 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing machine learning to reduce ensembles of geological models for oil and gas exploration
Oct 17, 2020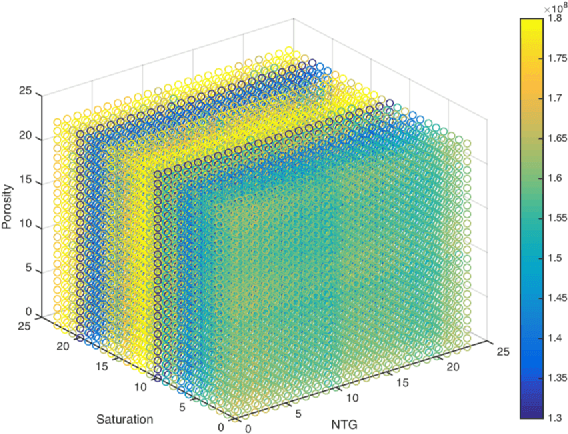
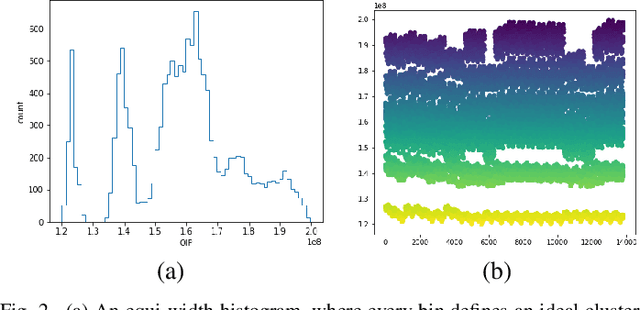
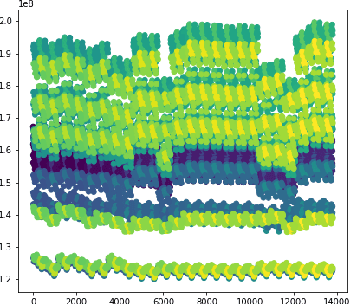
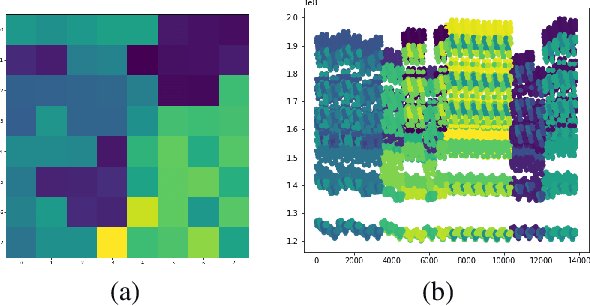
Exploration using borehole drilling is a key activity in determining the most appropriate locations for the petroleum industry to develop oil fields. However, estimating the amount of Oil In Place (OIP) relies on computing with a very significant number of geological models, which, due to the ever increasing capability to capture and refine data, is becoming infeasible. As such, data reduction techniques are required to reduce this set down to a smaller, yet still fully representative ensemble. In this paper we explore different approaches to identifying the key grouping of models, based on their most important features, and then using this information select a reduced set which we can be confident fully represent the overall model space. The result of this work is an approach which enables us to describe the entire state space using only 0.5\% of the models, along with a series of lessons learnt. The techniques that we describe are not only applicable to oil and gas exploration, but also more generally to the HPC community as we are forced to work with reduced data-sets due to the rapid increase in data collection capability.
* Pre-print in 2019 IEEE/ACM 5th International Workshop on Data Analysis and Reduction for Big Scientific Data (DRBSD-5) (pp. 42-49). IEEE
Machine Learning for Gas and Oil Exploration
Oct 04, 2020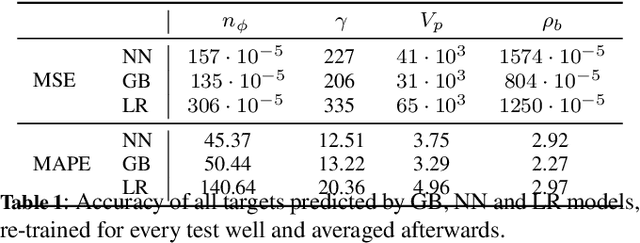
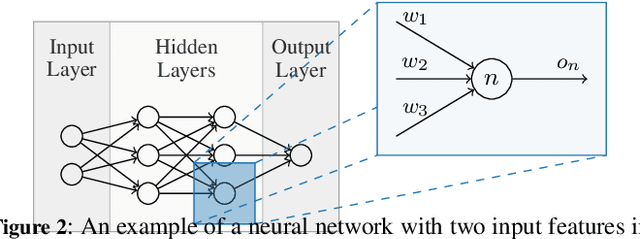
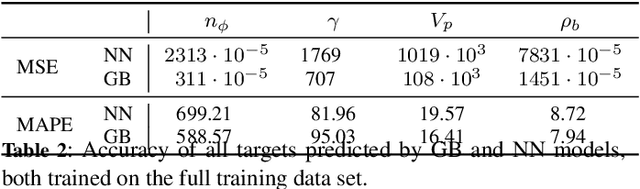
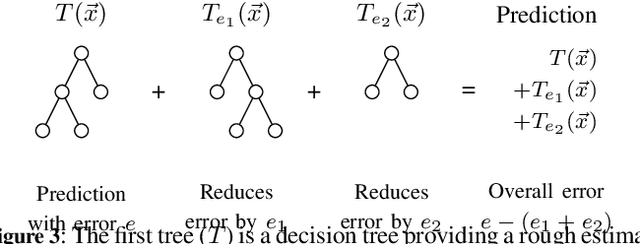
Drilling boreholes for gas and oil extraction is an expensive process and profitability strongly depends on characteristics of the subsurface. As profitability is a key success factor, companies in the industry utilise well logs to explore the subsurface beforehand. These well logs contain various characteristics of the rock around the borehole, which allow petrophysicists to determine the expected amount of contained hydrocarbon. However, these logs are often incomplete and, as a consequence, the subsequent analyses cannot exploit the full potential of the well logs. In this paper we demonstrate that Machine Learning can be applied to \emph{fill in the gaps} and estimate missing values. We investigate how the amount of training data influences the accuracy of prediction and how to best design regression models (Gradient Boosting and neural network) to obtain optimal results. We then explore the models' predictions both quantitatively, tracking the prediction error, and qualitatively, capturing the evolution of the measured and predicted values for a given property with depth. Combining the findings has enabled us to develop a predictive model that completes the well logs, increasing their quality and potential commercial value.