 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling General Properties of Nouns by Selectively Averaging Contextualised Embeddings
Dec 04, 2020
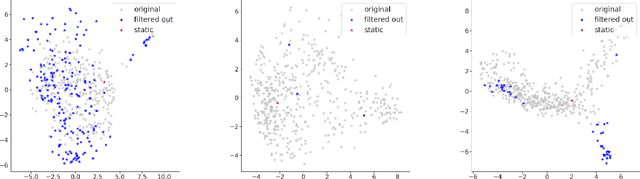

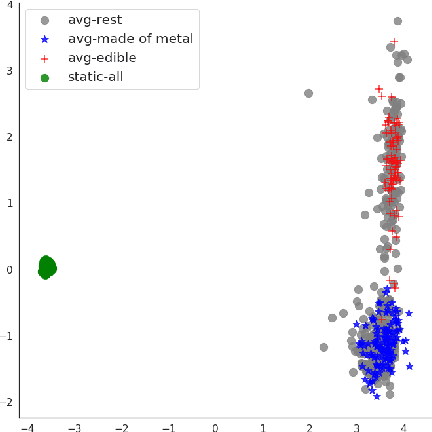
While the success of pre-trained language models has largely eliminated the need for high-quality static word vectors in many NLP applications, static word vectors continue to play an important role in tasks where word meaning needs to be modelled in the absence of linguistic context. In this paper, we explore how the contextualised embeddings predicted by BERT can be used to produce high-quality word vectors for such domains, in particular related to knowledge base completion, where our focus is on capturing the semantic properties of nouns. We find that a simple strategy of averaging the contextualised embeddings of masked word mentions leads to vectors that outperform the static word vectors learned by BERT, as well as those from standard word embedding models, in property induction tasks. We notice in particular that masking target words is critical to achieve this strong performance, as the resulting vectors focus less on idiosyncratic properties and more on general semantic properties. Inspired by this view, we propose a filtering strategy which is aimed at removing the most idiosyncratic mention vectors, allowing us to obtain further performance gains in property induction.
Don't Patronize Me! An Annotated Dataset with Patronizing and Condescending Language towards Vulnerable Communities
Nov 16, 2020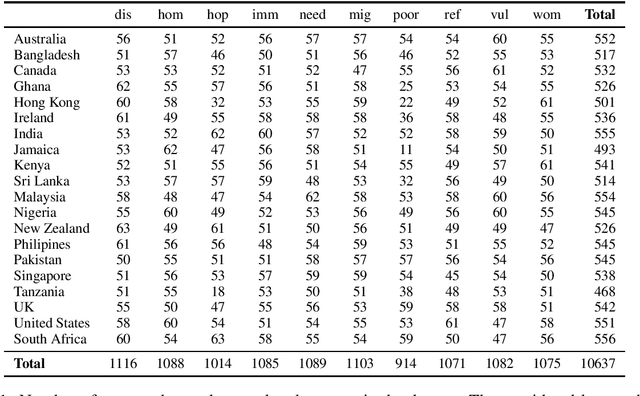
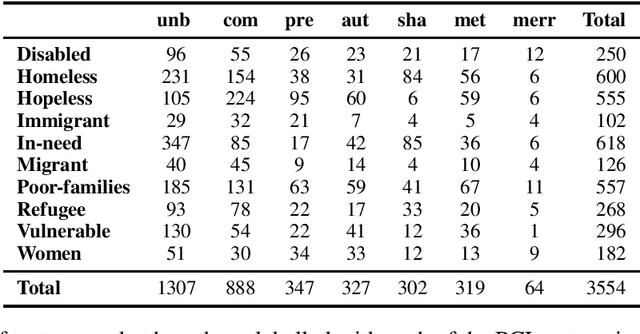
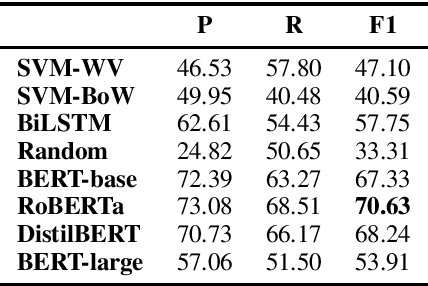
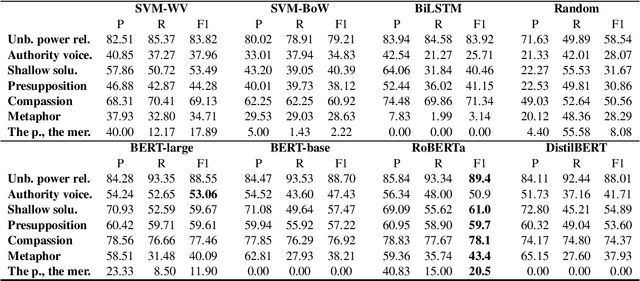
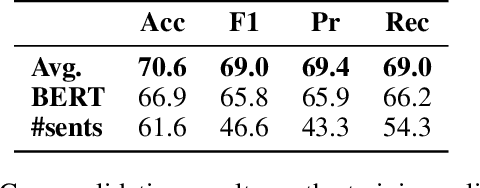
In this paper, we introduce a new annotated dataset which is aimed at supporting the development of NLP models to identify and categorize language that is patronizing or condescending towards vulnerable communities (e.g. refugees, homeless people, poor families). While the prevalence of such language in the general media has long been shown to have harmful effects, it differs from other types of harmful language, in that it is generally used unconsciously and with good intentions. We furthermore believe that the often subtle nature of patronizing and condescending language (PCL) presents an interesting technical challenge for the NLP community. Our analysis of the proposed dataset shows that identifying PCL is hard for standard NLP models, with language models such as BERT achieving the best results.
Overview of CAPITEL Shared Tasks at IberLEF 2020: Named Entity Recognition and Universal Dependencies Parsing
Nov 11, 2020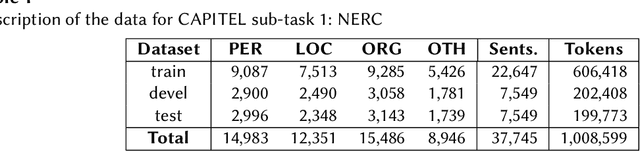
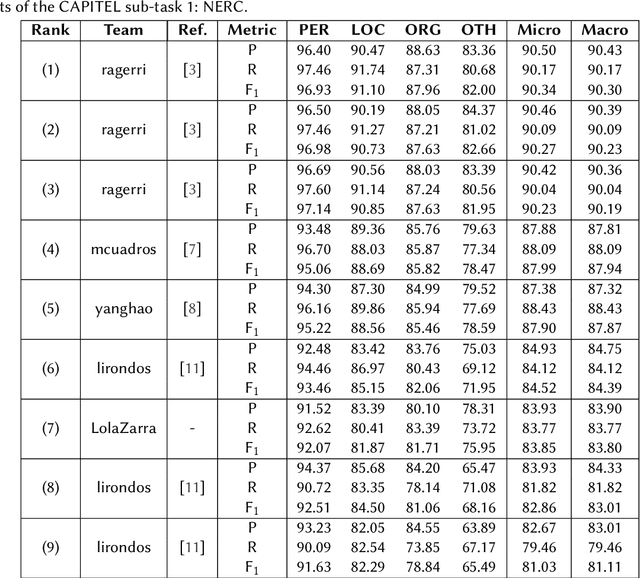
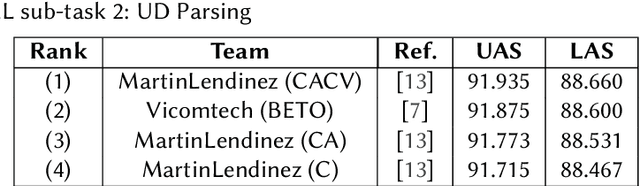
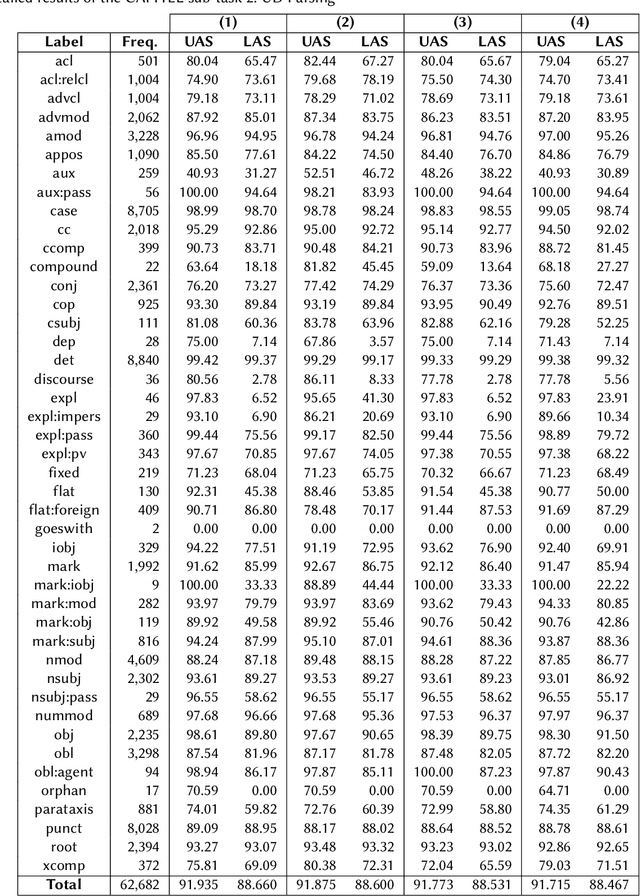
We present the results of the CAPITEL-EVAL shared task, held in the context of the IberLEF 2020 competition series. CAPITEL-EVAL consisted on two subtasks: (1) Named Entity Recognition and Classification and (2) Universal Dependency parsing. For both, the source data was a newly annotated corpus, CAPITEL, a collection of Spanish articles in the newswire domain. A total of seven teams participated in CAPITEL-EVAL, with a total of 13 runs submitted across all subtasks. Data, results and further information about this task can be found at sites.google.com/view/capitel2020.
Towards Preemptive Detection of Depression and Anxiety in Twitter
Nov 10, 2020
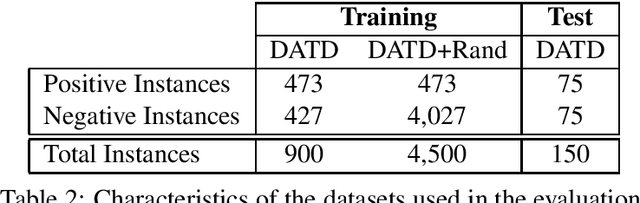
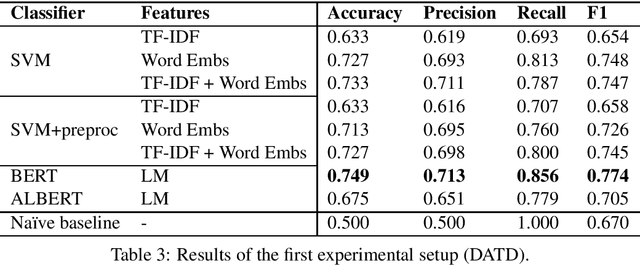
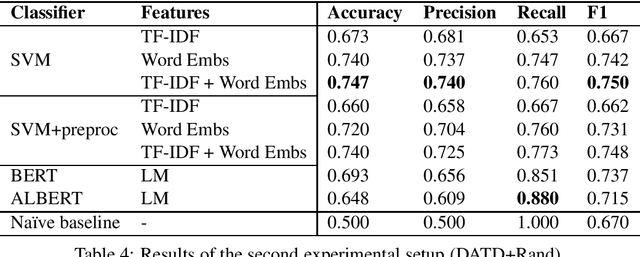
Depression and anxiety are psychiatric disorders that are observed in many areas of everyday life. For example, these disorders manifest themselves somewhat frequently in texts written by nondiagnosed users in social media. However, detecting users with these conditions is not a straightforward task as they may not explicitly talk about their mental state, and if they do, contextual cues such as immediacy must be taken into account. When available, linguistic flags pointing to probable anxiety or depression could be used by medical experts to write better guidelines and treatments. In this paper, we develop a dataset designed to foster research in depression and anxiety detection in Twitter, framing the detection task as a binary tweet classification problem. We then apply state-of-the-art classification models to this dataset, providing a competitive set of baselines alongside qualitative error analysis. Our results show that language models perform reasonably well, and better than more traditional baselines. Nonetheless, there is clear room for improvement, particularly with unbalanced training sets and in cases where seemingly obvious linguistic cues (keywords) are used counter-intuitively.
TweetEval: Unified Benchmark and Comparative Evaluation for Tweet Classification
Oct 26, 2020
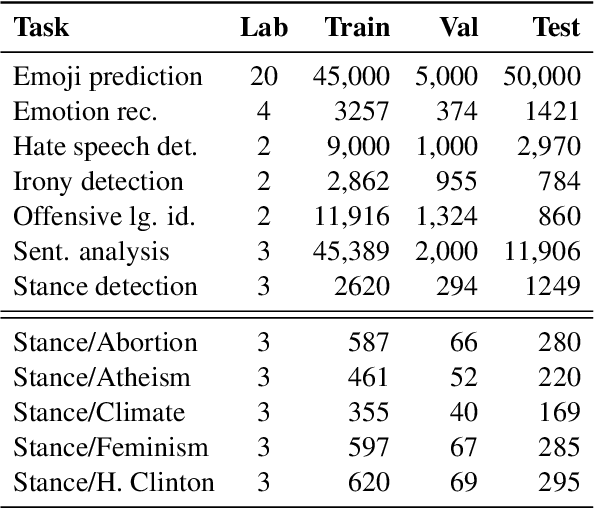
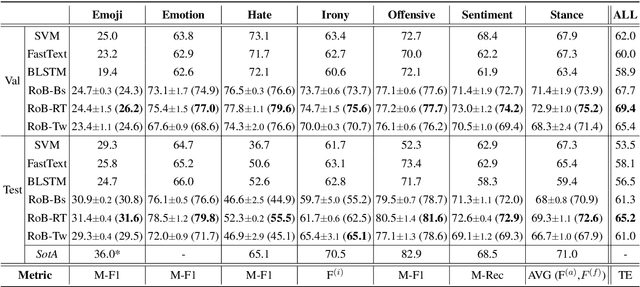
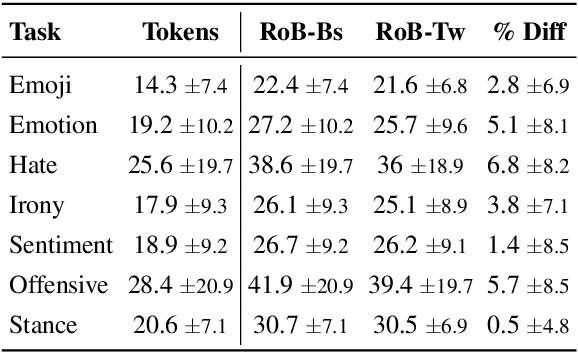
The experimental landscape in natural language processing for social media is too fragmented. Each year, new shared tasks and datasets are proposed, ranging from classics like sentiment analysis to irony detection or emoji prediction. Therefore, it is unclear what the current state of the art is, as there is no standardized evaluation protocol, neither a strong set of baselines trained on such domain-specific data. In this paper, we propose a new evaluation framework (TweetEval) consisting of seven heterogeneous Twitter-specific classification tasks. We also provide a strong set of baselines as starting point, and compare different language modeling pre-training strategies. Our initial experiments show the effectiveness of starting off with existing pre-trained generic language models, and continue training them on Twitter corpora.
Modelling Semantic Categories using Conceptual Neighborhood
Dec 03, 2019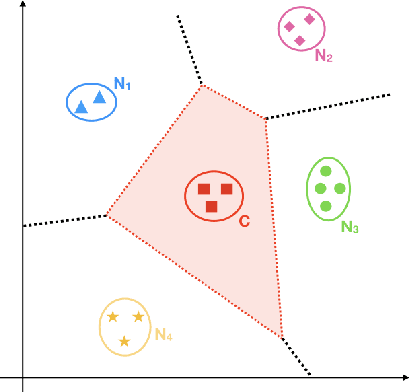
While many methods for learning vector space embeddings have been proposed in the field of Natural Language Processing, these methods typically do not distinguish between categories and individuals. Intuitively, if individuals are represented as vectors, we can think of categories as (soft) regions in the embedding space. Unfortunately, meaningful regions can be difficult to estimate, especially since we often have few examples of individuals that belong to a given category. To address this issue, we rely on the fact that different categories are often highly interdependent. In particular, categories often have conceptual neighbors, which are disjoint from but closely related to the given category (e.g.\ fruit and vegetable). Our hypothesis is that more accurate category representations can be learned by relying on the assumption that the regions representing such conceptual neighbors should be adjacent in the embedding space. We propose a simple method for identifying conceptual neighbors and then show that incorporating these conceptual neighbors indeed leads to more accurate region based representations.
Meemi: A Simple Method for Post-processing Cross-lingual Word Embeddings
Oct 22, 2019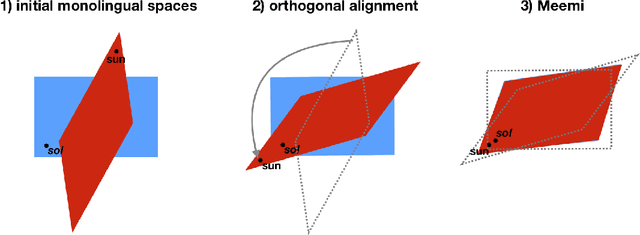
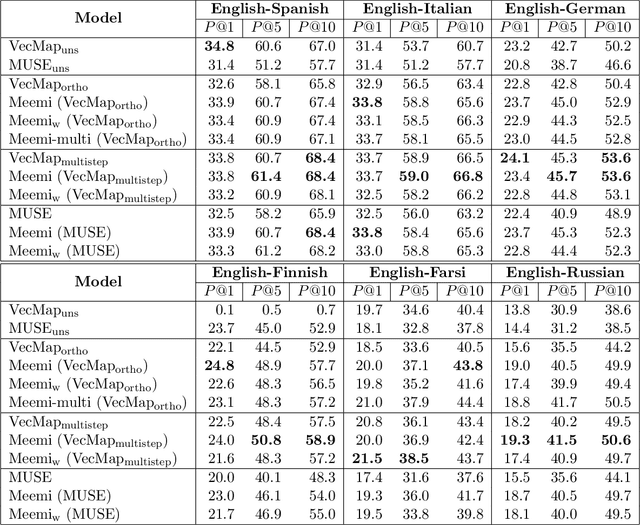
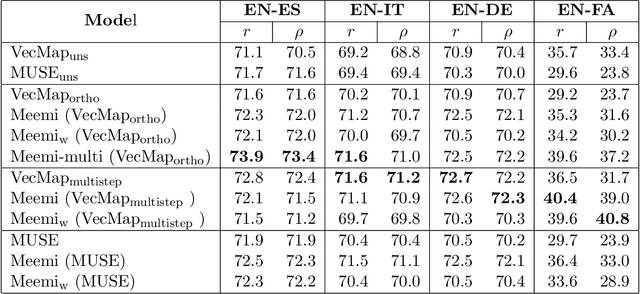
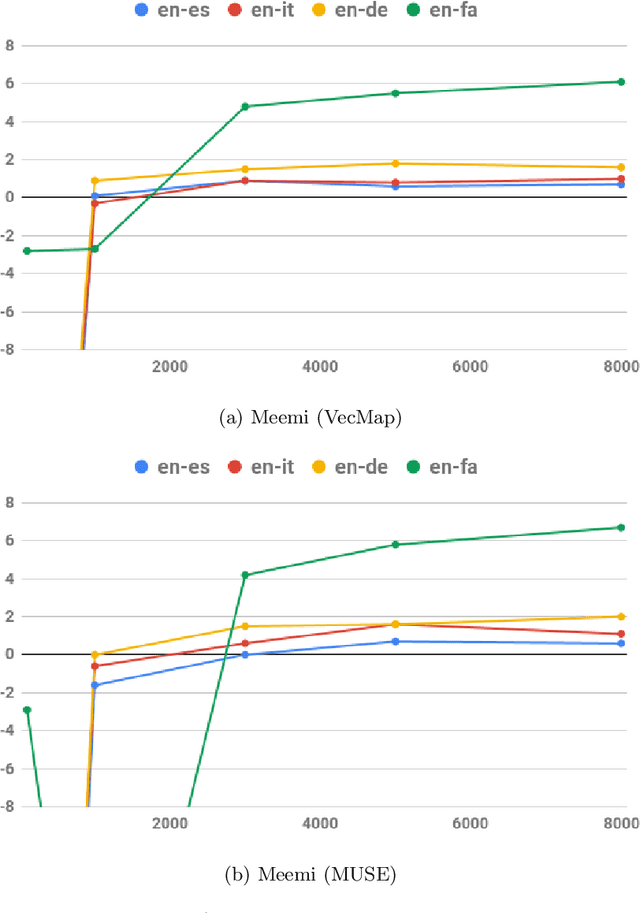
Word embeddings have become a standard resource in the toolset of any Natural Language Processing practitioner. While monolingual word embeddings encode information about words in the context of a particular language, cross-lingual embeddings define a multilingual space where word embeddings from two or more languages are integrated together. Current state-of-the-art approaches learn these embeddings by aligning two disjoint monolingual vector spaces through an orthogonal transformation which preserves the structure of the monolingual counterparts. In this work, we propose to apply an additional transformation after this initial alignment step, which aims to bring the vector representations of a given word and its translations closer to their average. Since this additional transformation is non-orthogonal, it also affects the structure of the monolingual spaces. We show that our approach both improves the integration of the monolingual spaces as well as the quality of the monolingual spaces themselves. Furthermore, because our transformation can be applied to an arbitrary number of languages, we are able to effectively obtain a truly multilingual space. The resulting (monolingual and multilingual) spaces show consistent gains over the current state-of-the-art in standard intrinsic tasks, namely dictionary induction and word similarity, as well as in extrinsic tasks such as cross-lingual hypernym discovery and cross-lingual natural language inference.
On the Robustness of Unsupervised and Semi-supervised Cross-lingual Word Embedding Learning
Aug 21, 2019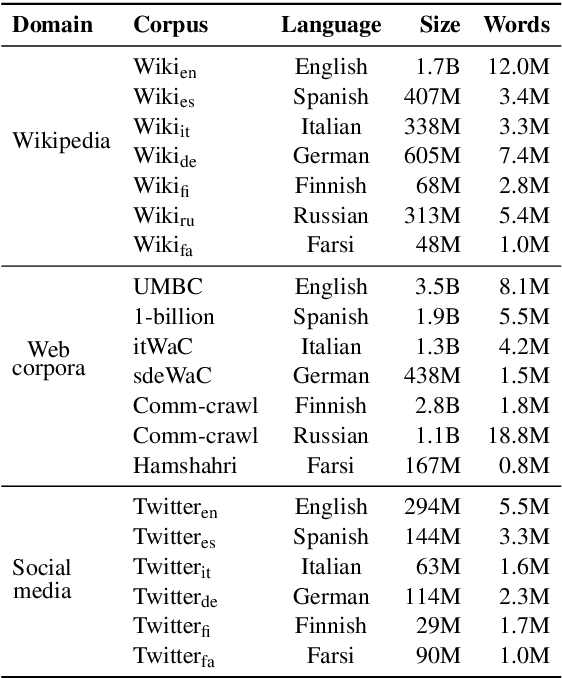
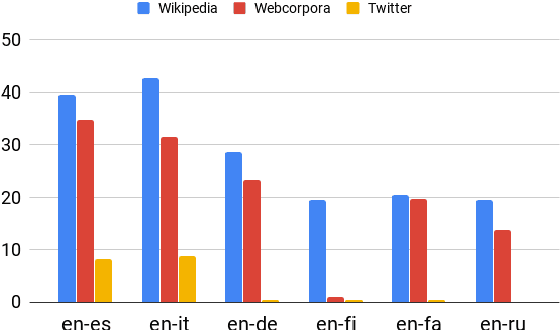
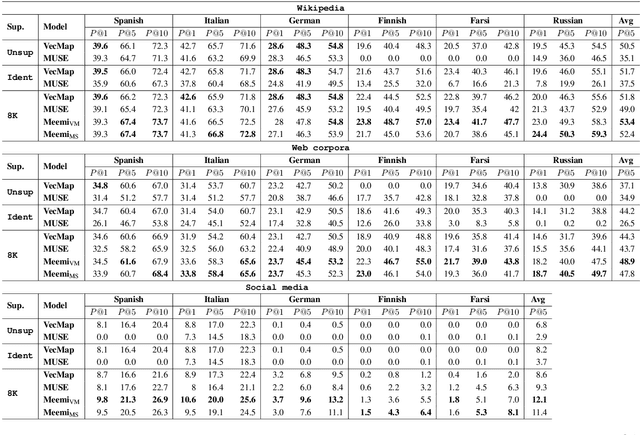

Cross-lingual word embeddings are vector representations of words in different languages where words with similar meaning are represented by similar vectors, regardless of the language. Recent developments which construct these embeddings by aligning monolingual spaces have shown that accurate alignments can be obtained with little or no supervision. However, the focus has been on a particular controlled scenario for evaluation, and there is no strong evidence on how current state-of-the-art systems would fare with noisy text or for language pairs with major linguistic differences. In this paper we present an extensive evaluation over multiple cross-lingual embedding models, analyzing their strengths and limitations with respect to different variables such as target language, training corpora and amount of supervision. Our conclusions put in doubt the view that high-quality cross-lingual embeddings can always be learned without much supervision.
Relational Word Embeddings
Jun 04, 2019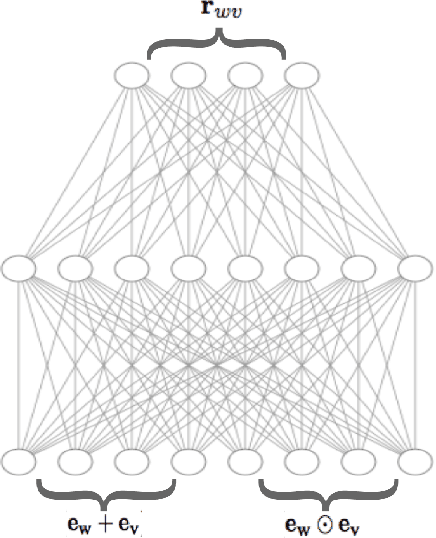
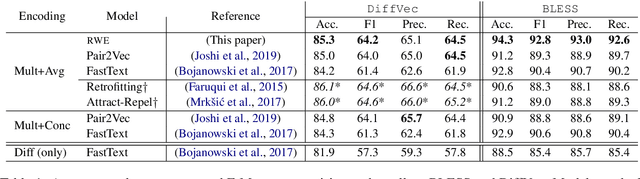
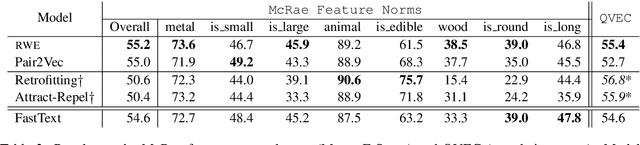
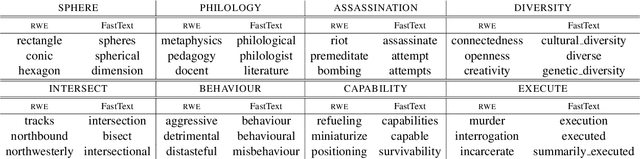
While word embeddings have been shown to implicitly encode various forms of attributional knowledge, the extent to which they capture relational information is far more limited. In previous work, this limitation has been addressed by incorporating relational knowledge from external knowledge bases when learning the word embedding. Such strategies may not be optimal, however, as they are limited by the coverage of available resources and conflate similarity with other forms of relatedness. As an alternative, in this paper we propose to encode relational knowledge in a separate word embedding, which is aimed to be complementary to a given standard word embedding. This relational word embedding is still learned from co-occurrence statistics, and can thus be used even when no external knowledge base is available. Our analysis shows that relational word vectors do indeed capture information that is complementary to what is encoded in standard word embeddings.
Learning Cross-lingual Embeddings from Twitter via Distant Supervision
May 17, 2019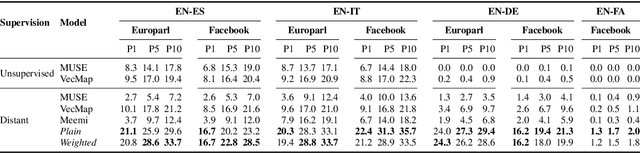
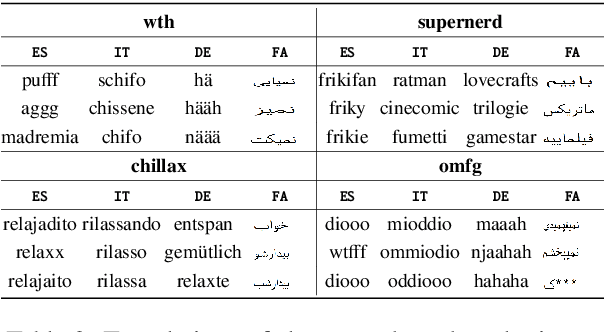
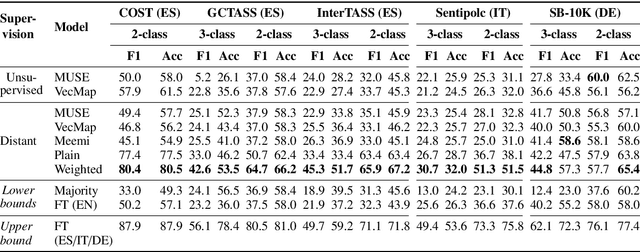
Cross-lingual embeddings represent the meaning of words from different languages in the same vector space. Recent work has shown that it is possible to construct such representations by aligning independently learned monolingual embedding spaces, and that accurate alignments can be obtained even without external bilingual data. In this paper we explore a research direction which has been surprisingly neglected in the literature: leveraging noisy user-generated text to learn cross-lingual embeddings particularly tailored towards social media applications. While the noisiness and informal nature of the social media genre poses additional challenges to cross-lingual embedding methods, we find that it also provides key opportunities due to the abundance of code-switching and the existence of a shared vocabulary of emoji and named entities. Our contribution consists in a very simple post-processing step that exploits these phenomena to significantly improve the performance of state-of-the-art alignment methods.