 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical named entity recognition in the Portuguese language: a benchmark of modern BERT models and LLMs
Mar 27, 2026Clinical notes contain valuable unstructured information. Named entity recognition (NER) enables the automatic extraction of medical concepts; however, benchmarks for Portuguese remain scarce. In this study, we aimed to evaluate BERT-based models and large language models (LLMs) for clinical NER in Portuguese and to test strategies for addressing multilabel imbalance. We compared BioBERTpt, BERTimbau, ModernBERT, and mmBERT with LLMs such as GPT-5 and Gemini-2.5, using the public SemClinBr corpus and a private breast cancer dataset. Models were trained under identical conditions and evaluated using precision, recall, and F1-score. Iterative stratification, weighted loss, and oversampling were explored to mitigate class imbalance. The mmBERT-base model achieved the best performance (micro F1 = 0.76), outperforming all other models. Iterative stratification improved class balance and overall performance. Multilingual BERT models, particularly mmBERT, perform strongly for Portuguese clinical NER and can run locally with limited computational resources. Balanced data-splitting strategies further enhance performance.
SemClinBr -- a multi institutional and multi specialty semantically annotated corpus for Portuguese clinical NLP tasks
Jan 27, 2020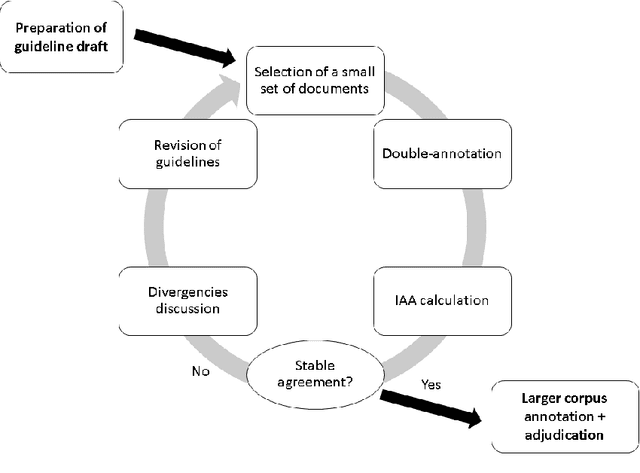
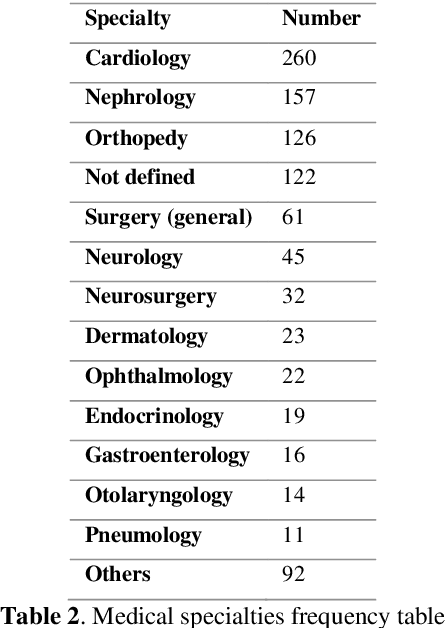
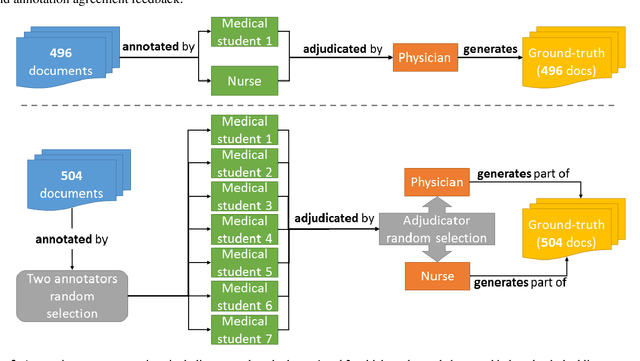
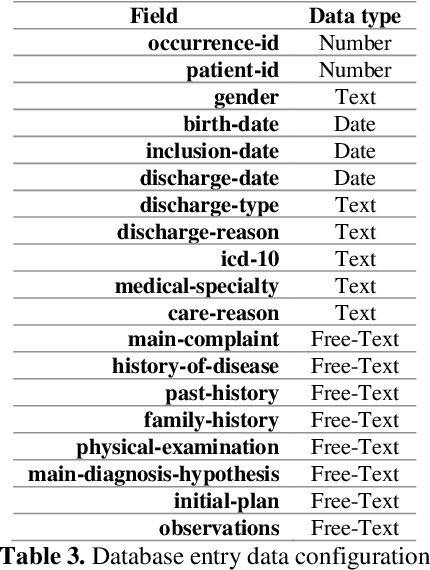
The high volume of research focusing on extracting patient's information from electronic health records (EHR) has led to an increase in the demand for annotated corpora, which are a very valuable resource for both the development and evaluation of natural language processing (NLP) algorithms. The absence of a multi-purpose clinical corpus outside the scope of the English language, especially in Brazilian Portuguese, is glaring and severely impacts scientific progress in the biomedical NLP field. In this study, we developed a semantically annotated corpus using clinical texts from multiple medical specialties, document types, and institutions. We present the following: (1) a survey listing common aspects and lessons learned from previous research, (2) a fine-grained annotation schema which could be replicated and guide other annotation initiatives, (3) a web-based annotation tool focusing on an annotation suggestion feature, and (4) both intrinsic and extrinsic evaluation of the annotations. The result of this work is the SemClinBr, a corpus that has 1,000 clinical notes, labeled with 65,117 entities and 11,263 relations, and can support a variety of clinical NLP tasks and boost the EHR's secondary use for the Portuguese language.