 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePnPOOD : Out-Of-Distribution Detection for Text Classification via Plug andPlay Data Augmentation
Oct 31, 2021
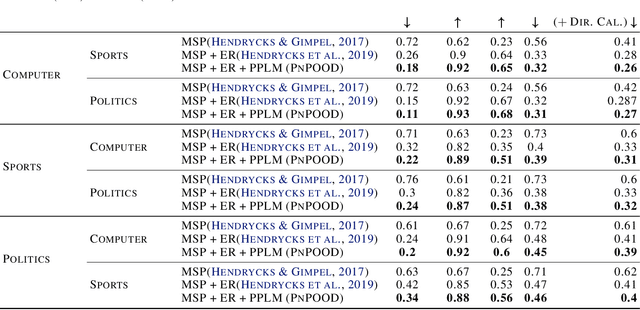
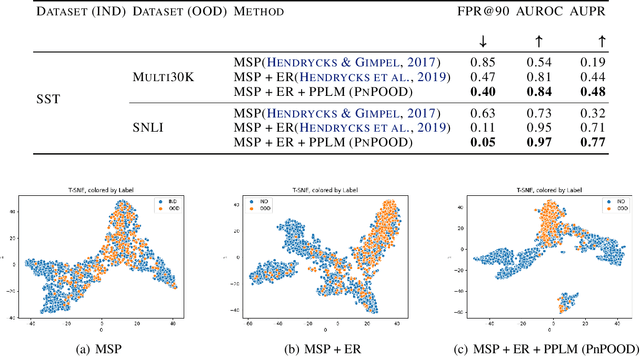
While Out-of-distribution (OOD) detection has been well explored in computer vision, there have been relatively few prior attempts in OOD detection for NLP classification. In this paper we argue that these prior attempts do not fully address the OOD problem and may suffer from data leakage and poor calibration of the resulting models. We present PnPOOD, a data augmentation technique to perform OOD detection via out-of-domain sample generation using the recently proposed Plug and Play Language Model (Dathathri et al., 2020). Our method generates high quality discriminative samples close to the class boundaries, resulting in accurate OOD detection at test time. We demonstrate that our model outperforms prior models on OOD sample detection, and exhibits lower calibration error on the 20 newsgroup text and Stanford Sentiment Treebank dataset (Lang, 1995; Socheret al., 2013). We further highlight an important data leakage issue with datasets used in prior attempts at OOD detection, and share results on a new dataset for OOD detection that does not suffer from the same problem.
Using Program Synthesis and Inductive Logic Programming to solve Bongard Problems
Oct 19, 2021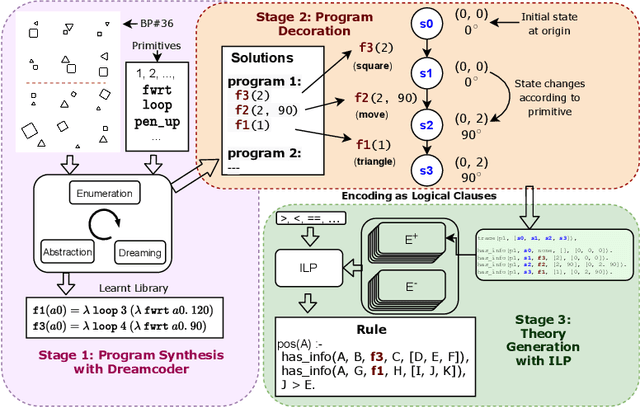

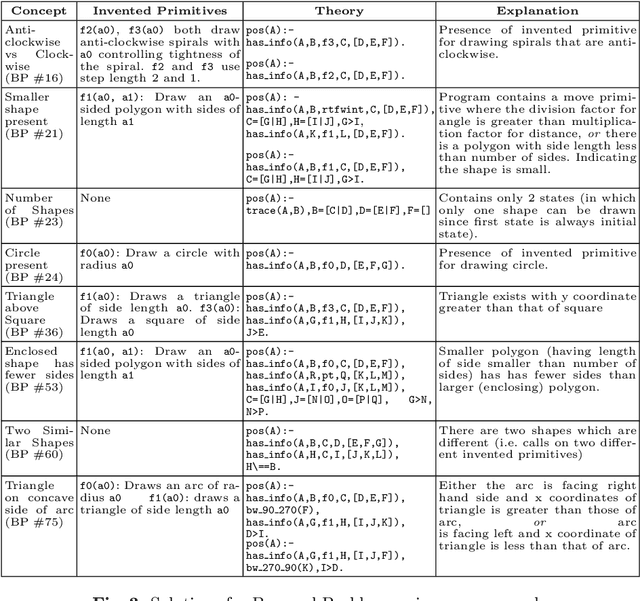
The ability to recognise and make analogies is often used as a measure or test of human intelligence. The ability to solve Bongard problems is an example of such a test. It has also been postulated that the ability to rapidly construct novel abstractions is critical to being able to solve analogical problems. Given an image, the ability to construct a program that would generate that image is one form of abstraction, as exemplified in the Dreamcoder project. In this paper, we present a preliminary examination of whether programs constructed by Dreamcoder can be used for analogical reasoning to solve certain Bongard problems. We use Dreamcoder to discover programs that generate the images in a Bongard problem and represent each of these as a sequence of state transitions. We decorate the states using positional information in an automated manner and then encode the resulting sequence into logical facts in Prolog. We use inductive logic programming (ILP), to learn an (interpretable) theory for the abstract concept involved in an instance of a Bongard problem. Experiments on synthetically created Bongard problems for concepts such as 'above/below' and 'clockwise/counterclockwise' demonstrate that our end-to-end system can solve such problems. We study the importance and completeness of each component of our approach, highlighting its current limitations and pointing to directions for improvement in our formulation as well as in elements of any Dreamcoder-like program synthesis system used for such an approach.
OSSR-PID: One-Shot Symbol Recognition in P&ID Sheets using Path Sampling and GCN
Sep 08, 2021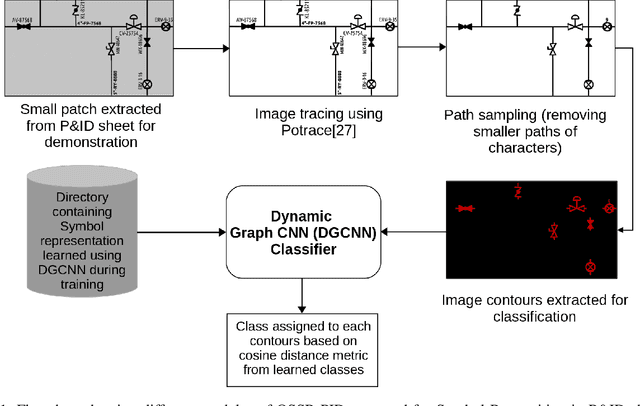

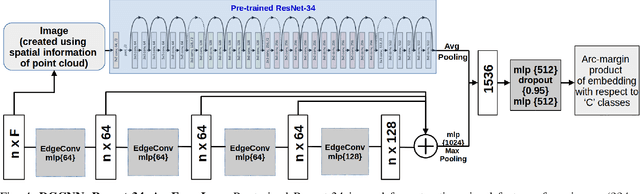
Piping and Instrumentation Diagrams (P&ID) are ubiquitous in several manufacturing, oil and gas enterprises for representing engineering schematics and equipment layout. There is an urgent need to extract and digitize information from P&IDs without the cost of annotating a varying set of symbols for each new use case. A robust one-shot learning approach for symbol recognition i.e., localization followed by classification, would therefore go a long way towards this goal. Our method works by sampling pixels sequentially along the different contour boundaries in the image. These sampled points form paths which are used in the prototypical line diagram to construct a graph that captures the structure of the contours. Subsequently, the prototypical graphs are fed into a Dynamic Graph Convolutional Neural Network (DGCNN) which is trained to classify graphs into one of the given symbol classes. Further, we append embeddings from a Resnet-34 network which is trained on symbol images containing sampled points to make the classification network more robust. Since, many symbols in P&ID are structurally very similar to each other, we utilize Arcface loss during DGCNN training which helps in maximizing symbol class separability by producing highly discriminative embeddings. The images consist of components attached on the pipeline (straight line). The sampled points segregated around the symbol regions are used for the classification task. The proposed pipeline, named OSSR-PID, is fast and gives outstanding performance for recognition of symbols on a synthetic dataset of 100 P&ID diagrams. We also compare our method against prior-work on a real-world private dataset of 12 P&ID sheets and obtain comparable/superior results. Remarkably, it is able to achieve such excellent performance using only one prototypical example per symbol.
Digitize-PID: Automatic Digitization of Piping and Instrumentation Diagrams
Sep 08, 2021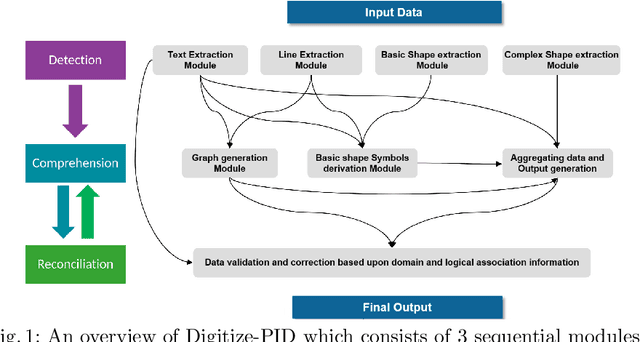
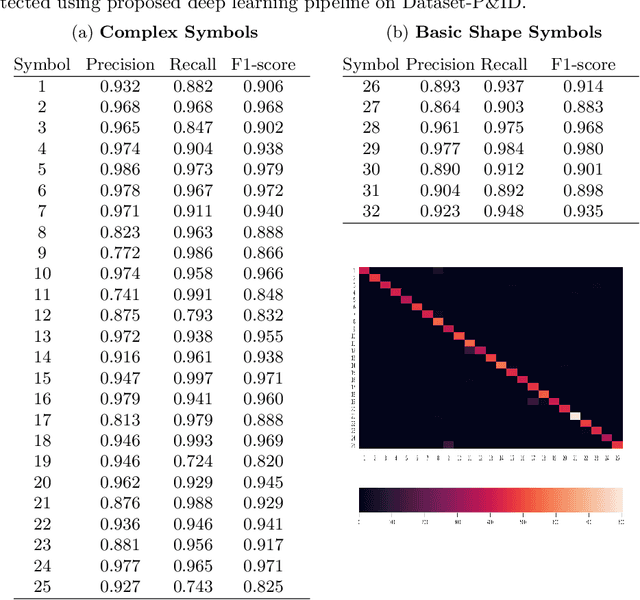
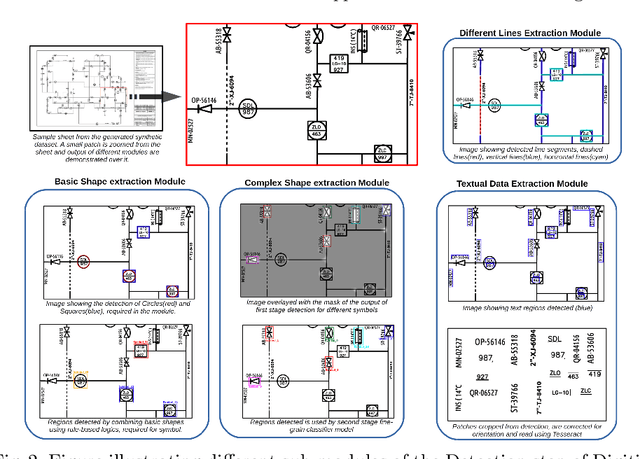
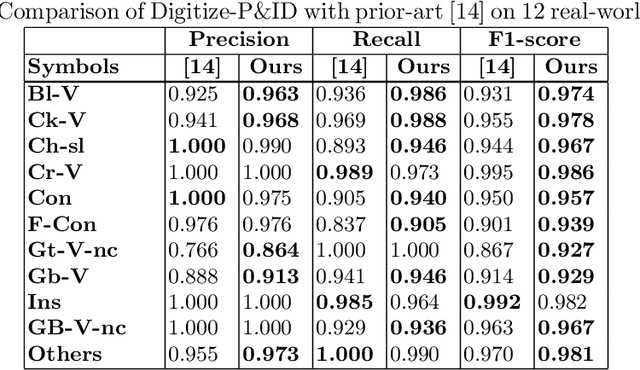
Digitization of scanned Piping and Instrumentation diagrams(P&ID), widely used in manufacturing or mechanical industries such as oil and gas over several decades, has become a critical bottleneck in dynamic inventory management and creation of smart P&IDs that are compatible with the latest CAD tools. Historically, P&ID sheets have been manually generated at the design stage, before being scanned and stored as PDFs. Current digitization initiatives involve manual processing and are consequently very time consuming, labour intensive and error-prone.Thanks to advances in image processing, machine and deep learning techniques there are emerging works on P&ID digitization. However, existing solutions face several challenges owing to the variation in the scale, size and noise in the P&IDs, sheer complexity and crowdedness within drawings, domain knowledge required to interpret the drawings. This motivates our current solution called Digitize-PID which comprises of an end-to-end pipeline for detection of core components from P&IDs like pipes, symbols and textual information, followed by their association with each other and eventually, the validation and correction of output data based on inherent domain knowledge. A novel and efficient kernel-based line detection and a two-step method for detection of complex symbols based on a fine-grained deep recognition technique is presented in the paper. In addition, we have created an annotated synthetic dataset, Dataset-P&ID, of 500 P&IDs by incorporating different types of noise and complex symbols which is made available for public use (currently there exists no public P&ID dataset). We evaluate our proposed method on this synthetic dataset and a real-world anonymized private dataset of 12 P&ID sheets. Results show that Digitize-PID outperforms the existing state-of-the-art for P&ID digitization.
* 13 pages
CAMTA: Casual Attention Model for Multi-touch Attribution
Dec 21, 2020
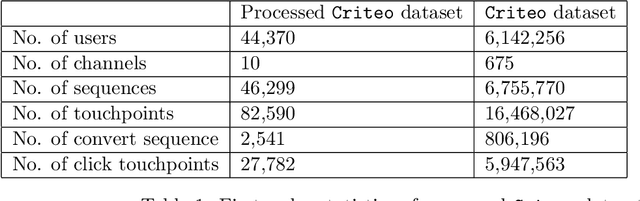
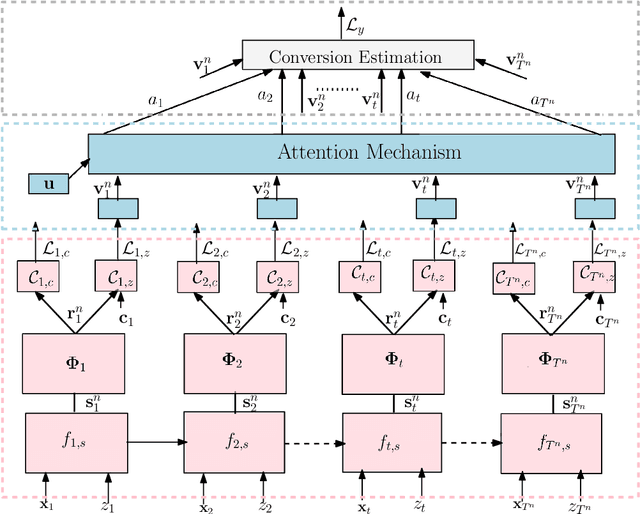
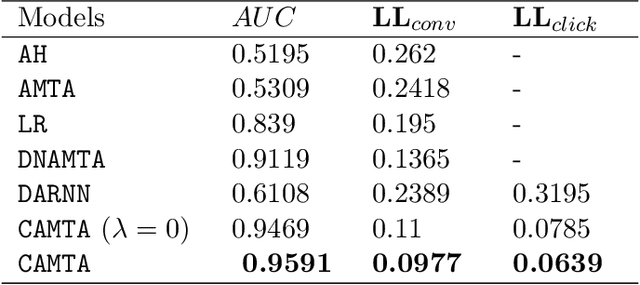
Advertising channels have evolved from conventional print media, billboards and radio advertising to online digital advertising (ad), where the users are exposed to a sequence of ad campaigns via social networks, display ads, search etc. While advertisers revisit the design of ad campaigns to concurrently serve the requirements emerging out of new ad channels, it is also critical for advertisers to estimate the contribution from touch-points (view, clicks, converts) on different channels, based on the sequence of customer actions. This process of contribution measurement is often referred to as multi-touch attribution (MTA). In this work, we propose CAMTA, a novel deep recurrent neural network architecture which is a casual attribution mechanism for user-personalised MTA in the context of observational data. CAMTA minimizes the selection bias in channel assignment across time-steps and touchpoints. Furthermore, it utilizes the users' pre-conversion actions in a principled way in order to predict pre-channel attribution. To quantitatively benchmark the proposed MTA model, we employ the real world Criteo dataset and demonstrate the superior performance of CAMTA with respect to prediction accuracy as compared to several baselines. In addition, we provide results for budget allocation and user-behaviour modelling on the predicted channel attribution.
Constructing and Evaluating an Explainable Model for COVID-19 Diagnosis from Chest X-rays
Dec 19, 2020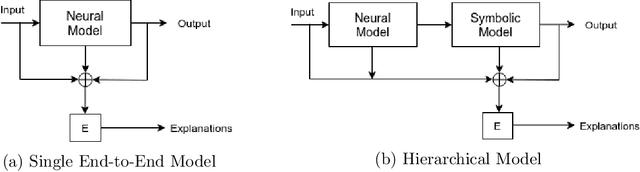
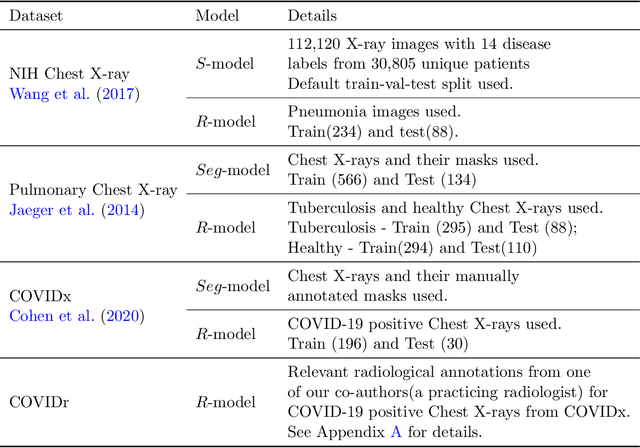
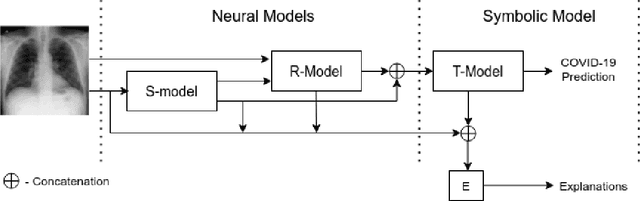
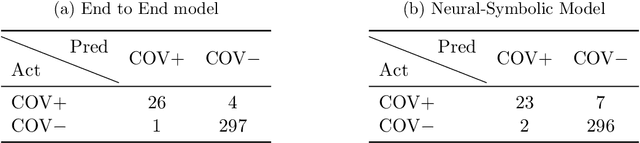
In this paper, our focus is on constructing models to assist a clinician in the diagnosis of COVID-19 patients in situations where it is easier and cheaper to obtain X-ray data than to obtain high-quality images like those from CT scans. Deep neural networks have repeatedly been shown to be capable of constructing highly predictive models for disease detection directly from image data. However, their use in assisting clinicians has repeatedly hit a stumbling block due to their black-box nature. Some of this difficulty can be alleviated if predictions were accompanied by explanations expressed in clinically relevant terms. In this paper, deep neural networks are used to extract domain-specific features(morphological features like ground-glass opacity and disease indications like pneumonia) directly from the image data. Predictions about these features are then used to construct a symbolic model (a decision tree) for the diagnosis of COVID-19 from chest X-rays, accompanied with two kinds of explanations: visual (saliency maps, derived from the neural stage), and textual (logical descriptions, derived from the symbolic stage). A radiologist rates the usefulness of the visual and textual explanations. Our results demonstrate that neural models can be employed usefully in identifying domain-specific features from low-level image data; that textual explanations in terms of clinically relevant features may be useful; and that visual explanations will need to be clinically meaningful to be useful.
Batch-Constrained Distributional Reinforcement Learning for Session-based Recommendation
Dec 16, 2020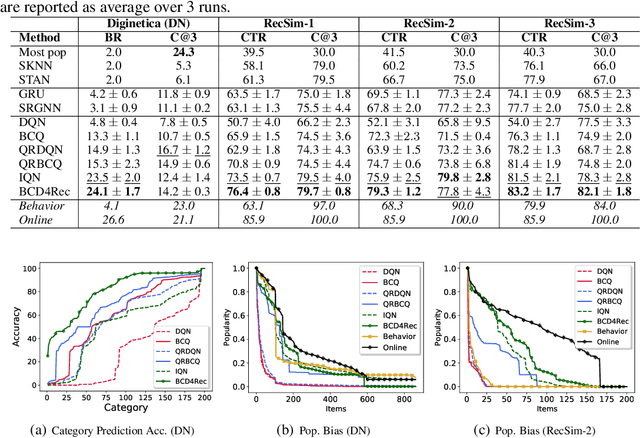
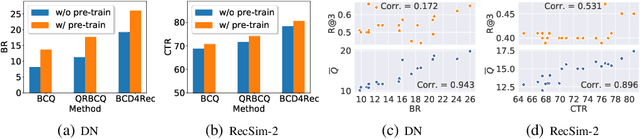

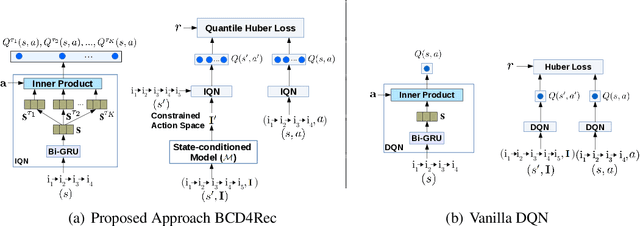
Most of the existing deep reinforcement learning (RL) approaches for session-based recommendations either rely on costly online interactions with real users, or rely on potentially biased rule-based or data-driven user-behavior models for learning. In this work, we instead focus on learning recommendation policies in the pure batch or offline setting, i.e. learning policies solely from offline historical interaction logs or batch data generated from an unknown and sub-optimal behavior policy, without further access to data from the real-world or user-behavior models. We propose BCD4Rec: Batch-Constrained Distributional RL for Session-based Recommendations. BCD4Rec builds upon the recent advances in batch (offline) RL and distributional RL to learn from offline logs while dealing with the intrinsically stochastic nature of rewards from the users due to varied latent interest preferences (environments). We demonstrate that BCD4Rec significantly improves upon the behavior policy as well as strong RL and non-RL baselines in the batch setting in terms of standard performance metrics like Click Through Rates or Buy Rates. Other useful properties of BCD4Rec include: i. recommending items from the correct latent categories indicating better value estimates despite large action space (of the order of number of items), and ii. overcoming popularity bias in clicked or bought items typically present in the offline logs.
Incorporating Symbolic Domain Knowledge into Graph Neural Networks
Oct 23, 2020
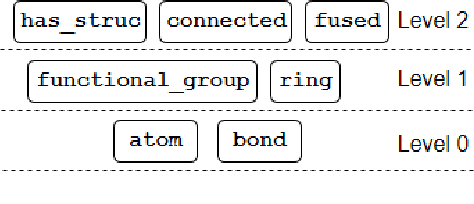
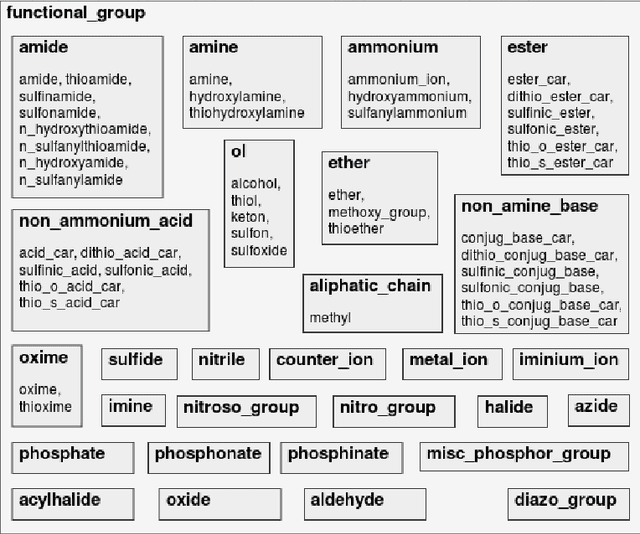
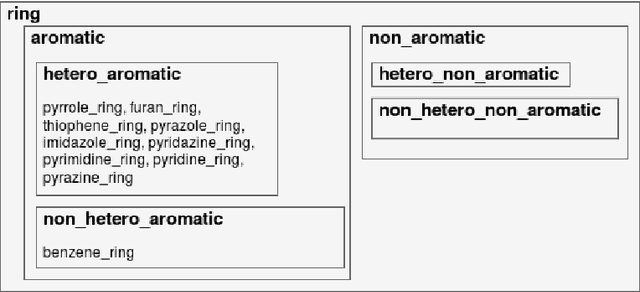
Our interest is in scientific problems with the following characteristics: (1) Data are naturally represented as graphs; (2) The amount of data available is typically small; and (3) There is significant domain-knowledge, usually expressed in some symbolic form. These kinds of problems have been addressed effectively in the past by Inductive Logic Programming (ILP), by virtue of 2 important characteristics: (a) The use of a representation language that easily captures the relation encoded in graph-structured data, and (b) The inclusion of prior information encoded as domain-specific relations, that can alleviate problems of data scarcity, and construct new relations. Recent advances have seen the emergence of deep neural networks specifically developed for graph-structured data (Graph-based Neural Networks, or GNNs). While GNNs have been shown to be able to handle graph-structured data, less has been done to investigate the inclusion of domain-knowledge. Here we investigate this aspect of GNNs empirically by employing an operation we term "vertex-enrichment" and denote the corresponding GNNs as "VEGNNs". Using over 70 real-world datasets and substantial amounts of symbolic domain-knowledge, we examine the result of vertex-enrichment across 5 different variants of GNNs. Our results provide support for the following: (a) Inclusion of domain-knowledge by vertex-enrichment can significantly improve the performance of a GNN. That is, the performance VEGNNs is significantly better than GNNs across all GNN variants; (b) The inclusion of domain-specific relations constructed using ILP improves the performance of VEGNNs, across all GNN variants. Taken together, the results provide evidence that it is possible to incorporate symbolic domain knowledge into a GNN, and that ILP can play an important role in providing high-level relationships that are not easily discovered by a GNN.
Hi-CI: Deep Causal Inference in High Dimensions
Aug 22, 2020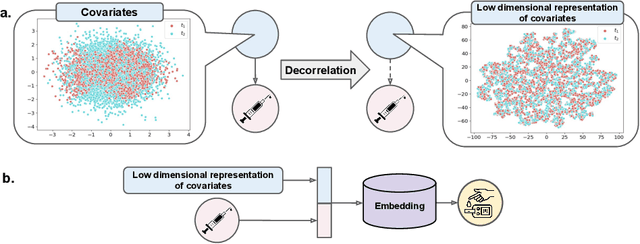
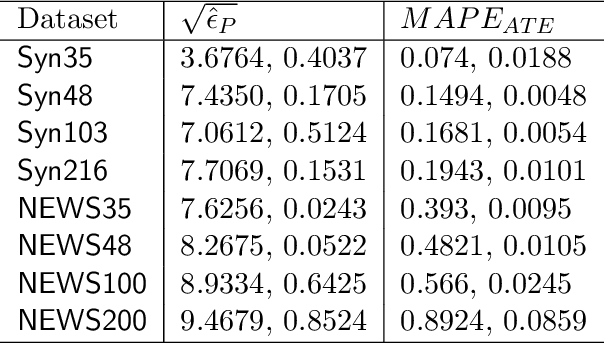
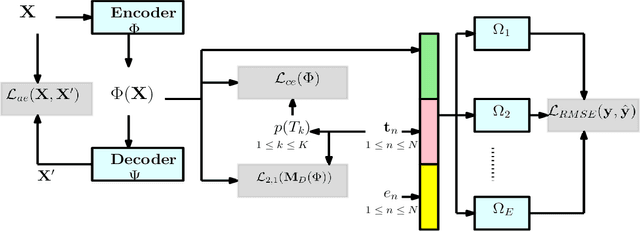
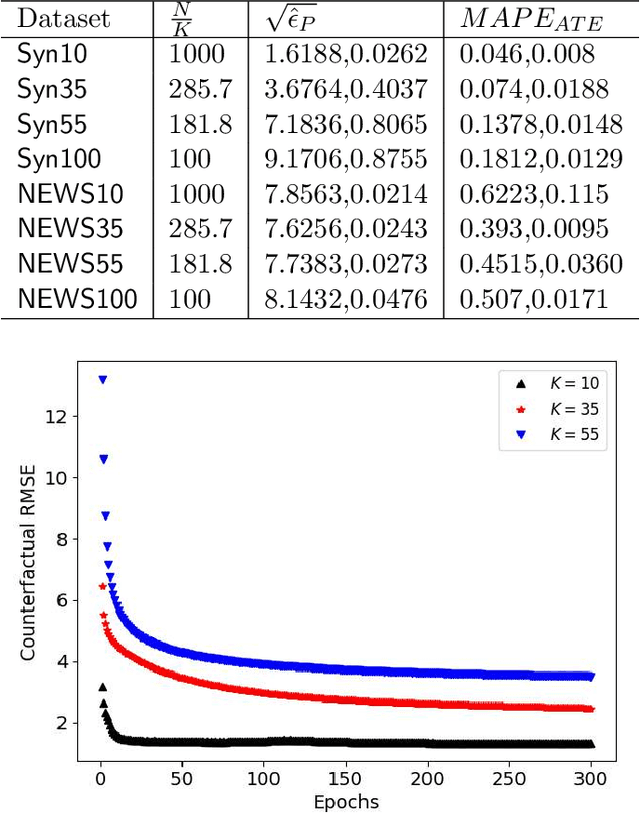
We address the problem of counterfactual regression using causal inference (CI) in observational studies consisting of high dimensional covariates and high cardinality treatments. Confounding bias, which leads to inaccurate treatment effect estimation, is attributed to covariates that affect both treatments and outcome. The presence of high-dimensional co-variates exacerbates the impact of bias as it is harder to isolate and measure the impact of these confounders. In the presence of high-cardinality treatment variables, CI is rendered ill-posed due to the increase in the number of counterfactual outcomes to be predicted. We propose Hi-CI, a deep neural network (DNN) based framework for estimating causal effects in the presence of large number of covariates, and high-cardinal and continuous treatment variables. The proposed architecture comprises of a decorrelation network and an outcome prediction network. In the decorrelation network, we learn a data representation in lower dimensions as compared to the original covariates and addresses confounding bias alongside. Subsequently, in the outcome prediction network, we learn an embedding of high-cardinality and continuous treatments, jointly with the data representation. We demonstrate the efficacy of causal effect prediction of the proposed Hi-CI network using synthetic and real-world NEWS datasets.
Handling Variable-Dimensional Time Series with Graph Neural Networks
Jul 07, 2020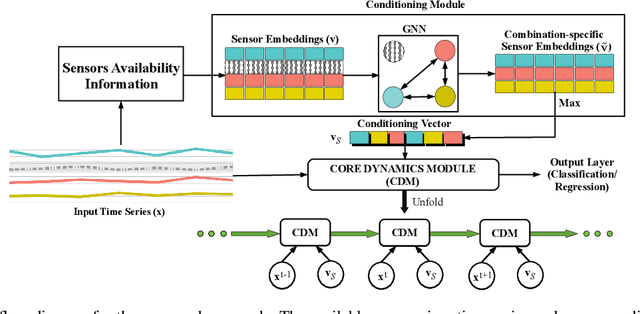
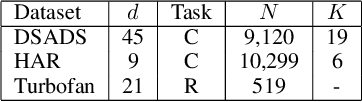
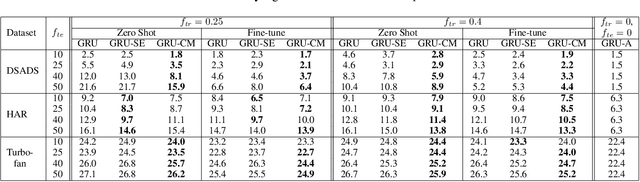
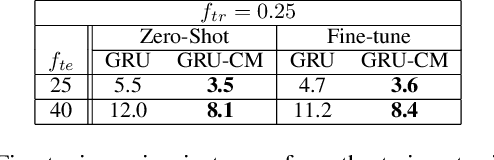
Several applications of Internet of Things (IoT) technology involve capturing data from multiple sensors resulting in multi-sensor time series. Existing neural networks based approaches for such multi-sensor or multivariate time series modeling assume fixed input dimension or number of sensors. Such approaches can struggle in the practical setting where different instances of the same device or equipment such as mobiles, wearables, engines, etc. come with different combinations of installed sensors. We consider training neural network models from such multi-sensor time series, where the time series have varying input dimensionality owing to availability or installation of a different subset of sensors at each source of time series. We propose a novel neural network architecture suitable for zero-shot transfer learning allowing robust inference for multivariate time series with previously unseen combination of available dimensions or sensors at test time. Such a combinatorial generalization is achieved by conditioning the layers of a core neural network-based time series model with a "conditioning vector" that carries information of the available combination of sensors for each time series. This conditioning vector is obtained by summarizing the set of learned "sensor embedding vectors" corresponding to the available sensors in a time series via a graph neural network. We evaluate the proposed approach on publicly available activity recognition and equipment prognostics datasets, and show that the proposed approach allows for better generalization in comparison to a deep gated recurrent neural network baseline.