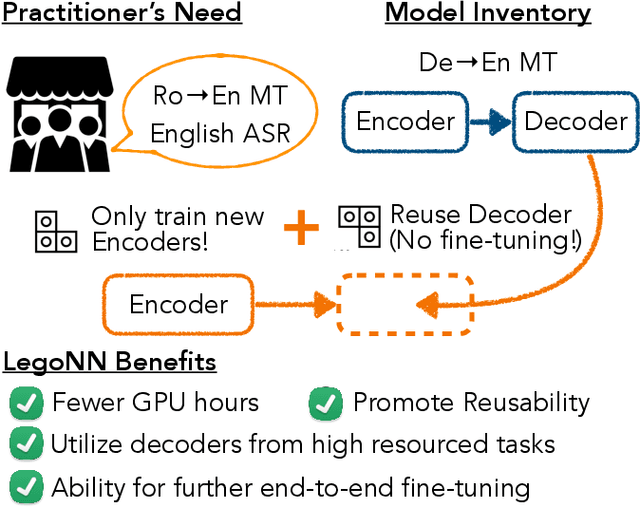
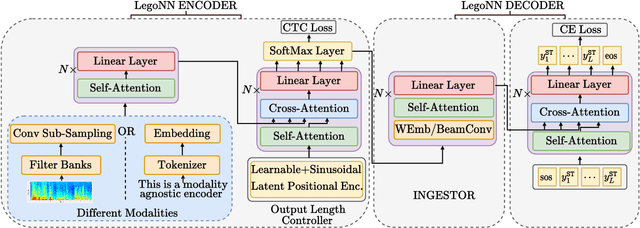
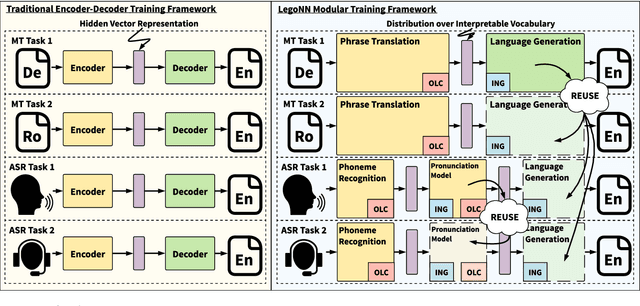
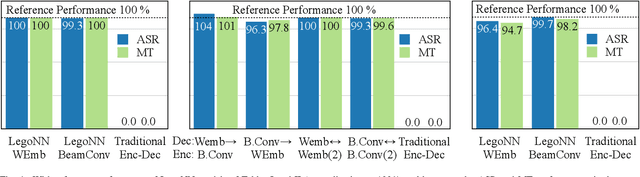
State-of-the-art encoder-decoder models (e.g. for machine translation (MT) or speech recognition (ASR)) are constructed and trained end-to-end as an atomic unit. No component of the model can be (re-)used without the others. We describe LegoNN, a procedure for building encoder-decoder architectures with decoder modules that can be reused across various MT and ASR tasks, without the need for any fine-tuning. To achieve reusability, the interface between each encoder and decoder modules is grounded to a sequence of marginal distributions over a discrete vocabulary pre-defined by the model designer. We present two approaches for ingesting these marginals; one is differentiable, allowing the flow of gradients across the entire network, and the other is gradient-isolating. To enable portability of decoder modules between MT tasks for different source languages and across other tasks like ASR, we introduce a modality agnostic encoder which consists of a length control mechanism to dynamically adapt encoders' output lengths in order to match the expected input length range of pre-trained decoders. We present several experiments to demonstrate the effectiveness of LegoNN models: a trained language generation LegoNN decoder module from German-English (De-En) MT task can be reused with no fine-tuning for the Europarl English ASR and the Romanian-English (Ro-En) MT tasks to match or beat respective baseline models. When fine-tuned towards the target task for few thousand updates, our LegoNN models improved the Ro-En MT task by 1.5 BLEU points, and achieved 12.5% relative WER reduction for the Europarl ASR task. Furthermore, to show its extensibility, we compose a LegoNN ASR model from three modules -- each has been learned within different end-to-end trained models on three different datasets -- boosting the WER reduction to 19.5%.
Nearest Neighbor Zero-Shot Inference
May 27, 2022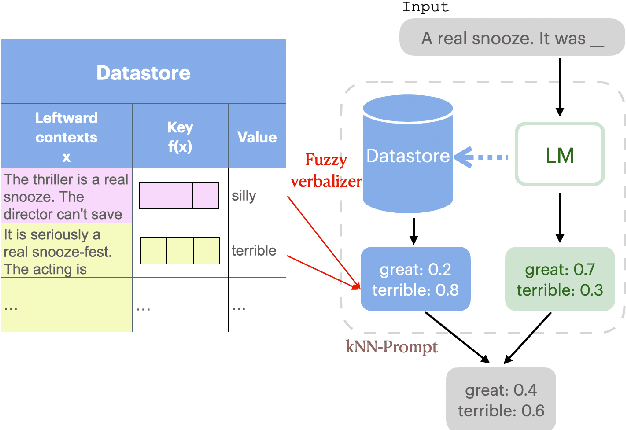
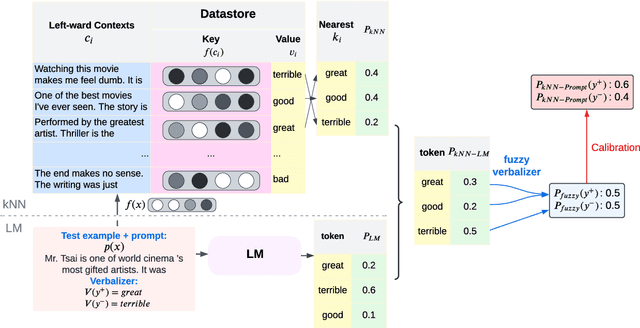

We introduce kNN-Prompt, a simple and effective technique to use k-nearest neighbor (kNN) retrieval augmentation (Khandelwal et al., 2021) for zero-shot inference with language models (LMs). Key to our approach is the introduction of fuzzy verbalizers which leverage the sparse kNN distribution for downstream tasks by automatically associating each classification label with a set of natural language tokens. Across eleven diverse end-tasks (spanning text classification, fact retrieval and question answering), using kNN-Prompt with GPT-2 Large yields significant performance boosts over zero-shot baselines (14% absolute improvement over the base LM on average). Extensive experiments show that kNN-Prompt is effective for domain adaptation with no further training, and that the benefits of retrieval increase with the size of the model used for kNN retrieval. Overall, we show that augmenting a language model with retrieval can bring significant gains for zero-shot inference, with the possibility that larger retrieval models may yield even greater benefits.
Logical Satisfiability of Counterfactuals for Faithful Explanations in NLI
May 25, 2022



Evaluating an explanation's faithfulness is desired for many reasons such as trust, interpretability and diagnosing the sources of model's errors. In this work, which focuses on the NLI task, we introduce the methodology of Faithfulness-through-Counterfactuals, which first generates a counterfactual hypothesis based on the logical predicates expressed in the explanation, and then evaluates if the model's prediction on the counterfactual is consistent with that expressed logic (i.e. if the new formula is \textit{logically satisfiable}). In contrast to existing approaches, this does not require any explanations for training a separate verification model. We first validate the efficacy of automatic counterfactual hypothesis generation, leveraging on the few-shot priming paradigm. Next, we show that our proposed metric distinguishes between human-model agreement and disagreement on new counterfactual input. In addition, we conduct a sensitivity analysis to validate that our metric is sensitive to unfaithful explanations.
Analyzing the Mono- and Cross-Lingual Pretraining Dynamics of Multilingual Language Models
May 24, 2022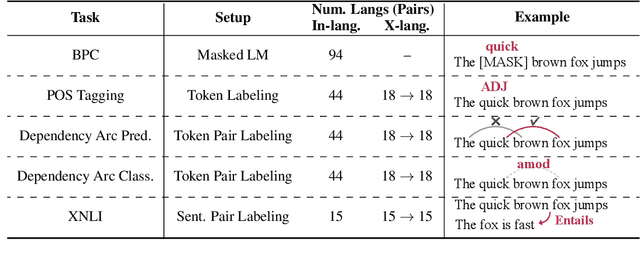

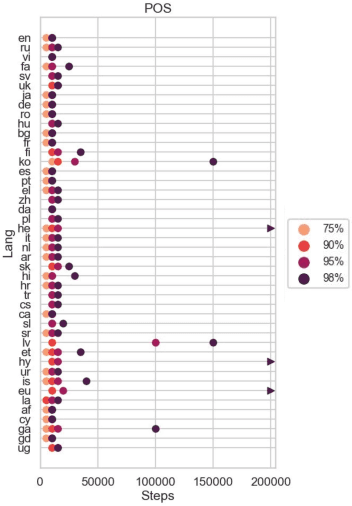
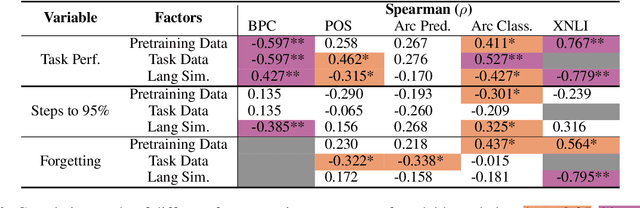
The emergent cross-lingual transfer seen in multilingual pretrained models has sparked significant interest in studying their behavior. However, because these analyses have focused on fully trained multilingual models, little is known about the dynamics of the multilingual pretraining process. We investigate when these models acquire their in-language and cross-lingual abilities by probing checkpoints taken from throughout XLM-R pretraining, using a suite of linguistic tasks. Our analysis shows that the model achieves high in-language performance early on, with lower-level linguistic skills acquired before more complex ones. In contrast, when the model learns to transfer cross-lingually depends on the language pair. Interestingly, we also observe that, across many languages and tasks, the final, converged model checkpoint exhibits significant performance degradation and that no one checkpoint performs best on all languages. Taken together with our other findings, these insights highlight the complexity and interconnectedness of multilingual pretraining.
On the Role of Bidirectionality in Language Model Pre-Training
May 24, 2022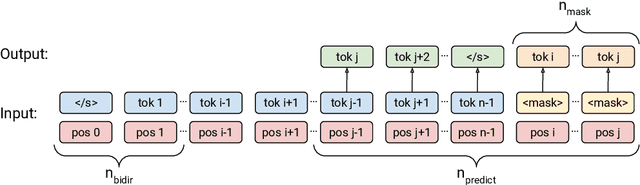

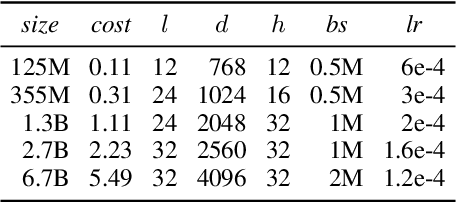
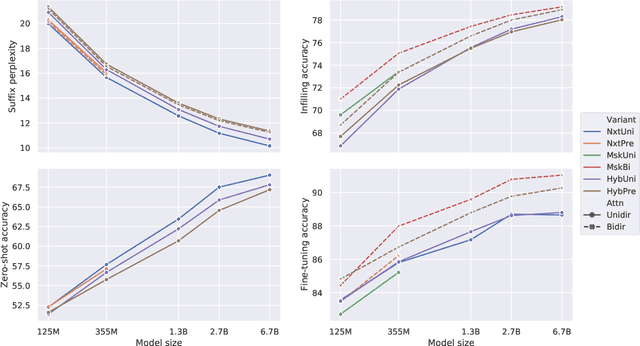
Prior work on language model pre-training has explored different architectures and learning objectives, but differences in data, hyperparameters and evaluation make a principled comparison difficult. In this work, we focus on bidirectionality as a key factor that differentiates existing approaches, and present a comprehensive study of its role in next token prediction, text infilling, zero-shot priming and fine-tuning. We propose a new framework that generalizes prior approaches, including fully unidirectional models like GPT, fully bidirectional models like BERT, and hybrid models like CM3 and prefix LM. Our framework distinguishes between two notions of bidirectionality (bidirectional context and bidirectional attention) and allows us to control each of them separately. We find that the optimal configuration is largely application-dependent (e.g., bidirectional attention is beneficial for fine-tuning and infilling, but harmful for next token prediction and zero-shot priming). We train models with up to 6.7B parameters, and find differences to remain consistent at scale. While prior work on scaling has focused on left-to-right autoregressive models, our results suggest that this approach comes with some trade-offs, and it might be worthwhile to develop very large bidirectional models.
Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models
May 22, 2022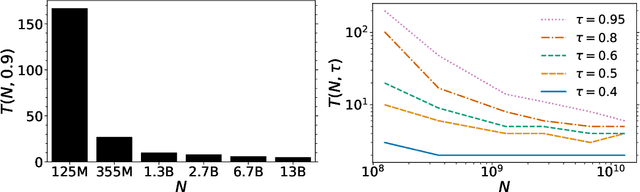
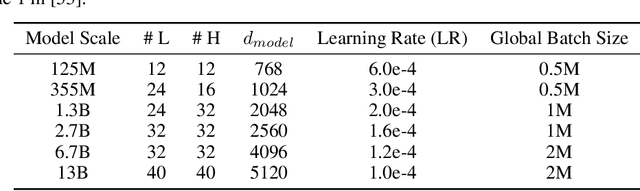
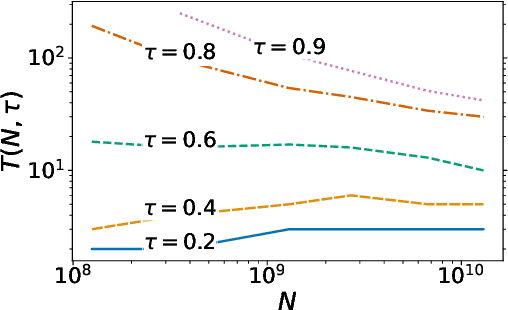
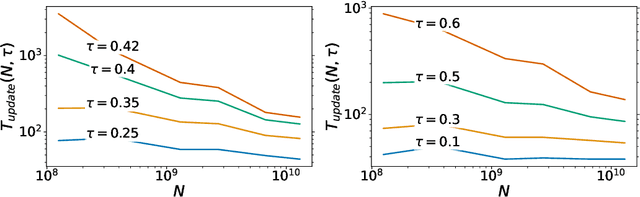
Despite their wide adoption, the underlying training and memorization dynamics of very large language models is not well understood. We empirically study exact memorization in causal and masked language modeling, across model sizes and throughout the training process. We measure the effects of dataset size, learning rate, and model size on memorization, finding that larger language models memorize training data faster across all settings. Surprisingly, we show that larger models can memorize a larger portion of the data before over-fitting and tend to forget less throughout the training process. We also analyze the memorization dynamics of different parts of speech and find that models memorize nouns and numbers first; we hypothesize and provide empirical evidence that nouns and numbers act as a unique identifier for memorizing individual training examples. Together, these findings present another piece of the broader puzzle of trying to understand what actually improves as models get bigger.
Few-shot Mining of Naturally Occurring Inputs and Outputs
May 09, 2022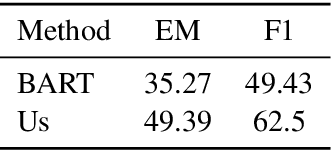
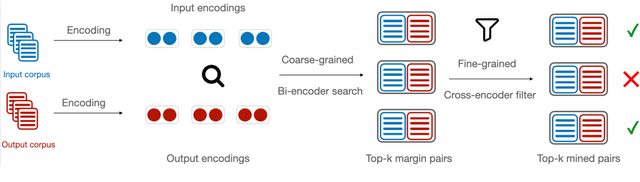
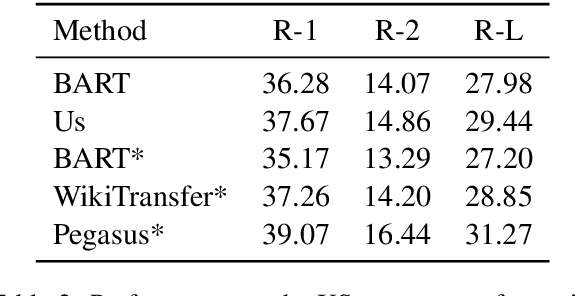
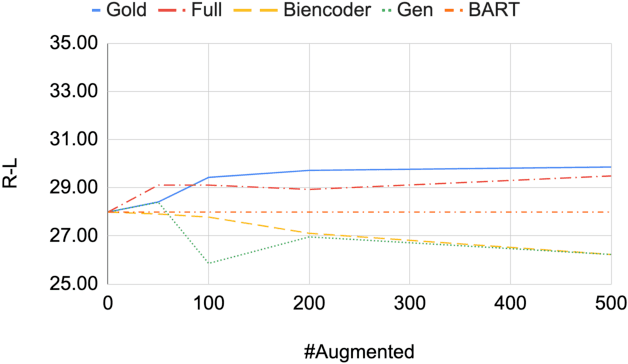
Creating labeled natural language training data is expensive and requires significant human effort. We mine input output examples from large corpora using a supervised mining function trained using a small seed set of only 100 examples. The mining consists of two stages -- (1) a biencoder-based recall-oriented dense search which pairs inputs with potential outputs, and (2) a crossencoder-based filter which re-ranks the output of the biencoder stage for better precision. Unlike model-generated data augmentation, our method mines naturally occurring high-quality input output pairs to mimic the style of the seed set for multiple tasks. On SQuAD-style reading comprehension, augmenting the seed set with the mined data results in an improvement of 13 F1 over a BART-large baseline fine-tuned only on the seed set. Likewise, we see improvements of 1.46 ROUGE-L on Xsum abstractive summarization.
OPT: Open Pre-trained Transformer Language Models
May 05, 2022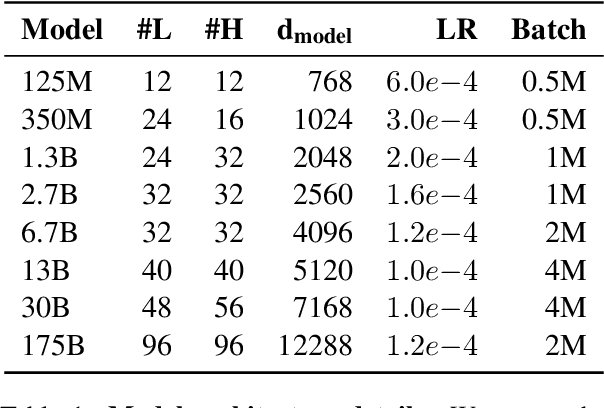
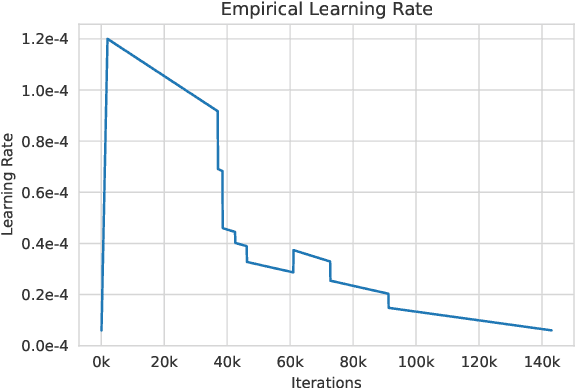
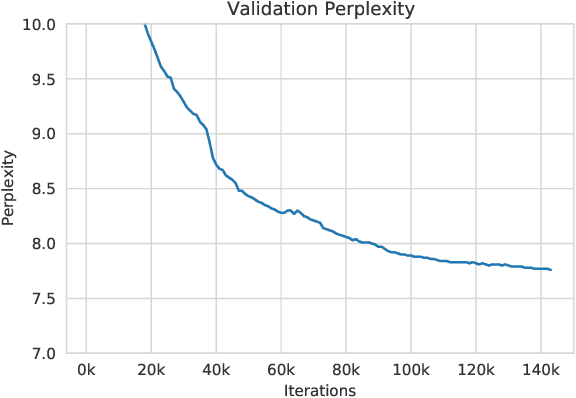
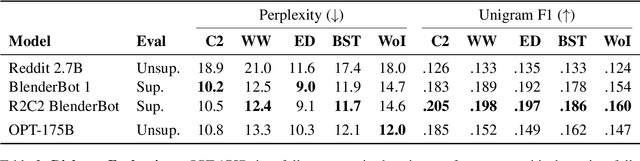
Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.