Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of CAPITEL Shared Tasks at IberLEF 2020: Named Entity Recognition and Universal Dependencies Parsing
Paper and Code
Nov 11, 2020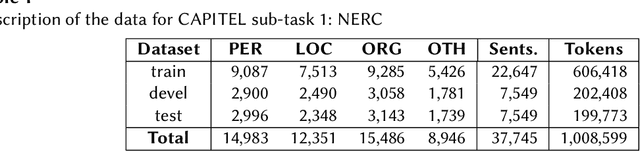
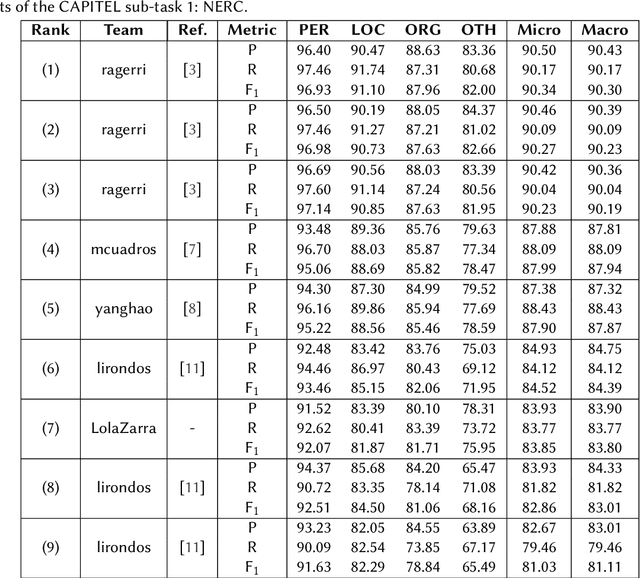
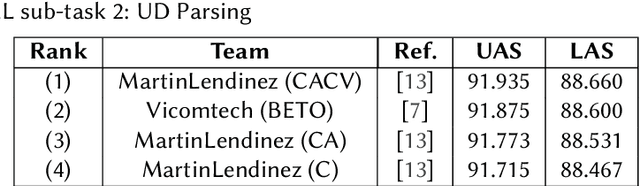
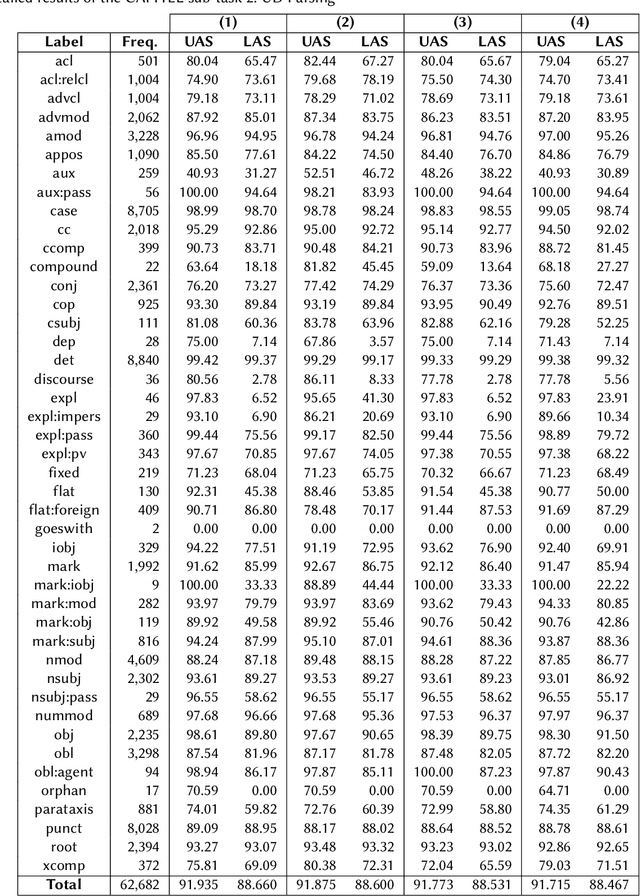
We present the results of the CAPITEL-EVAL shared task, held in the context of the IberLEF 2020 competition series. CAPITEL-EVAL consisted on two subtasks: (1) Named Entity Recognition and Classification and (2) Universal Dependency parsing. For both, the source data was a newly annotated corpus, CAPITEL, a collection of Spanish articles in the newswire domain. A total of seven teams participated in CAPITEL-EVAL, with a total of 13 runs submitted across all subtasks. Data, results and further information about this task can be found at sites.google.com/view/capitel2020.
View paper on