 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Image Detection: Highlights from the IEEE Video and Image Processing Cup 2022 Student Competition
Sep 21, 2023The Video and Image Processing (VIP) Cup is a student competition that takes place each year at the IEEE International Conference on Image Processing. The 2022 IEEE VIP Cup asked undergraduate students to develop a system capable of distinguishing pristine images from generated ones. The interest in this topic stems from the incredible advances in the AI-based generation of visual data, with tools that allows the synthesis of highly realistic images and videos. While this opens up a large number of new opportunities, it also undermines the trustworthiness of media content and fosters the spread of disinformation on the internet. Recently there was strong concern about the generation of extremely realistic images by means of editing software that includes the recent technology on diffusion models. In this context, there is a need to develop robust and automatic tools for synthetic image detection.
Information Forensics and Security: A quarter-century-long journey
Sep 21, 2023Information Forensics and Security (IFS) is an active R&D area whose goal is to ensure that people use devices, data, and intellectual properties for authorized purposes and to facilitate the gathering of solid evidence to hold perpetrators accountable. For over a quarter century since the 1990s, the IFS research area has grown tremendously to address the societal needs of the digital information era. The IEEE Signal Processing Society (SPS) has emerged as an important hub and leader in this area, and the article below celebrates some landmark technical contributions. In particular, we highlight the major technological advances on some selected focus areas in the field developed in the last 25 years from the research community and present future trends.
M3Dsynth: A dataset of medical 3D images with AI-generated local manipulations
Sep 14, 2023The ability to detect manipulated visual content is becoming increasingly important in many application fields, given the rapid advances in image synthesis methods. Of particular concern is the possibility of modifying the content of medical images, altering the resulting diagnoses. Despite its relevance, this issue has received limited attention from the research community. One reason is the lack of large and curated datasets to use for development and benchmarking purposes. Here, we investigate this issue and propose M3Dsynth, a large dataset of manipulated Computed Tomography (CT) lung images. We create manipulated images by injecting or removing lung cancer nodules in real CT scans, using three different methods based on Generative Adversarial Networks (GAN) or Diffusion Models (DM), for a total of 8,577 manipulated samples. Experiments show that these images easily fool automated diagnostic tools. We also tested several state-of-the-art forensic detectors and demonstrated that, once trained on the proposed dataset, they are able to accurately detect and localize manipulated synthetic content, including when training and test sets are not aligned, showing good generalization ability. Dataset and code will be publicly available at https://grip-unina.github.io/M3Dsynth/.
Intriguing properties of synthetic images: from generative adversarial networks to diffusion models
Apr 13, 2023



Detecting fake images is becoming a major goal of computer vision. This need is becoming more and more pressing with the continuous improvement of synthesis methods based on Generative Adversarial Networks (GAN), and even more with the appearance of powerful methods based on Diffusion Models (DM). Towards this end, it is important to gain insight into which image features better discriminate fake images from real ones. In this paper we report on our systematic study of a large number of image generators of different families, aimed at discovering the most forensically relevant characteristics of real and generated images. Our experiments provide a number of interesting observations and shed light on some intriguing properties of synthetic images: (1) not only the GAN models but also the DM and VQ-GAN (Vector Quantized Generative Adversarial Networks) models give rise to visible artifacts in the Fourier domain and exhibit anomalous regular patterns in the autocorrelation; (2) when the dataset used to train the model lacks sufficient variety, its biases can be transferred to the generated images; (3) synthetic and real images exhibit significant differences in the mid-high frequency signal content, observable in their radial and angular spectral power distributions.
Learning Pairwise Interaction for Generalizable DeepFake Detection
Feb 26, 2023



A fast-paced development of DeepFake generation techniques challenge the detection schemes designed for known type DeepFakes. A reliable Deepfake detection approach must be agnostic to generation types, which can present diverse quality and appearance. Limited generalizability across different generation schemes will restrict the wide-scale deployment of detectors if they fail to handle unseen attacks in an open set scenario. We propose a new approach, Multi-Channel Xception Attention Pairwise Interaction (MCX-API), that exploits the power of pairwise learning and complementary information from different color space representations in a fine-grained manner. We first validate our idea on a publicly available dataset in a intra-class setting (closed set) with four different Deepfake schemes. Further, we report all the results using balanced-open-set-classification (BOSC) accuracy in an inter-class setting (open-set) using three public datasets. Our experiments indicate that our proposed method can generalize better than the state-of-the-art Deepfakes detectors. We obtain 98.48% BOSC accuracy on the FF++ dataset and 90.87% BOSC accuracy on the CelebDF dataset suggesting a promising direction for generalization of DeepFake detection. We further utilize t-SNE and attention maps to interpret and visualize the decision-making process of our proposed network. https://github.com/xuyingzhongguo/MCX-API
TruFor: Leveraging all-round clues for trustworthy image forgery detection and localization
Dec 21, 2022



In this paper we present TruFor, a forensic framework that can be applied to a large variety of image manipulation methods, from classic cheapfakes to more recent manipulations based on deep learning. We rely on the extraction of both high-level and low-level traces through a transformer-based fusion architecture that combines the RGB image and a learned noise-sensitive fingerprint. The latter learns to embed the artifacts related to the camera internal and external processing by training only on real data in a self-supervised manner. Forgeries are detected as deviations from the expected regular pattern that characterizes each pristine image. Looking for anomalies makes the approach able to robustly detect a variety of local manipulations, ensuring generalization. In addition to a pixel-level localization map and a whole-image integrity score, our approach outputs a reliability map that highlights areas where localization predictions may be error-prone. This is particularly important in forensic applications in order to reduce false alarms and allow for a large scale analysis. Extensive experiments on several datasets show that our method is able to reliably detect and localize both cheapfakes and deepfakes manipulations outperforming state-of-the-art works. Code will be publicly available at https://grip-unina.github.io/TruFor/
Training Data Improvement for Image Forgery Detection using Comprint
Nov 25, 2022
Manipulated images are a threat to consumers worldwide, when they are used to spread disinformation. Therefore, Comprint enables forgery detection by utilizing JPEG-compression fingerprints. This paper evaluates the impact of the training set on Comprint's performance. Most interestingly, we found that including images compressed with low quality factors during training does not have a significant effect on the accuracy, whereas incorporating recompression boosts the robustness. As such, consumers can use Comprint on their smartphones to verify the authenticity of images.
On the detection of synthetic images generated by diffusion models
Nov 01, 2022



Over the past decade, there has been tremendous progress in creating synthetic media, mainly thanks to the development of powerful methods based on generative adversarial networks (GAN). Very recently, methods based on diffusion models (DM) have been gaining the spotlight. In addition to providing an impressive level of photorealism, they enable the creation of text-based visual content, opening up new and exciting opportunities in many different application fields, from arts to video games. On the other hand, this property is an additional asset in the hands of malicious users, who can generate and distribute fake media perfectly adapted to their attacks, posing new challenges to the media forensic community. With this work, we seek to understand how difficult it is to distinguish synthetic images generated by diffusion models from pristine ones and whether current state-of-the-art detectors are suitable for the task. To this end, first we expose the forensics traces left by diffusion models, then study how current detectors, developed for GAN-generated images, perform on these new synthetic images, especially in challenging social-networks scenarios involving image compression and resizing. Datasets and code are available at github.com/grip-unina/DMimageDetection.
How to Boost Face Recognition with StyleGAN?
Oct 18, 2022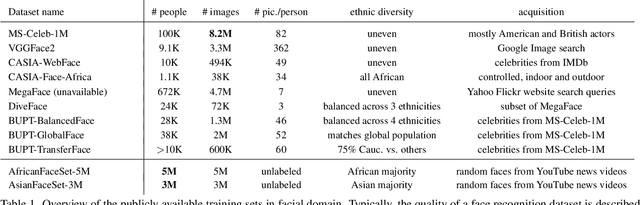
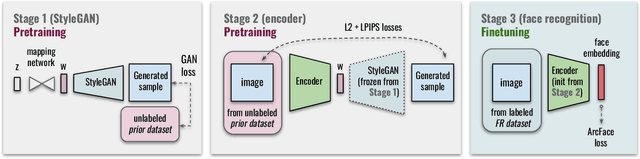
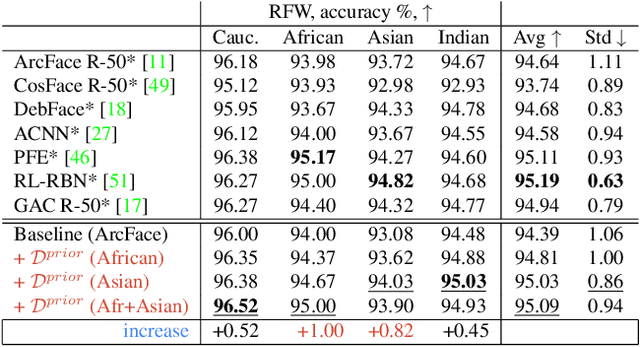

State-of-the-art face recognition systems require huge amounts of labeled training data. Given the priority of privacy in face recognition applications, the data is limited to celebrity web crawls, which have issues such as skewed distributions of ethnicities and limited numbers of identities. On the other hand, the self-supervised revolution in the industry motivates research on adaptation of the related techniques to facial recognition. One of the most popular practical tricks is to augment the dataset by the samples drawn from the high-resolution high-fidelity models (e.g. StyleGAN-like), while preserving the identity. We show that a simple approach based on fine-tuning an encoder for StyleGAN allows to improve upon the state-of-the-art facial recognition and performs better compared to training on synthetic face identities. We also collect large-scale unlabeled datasets with controllable ethnic constitution -- AfricanFaceSet-5M (5 million images of different people) and AsianFaceSet-3M (3 million images of different people) and we show that pretraining on each of them improves recognition of the respective ethnicities (as well as also others), while combining all unlabeled datasets results in the biggest performance increase. Our self-supervised strategy is the most useful with limited amounts of labeled training data, which can be beneficial for more tailored face recognition tasks and when facing privacy concerns. Evaluation is provided based on a standard RFW dataset and a new large-scale RB-WebFace benchmark.
Comprint: Image Forgery Detection and Localization using Compression Fingerprints
Oct 05, 2022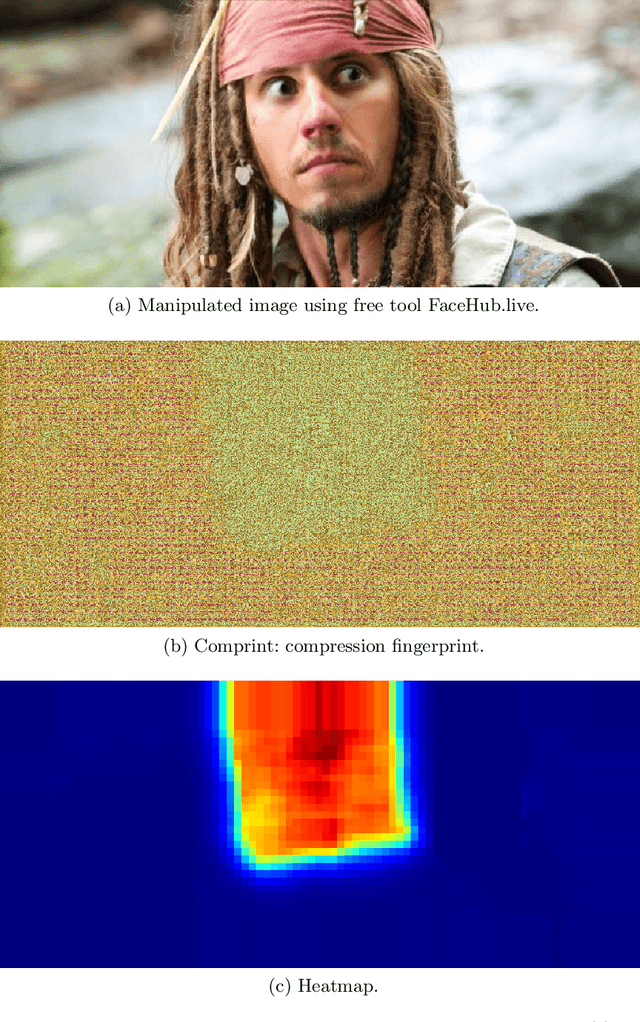
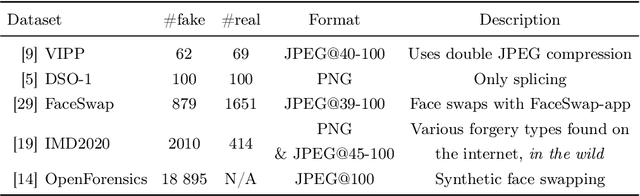
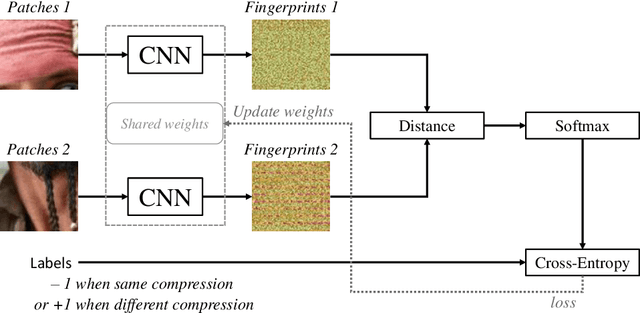
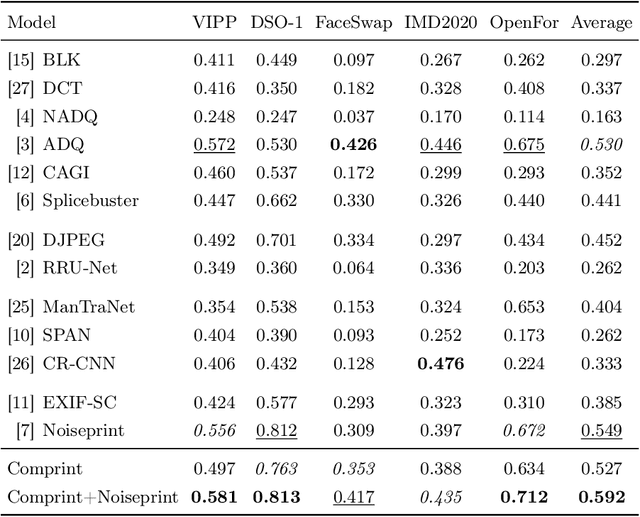
Manipulation tools that realistically edit images are widely available, making it easy for anyone to create and spread misinformation. In an attempt to fight fake news, forgery detection and localization methods were designed. However, existing methods struggle to accurately reveal manipulations found in images on the internet, i.e., in the wild. That is because the type of forgery is typically unknown, in addition to the tampering traces being damaged by recompression. This paper presents Comprint, a novel forgery detection and localization method based on the compression fingerprint or comprint. It is trained on pristine data only, providing generalization to detect different types of manipulation. Additionally, we propose a fusion of Comprint with the state-of-the-art Noiseprint, which utilizes a complementary camera model fingerprint. We carry out an extensive experimental analysis and demonstrate that Comprint has a high level of accuracy on five evaluation datasets that represent a wide range of manipulation types, mimicking in-the-wild circumstances. Most notably, the proposed fusion significantly outperforms state-of-the-art reference methods. As such, Comprint and the fusion Comprint+Noiseprint represent a promising forensics tool to analyze in-the-wild tampered images.