 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogical Team Q-learning: An approach towards factored policies in cooperative MARL
Jun 05, 2020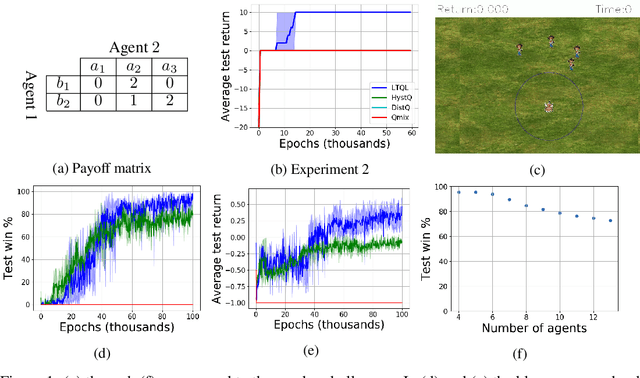
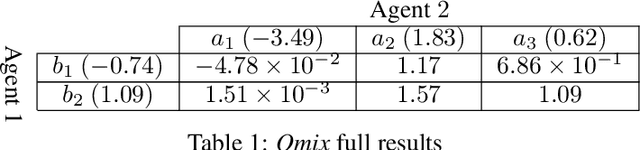
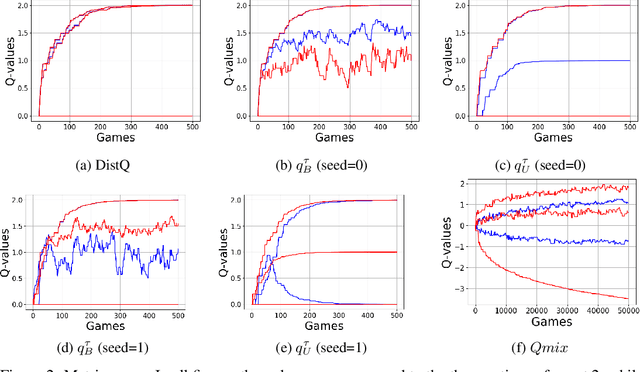
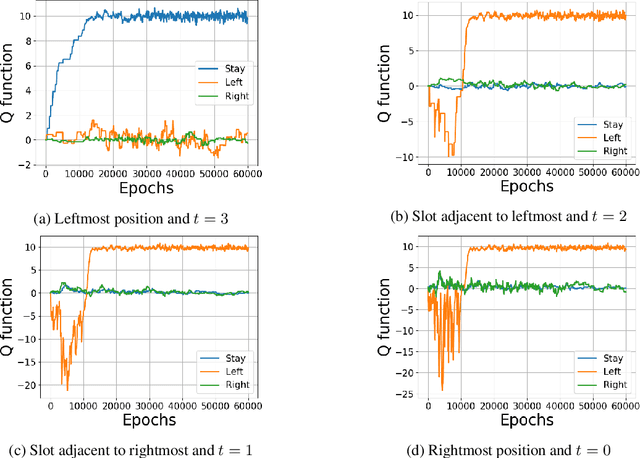
We address the challenge of learning factored policies in cooperative MARL scenarios. In particular, we consider the situation in which a team of agents collaborates to optimize a common cost. Our goal is to obtain factored policies that determine the individual behavior of each agent so that the resulting joint policy is optimal. In this work we make contributions to both the dynamic programming and reinforcement learning settings. In the dynamic programming case we provide a number of lemmas that prove the existence of such factored policies and we introduce an algorithm (along with proof of convergence) that provably leads to them. Then we introduce tabular and deep versions of Logical Team Q-learning, which is a stochastic version of the algorithm for the RL case. We conclude the paper by providing experiments that illustrate the claims.
ISL: Optimal Policy Learning With Optimal Exploration-Exploitation Trade-Off
Sep 13, 2019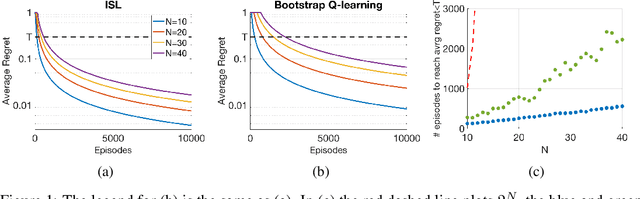
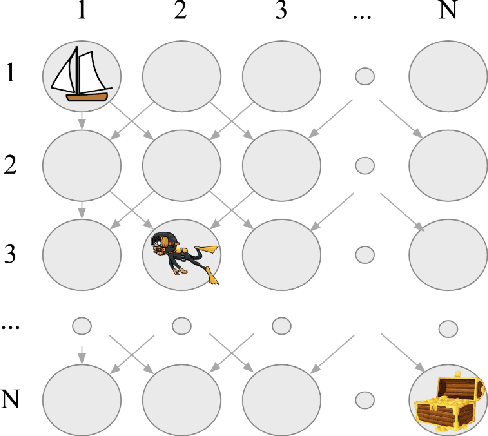
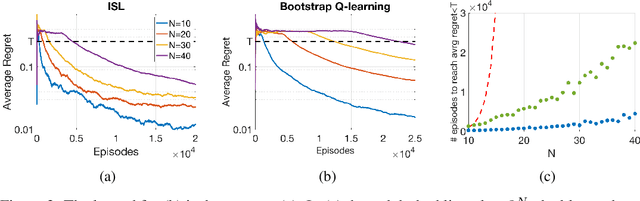
Traditionally, off-policy learning algorithms (such as Q-learning) and exploration schemes have been derived separately. Often times, the exploration-exploitation dilemma being addressed through heuristics. In this article we show that both the learning equations and the exploration-exploitation strategy can be derived in tandem as the solution to a unique and well-posed optimization problem whose minimization leads to the optimal value function. We present a new algorithm following this idea. The algorithm is of the gradient type (and therefore has good convergence properties even when used in conjunction with function approximators such as neural networks); it is off-policy; and it specifies both the update equations and the strategy to address the exploration-exploitation dilemma. To the best of our knowledge, this is the first algorithm that has these properties.
Multi-Agent Fully Decentralized Off-Policy Learning with Linear Convergence Rates
Oct 17, 2018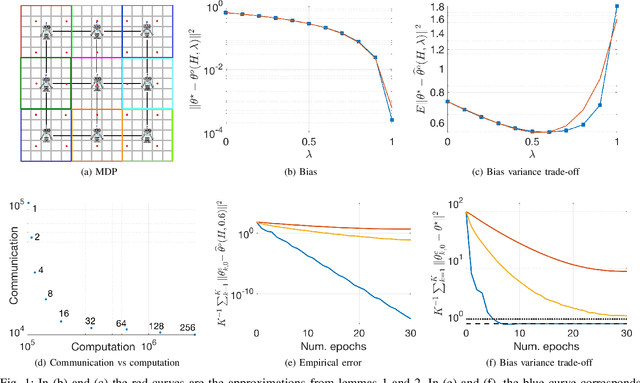
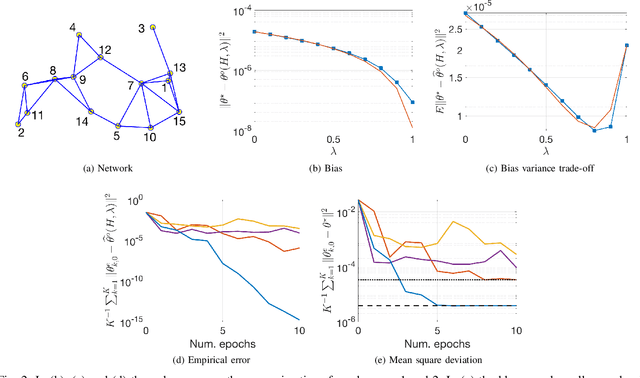
In this paper we develop a fully decentralized algorithm for policy evaluation with off-policy learning, linear function approximation, and $O(n)$ complexity in both computation and memory requirements. The proposed algorithm is of the variance reduced kind and achieves linear convergence. We consider the case where a collection of agents have distinct and fixed size datasets gathered following different behavior policies (none of which is required to explore the full state space) and they all collaborate to evaluate a common target policy. The network approach allows all agents to converge to the optimal solution even in situations where neither agent can converge on its own without cooperation. We provide simulations to illustrate the effectiveness of the method.