 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-based Analogical Reasoning in Neuro-symbolic Latent Spaces
Sep 19, 2022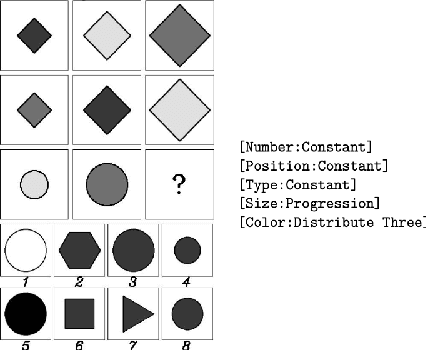
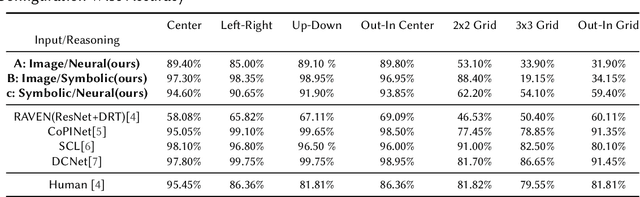
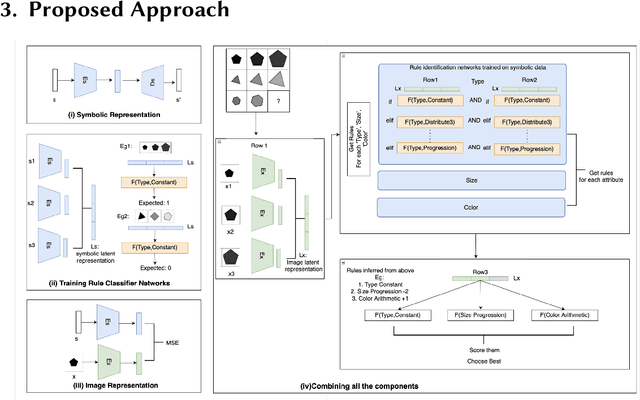
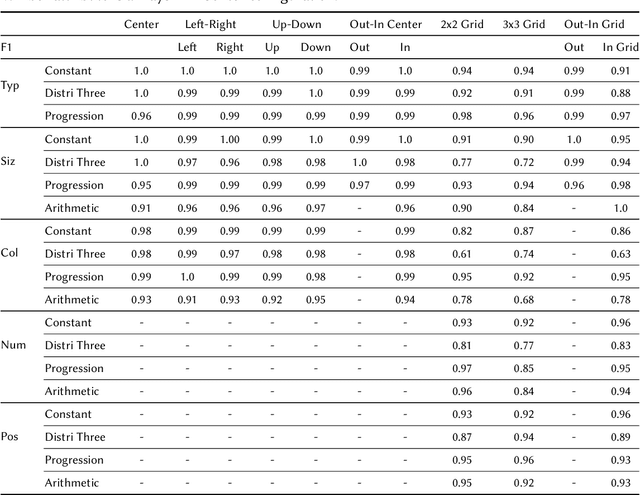
Analogical Reasoning problems challenge both connectionist and symbolic AI systems as these entail a combination of background knowledge, reasoning and pattern recognition. While symbolic systems ingest explicit domain knowledge and perform deductive reasoning, they are sensitive to noise and require inputs be mapped to preset symbolic features. Connectionist systems on the other hand can directly ingest rich input spaces such as images, text or speech and recognize pattern even with noisy inputs. However, connectionist models struggle to include explicit domain knowledge for deductive reasoning. In this paper, we propose a framework that combines the pattern recognition abilities of neural networks with symbolic reasoning and background knowledge for solving a class of Analogical Reasoning problems where the set of attributes and possible relations across them are known apriori. We take inspiration from the 'neural algorithmic reasoning' approach [DeepMind 2020] and use problem-specific background knowledge by (i) learning a distributed representation based on a symbolic model of the problem (ii) training neural-network transformations reflective of the relations involved in the problem and finally (iii) training a neural network encoder from images to the distributed representation in (i). These three elements enable us to perform search-based reasoning using neural networks as elementary functions manipulating distributed representations. We test this on visual analogy problems in RAVENs Progressive Matrices, and achieve accuracy competitive with human performance and, in certain cases, superior to initial end-to-end neural-network based approaches. While recent neural models trained at scale yield SOTA, our novel neuro-symbolic reasoning approach is a promising direction for this problem, and is arguably more general, especially for problems where domain knowledge is available.
On NeuroSymbolic Solutions for PDEs
Jul 11, 2022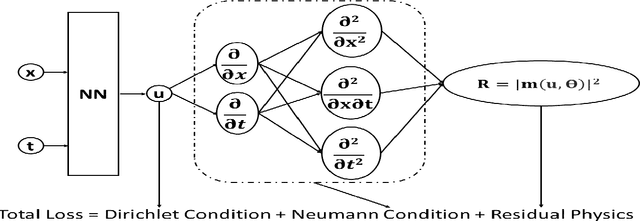
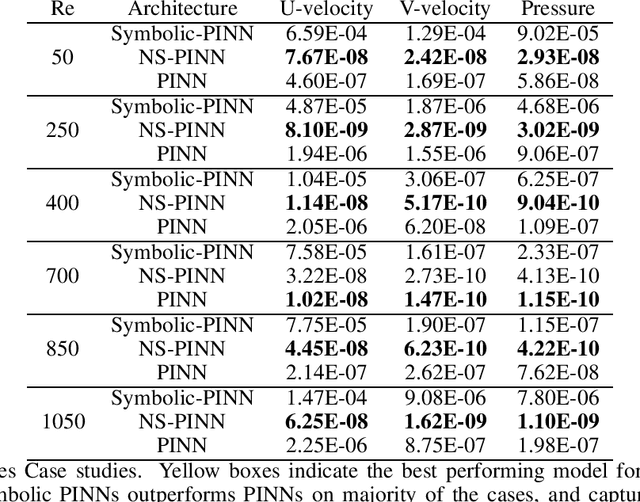
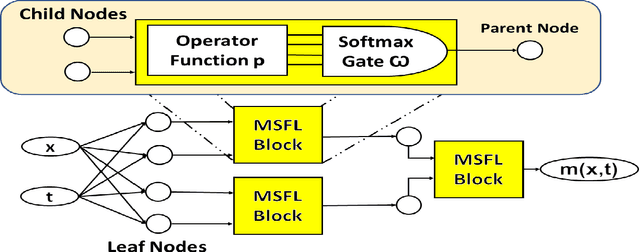
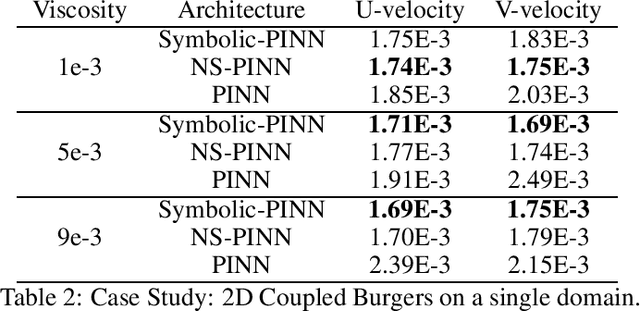
Physics Informed Neural Networks (PINNs) have gained immense popularity as an alternate method for numerically solving PDEs. Despite their empirical success we are still building an understanding of the convergence properties of training on such constraints with gradient descent. It is known that, in the absence of an explicit inductive bias, Neural Networks can struggle to learn or approximate even simple and well known functions in a sample efficient manner. Thus the numerical approximation induced from few collocation points may not generalize over the entire domain. Meanwhile, a symbolic form can exhibit good generalization, with interpretability as a useful byproduct. However, symbolic approximations can struggle to simultaneously be concise and accurate. Therefore in this work we explore a NeuroSymbolic approach to approximate the solution for PDEs. We observe that our approach work for several simple cases. We illustrate the efficacy of our approach on Navier Stokes: Kovasznay flow where there are multiple physical quantities of interest governed with non-linear coupled PDE system. Domain splitting is now becoming a popular trick to help PINNs approximate complex functions. We observe that a NeuroSymbolic approach can help such complex functions as well. We demonstrate Domain-splitting assisted NeuroSymbolic approach on a temporally varying two-dimensional Burger's equation. Finally we consider the scenario where PINNs have to be solved for parameterized PDEs, for changing Initial-Boundary Conditions and changes in the coefficient of the PDEs. Hypernetworks have shown to hold promise to overcome these challenges. We show that one can design Hyper-NeuroSymbolic Networks which can combine the benefits of speed and increased accuracy. We observe that that the NeuroSymbolic approximations are consistently 1-2 order of magnitude better than just the neural or symbolic approximations.
An Efficient Anchor-free Universal Lesion Detection in CT-scans
Mar 30, 2022
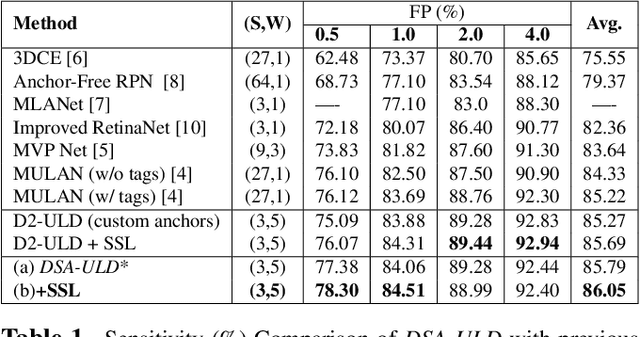
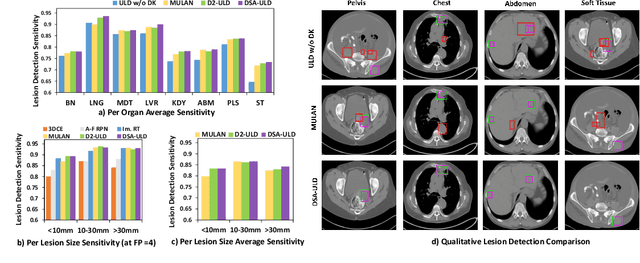
Existing universal lesion detection (ULD) methods utilize compute-intensive anchor-based architectures which rely on predefined anchor boxes, resulting in unsatisfactory detection performance, especially in small and mid-sized lesions. Further, these default fixed anchor-sizes and ratios do not generalize well to different datasets. Therefore, we propose a robust one-stage anchor-free lesion detection network that can perform well across varying lesions sizes by exploiting the fact that the box predictions can be sorted for relevance based on their center rather than their overlap with the object. Furthermore, we demonstrate that the ULD can be improved by explicitly providing it the domain-specific information in the form of multi-intensity images generated using multiple HU windows, followed by self-attention based feature-fusion and backbone initialization using weights learned via self-supervision over CT-scans. We obtain comparable results to the state-of-the-art methods, achieving an overall sensitivity of 86.05% on the DeepLesion dataset, which comprises of approximately 32K CT-scans with lesions annotated across various body organs.
* 4 Pages, 2 figures, 2 tables. Paper accepted at IEEE International Symposium on Biomedical Imaging (ISBI'22)
DKMA-ULD: Domain Knowledge augmented Multi-head Attention based Robust Universal Lesion Detection
Mar 14, 2022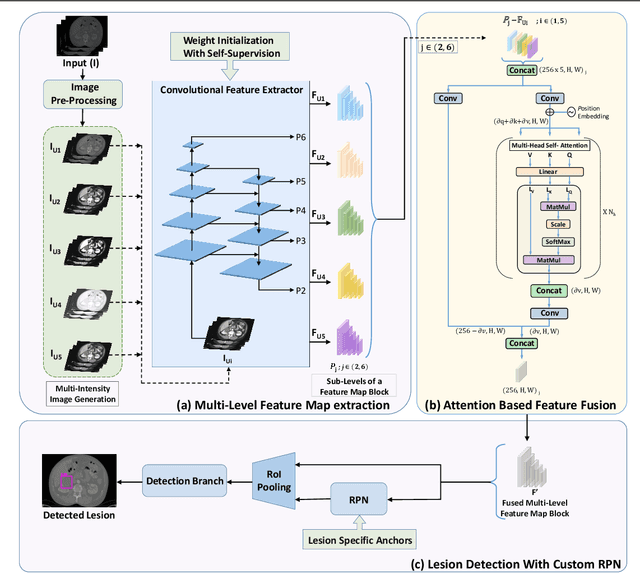
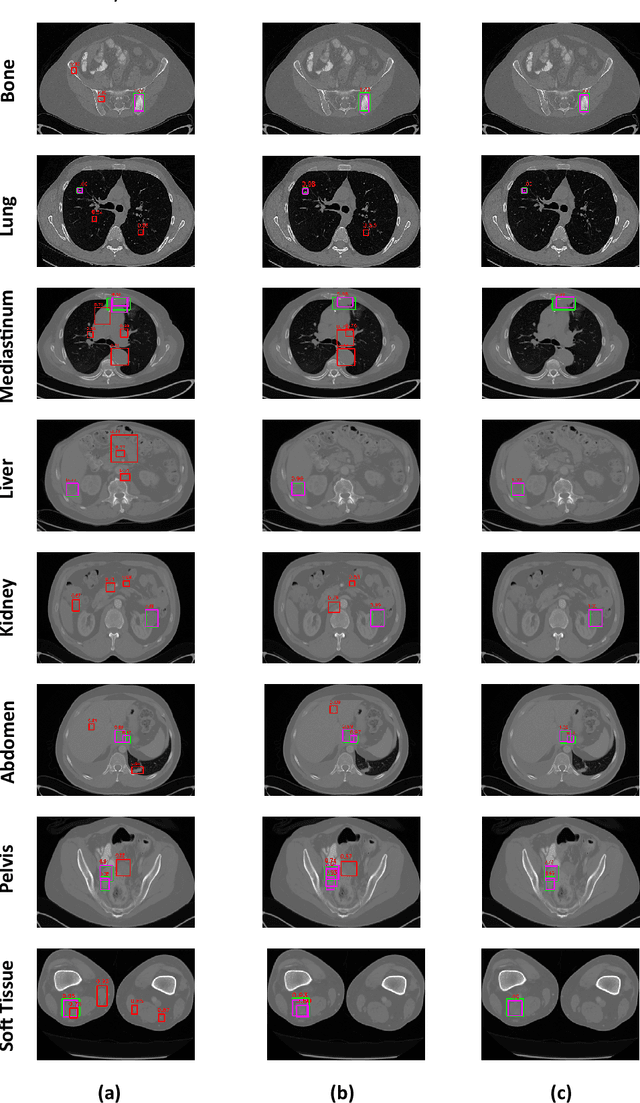
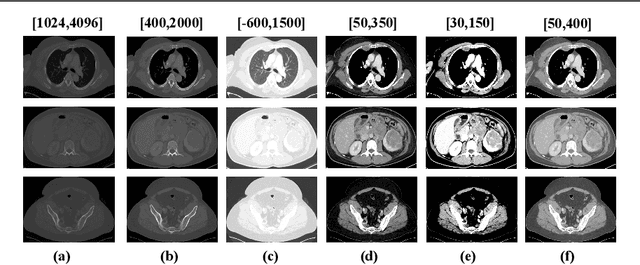
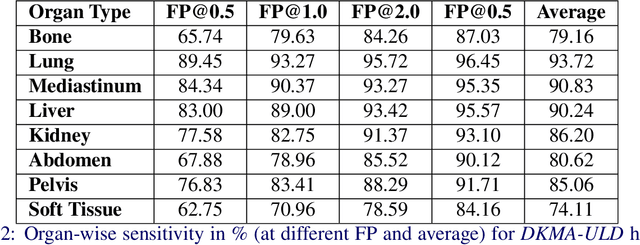
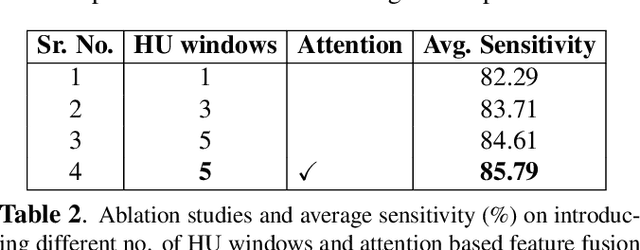
Incorporating data-specific domain knowledge in deep networks explicitly can provide important cues beneficial for lesion detection and can mitigate the need for diverse heterogeneous datasets for learning robust detectors. In this paper, we exploit the domain information present in computed tomography (CT) scans and propose a robust universal lesion detection (ULD) network that can detect lesions across all organs of the body by training on a single dataset, DeepLesion. We analyze CT-slices of varying intensities, generated using heuristically determined Hounsfield Unit(HU) windows that individually highlight different organs and are given as inputs to the deep network. The features obtained from the multiple intensity images are fused using a novel convolution augmented multi-head self-attention module and subsequently, passed to a Region Proposal Network (RPN) for lesion detection. In addition, we observed that traditional anchor boxes used in RPN for natural images are not suitable for lesion sizes often found in medical images. Therefore, we propose to use lesion-specific anchor sizes and ratios in the RPN for improving the detection performance. We use self-supervision to initialize weights of our network on the DeepLesion dataset to further imbibe domain knowledge. Our proposed Domain Knowledge augmented Multi-head Attention based Universal Lesion Detection Network DMKA-ULD produces refined and precise bounding boxes around lesions across different organs. We evaluate the efficacy of our network on the publicly available DeepLesion dataset which comprises of approximately 32K CT scans with annotated lesions across all organs of the body. Results demonstrate that we outperform existing state-of-the-art methods achieving an overall sensitivity of 87.16%.
* Main Paper: 13 Pages, 5 Figures, 2 Tables. Supplementary: 4 Pages, 1 Figure, 3 Tables. Paper accepted at The 32nd British Machine Vision Conference (BMVC'21)
TSR-DSAW: Table Structure Recognition via Deep Spatial Association of Words
Mar 14, 2022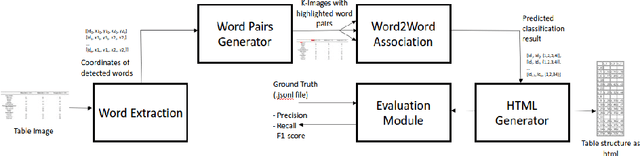
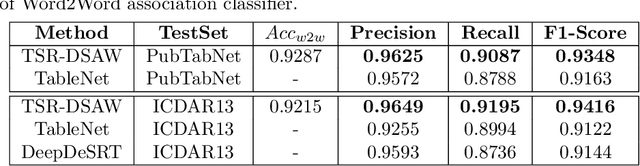
Existing methods for Table Structure Recognition (TSR) from camera-captured or scanned documents perform poorly on complex tables consisting of nested rows / columns, multi-line texts and missing cell data. This is because current data-driven methods work by simply training deep models on large volumes of data and fail to generalize when an unseen table structure is encountered. In this paper, we propose to train a deep network to capture the spatial associations between different word pairs present in the table image for unravelling the table structure. We present an end-to-end pipeline, named TSR-DSAW: TSR via Deep Spatial Association of Words, which outputs a digital representation of a table image in a structured format such as HTML. Given a table image as input, the proposed method begins with the detection of all the words present in the image using a text-detection network like CRAFT which is followed by the generation of word-pairs using dynamic programming. These word-pairs are highlighted in individual images and subsequently, fed into a DenseNet-121 classifier trained to capture spatial associations such as same-row, same-column, same-cell or none. Finally, we perform post-processing on the classifier output to generate the table structure in HTML format. We evaluate our TSR-DSAW pipeline on two public table-image datasets -- PubTabNet and ICDAR 2013, and demonstrate improvement over previous methods such as TableNet and DeepDeSRT.
* 6 pages, 1 figure, 1 table, ESANN 2021 proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning. Online event, 6-8 October 2021, i6doc.com publ., ISBN 978287587082-7
Continual Learning for Multivariate Time Series Tasks with Variable Input Dimensions
Mar 14, 2022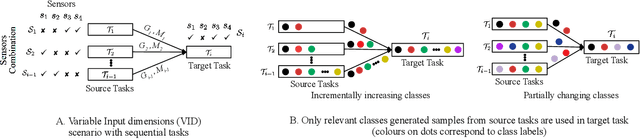
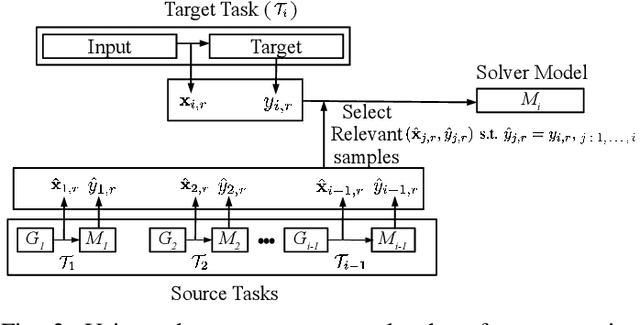
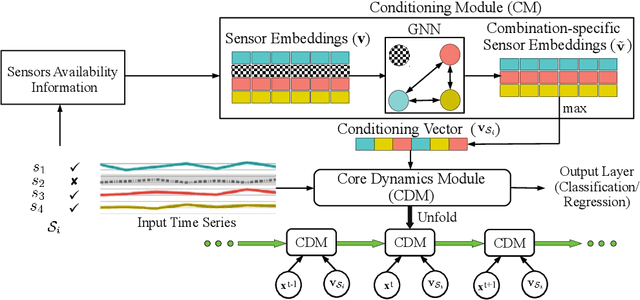
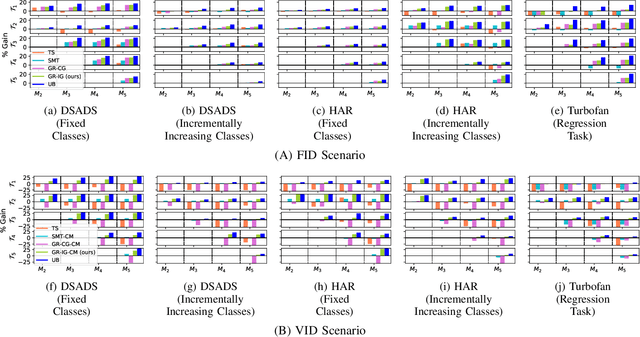
We consider a sequence of related multivariate time series learning tasks, such as predicting failures for different instances of a machine from time series of multi-sensor data, or activity recognition tasks over different individuals from multiple wearable sensors. We focus on two under-explored practical challenges arising in such settings: (i) Each task may have a different subset of sensors, i.e., providing different partial observations of the underlying 'system'. This restriction can be due to different manufacturers in the former case, and people wearing more or less measurement devices in the latter (ii) We are not allowed to store or re-access data from a task once it has been observed at the task level. This may be due to privacy considerations in the case of people, or legal restrictions placed by machine owners. Nevertheless, we would like to (a) improve performance on subsequent tasks using experience from completed tasks as well as (b) continue to perform better on past tasks, e.g., update the model and improve predictions on even the first machine after learning from subsequently observed ones. We note that existing continual learning methods do not take into account variability in input dimensions arising due to different subsets of sensors being available across tasks, and struggle to adapt to such variable input dimensions (VID) tasks. In this work, we address this shortcoming of existing methods. To this end, we learn task-specific generative models and classifiers, and use these to augment data for target tasks. Since the input dimensions across tasks vary, we propose a novel conditioning module based on graph neural networks to aid a standard recurrent neural network. We evaluate the efficacy of the proposed approach on three publicly available datasets corresponding to two activity recognition tasks (classification) and one prognostics task (regression).
Learning to Liquidate Forex: Optimal Stopping via Adaptive Top-K Regression
Feb 25, 2022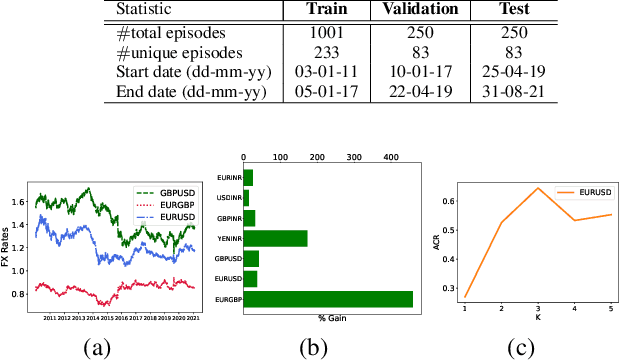
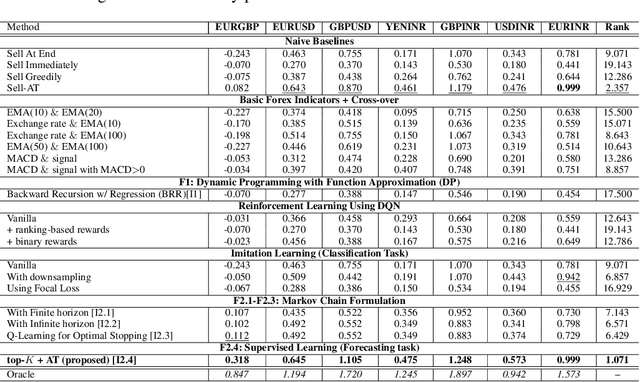
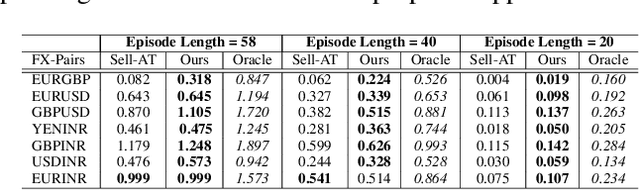
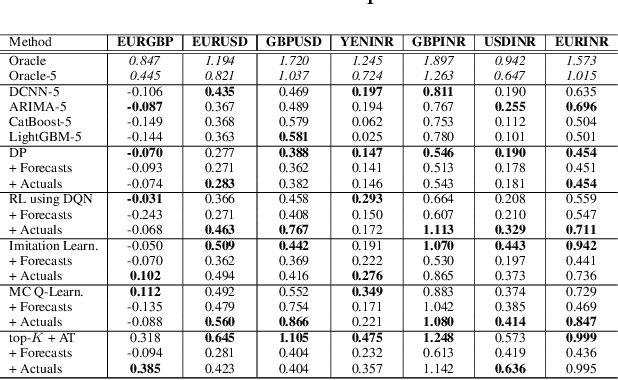
We consider learning a trading agent acting on behalf of the treasury of a firm earning revenue in a foreign currency (FC) and incurring expenses in the home currency (HC). The goal of the agent is to maximize the expected HC at the end of the trading episode by deciding to hold or sell the FC at each time step in the trading episode. We pose this as an optimization problem, and consider a broad spectrum of approaches with the learning component ranging from supervised to imitation to reinforcement learning. We observe that most of the approaches considered struggle to improve upon simple heuristic baselines. We identify two key aspects of the problem that render standard solutions ineffective - i) while good forecasts of future FX rates can be highly effective in guiding good decisions, forecasting FX rates is difficult, and erroneous estimates tend to degrade the performance of trading agents instead of improving it, ii) the inherent non-stationary nature of FX rates renders a fixed decision-threshold highly ineffective. To address these problems, we propose a novel supervised learning approach that learns to forecast the top-K future FX rates instead of forecasting all the future FX rates, and bases the hold-versus-sell decision on the forecasts (e.g. hold if future FX rate is higher than current FX rate, sell otherwise). Furthermore, to handle the non-stationarity in the FX rates data which poses challenges to the i.i.d. assumption in supervised learning methods, we propose to adaptively learn decision-thresholds based on recent historical episodes. Through extensive empirical evaluation, we show that our approach is the only approach which is able to consistently improve upon a simple heuristic baseline. Further experiments show the inefficacy of state-of-the-art statistical and deep-learning-based forecasting methods as they degrade the performance of the trading agent.
Electricity Consumption Forecasting for Out-of-distribution Time-of-Use Tariffs
Feb 11, 2022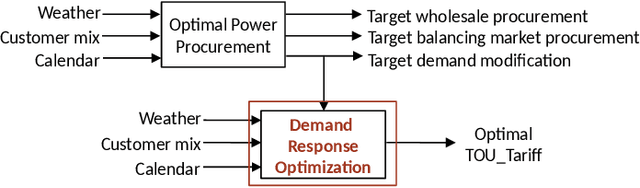
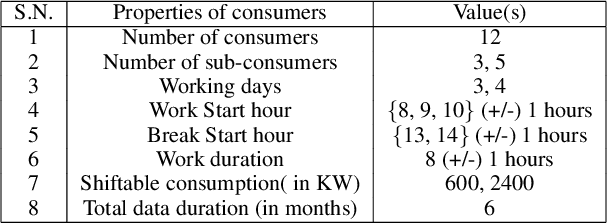
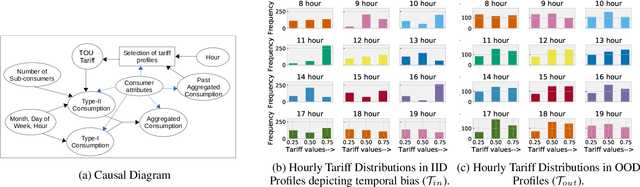

In electricity markets, retailers or brokers want to maximize profits by allocating tariff profiles to end consumers. One of the objectives of such demand response management is to incentivize the consumers to adjust their consumption so that the overall electricity procurement in the wholesale markets is minimized, e.g. it is desirable that consumers consume less during peak hours when cost of procurement for brokers from wholesale markets are high. We consider a greedy solution to maximize the overall profit for brokers by optimal tariff profile allocation. This in-turn requires forecasting electricity consumption for each user for all tariff profiles. This forecasting problem is challenging compared to standard forecasting problems due to following reasons: i. the number of possible combinations of hourly tariffs is high and retailers may not have considered all combinations in the past resulting in a biased set of tariff profiles tried in the past, ii. the profiles allocated in the past to each user is typically based on certain policy. These reasons violate the standard i.i.d. assumptions, as there is a need to evaluate new tariff profiles on existing customers and historical data is biased by the policies used in the past for tariff allocation. In this work, we consider several scenarios for forecasting and optimization under these conditions. We leverage the underlying structure of how consumers respond to variable tariff rates by comparing tariffs across hours and shifting loads, and propose suitable inductive biases in the design of deep neural network based architectures for forecasting under such scenarios. More specifically, we leverage attention mechanisms and permutation equivariant networks that allow desirable processing of tariff profiles to learn tariff representations that are insensitive to the biases in the data and still representative of the task.
DRTCI: Learning Disentangled Representations for Temporal Causal Inference
Jan 20, 2022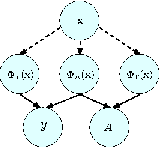
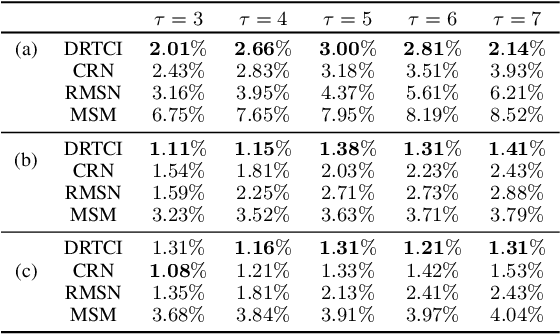
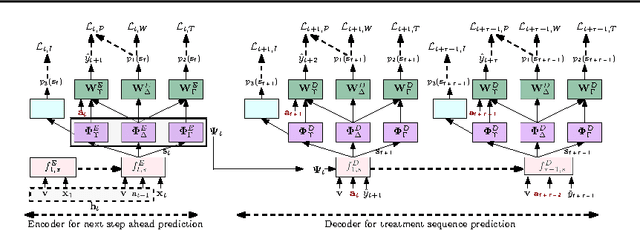
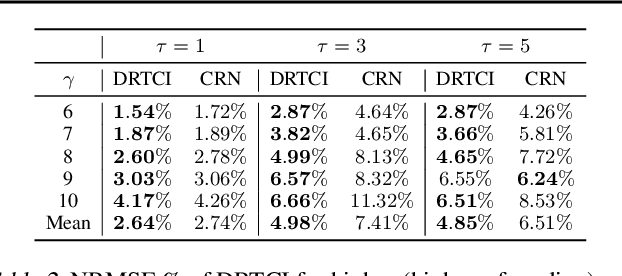
Medical professionals evaluating alternative treatment plans for a patient often encounter time varying confounders, or covariates that affect both the future treatment assignment and the patient outcome. The recently proposed Counterfactual Recurrent Network (CRN) accounts for time varying confounders by using adversarial training to balance recurrent historical representations of patient data. However, this work assumes that all time varying covariates are confounding and thus attempts to balance the full state representation. Given that the actual subset of covariates that may in fact be confounding is in general unknown, recent work on counterfactual evaluation in the static, non-temporal setting has suggested that disentangling the covariate representation into separate factors, where each either influence treatment selection, patient outcome or both can help isolate selection bias and restrict balancing efforts to factors that influence outcome, allowing the remaining factors which predict treatment without needlessly being balanced.
Solving Visual Analogies Using Neural Algorithmic Reasoning
Nov 19, 2021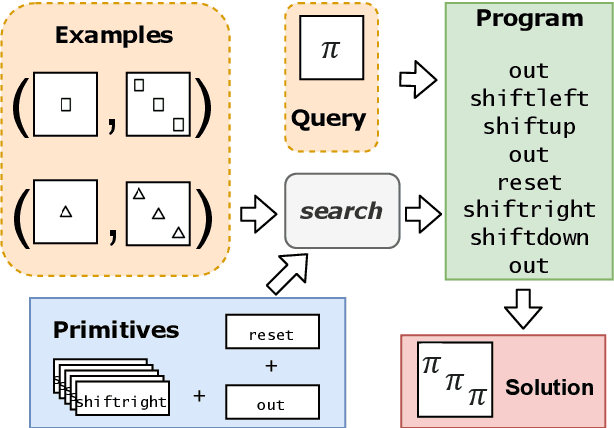

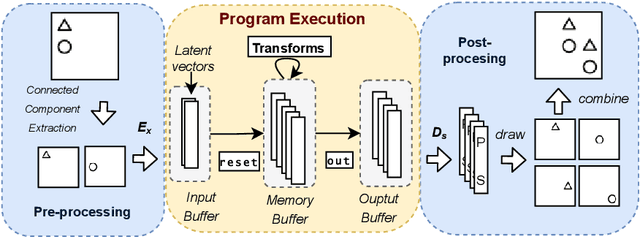
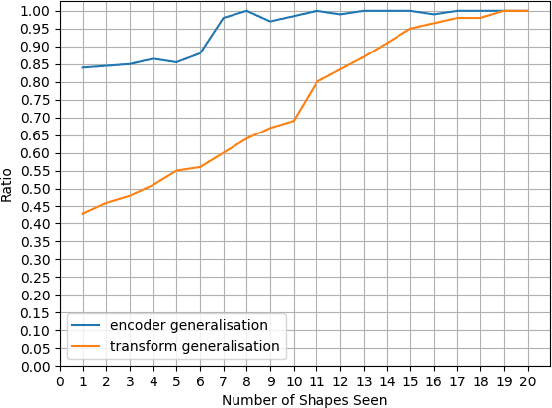
We consider a class of visual analogical reasoning problems that involve discovering the sequence of transformations by which pairs of input/output images are related, so as to analogously transform future inputs. This program synthesis task can be easily solved via symbolic search. Using a variation of the `neural analogical reasoning' approach of (Velickovic and Blundell 2021), we instead search for a sequence of elementary neural network transformations that manipulate distributed representations derived from a symbolic space, to which input images are directly encoded. We evaluate the extent to which our `neural reasoning' approach generalizes for images with unseen shapes and positions.