 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVarN: Variance-Normalized KV-Cache Quantization Mitigates Error Accumulation in Reasoning Tasks
Jun 02, 2026Test-time scaling is a powerful approach to obtain better reasoning in large language models, but it becomes memory-bottlenecked during long-horizon decoding, as the KV-cache grows. KV-cache quantization can help improve this, but current methods are evaluated under prefill-like settings and errors behave differently under autoregressive decoding. We show that in the latter regime, quantization errors accumulate across timesteps, driven primarily by incorrect token scales. We introduce KVarN, a calibration-free KV-cache quantizer that applies a Hadamard rotation followed by a dual-scaling variance normalization across both axes of the K and V matrices. We find that this combination fixes outlying token-scale errors and substantially reduces error accumulation over existing baselines. KVarN establishes a new state-of-theart for KV-cache quantization on generative benchmarks, including MATH500, AIME24 and HumanEval, at 2-bit precision. A vLLM implementation of the KVarN method is available at https://github.com/huawei-csl/KVarN
Overparametrization of HyperNetworks at Fixed FLOP-Count Enables Fast Neural Image Enhancement
May 18, 2021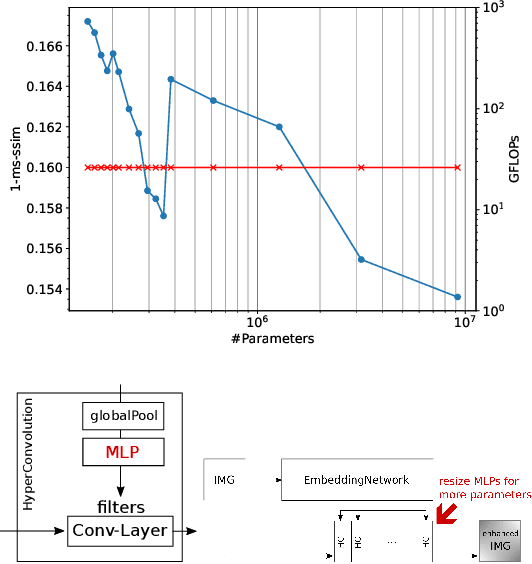
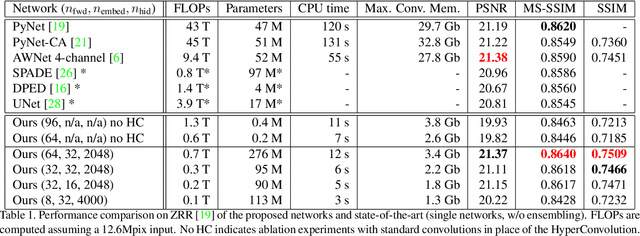
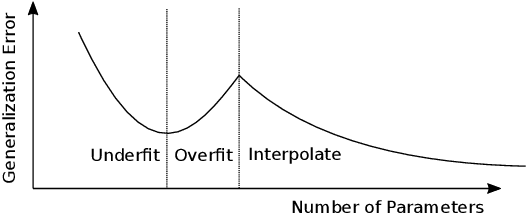

Deep convolutional neural networks can enhance images taken with small mobile camera sensors and excel at tasks like demoisaicing, denoising and super-resolution. However, for practical use on mobile devices these networks often require too many FLOPs and reducing the FLOPs of a convolution layer, also reduces its parameter count. This is problematic in view of the recent finding that heavily over-parameterized neural networks are often the ones that generalize best. In this paper we propose to use HyperNetworks to break the fixed ratio of FLOPs to parameters of standard convolutions. This allows us to exceed previous state-of-the-art architectures in SSIM and MS-SSIM on the Zurich RAW- to-DSLR (ZRR) data-set at > 10x reduced FLOP-count. On ZRR we further observe generalization curves consistent with 'double-descent' behavior at fixed FLOP-count, in the large image limit. Finally we demonstrate the same technique can be applied to an existing network (VDN) to reduce its computational cost while maintaining fidelity on the Smartphone Image Denoising Dataset (SIDD). Code for key functions is given in the appendix.
Rounding Methods for Neural Networks with Low Resolution Synaptic Weights
Apr 22, 2015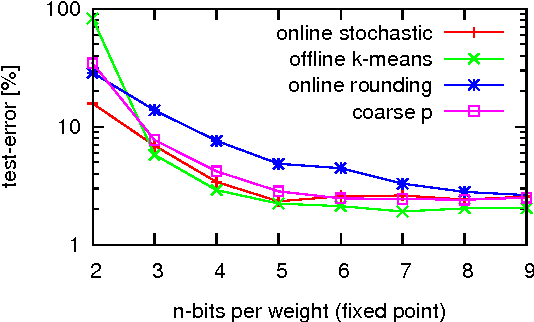
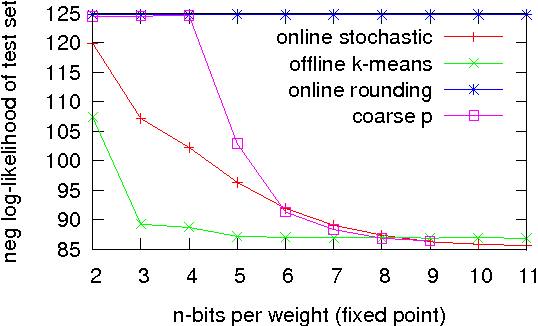
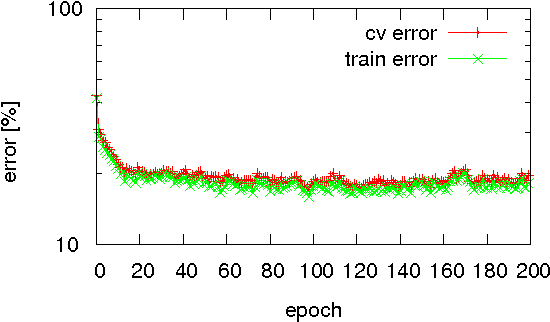
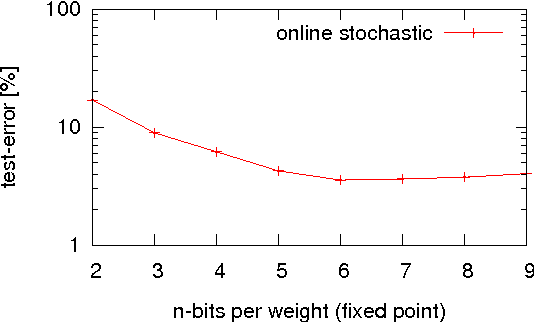
Neural network algorithms simulated on standard computing platforms typically make use of high resolution weights, with floating-point notation. However, for dedicated hardware implementations of such algorithms, fixed-point synaptic weights with low resolution are preferable. The basic approach of reducing the resolution of the weights in these algorithms by standard rounding methods incurs drastic losses in performance. To reduce the resolution further, in the extreme case even to binary weights, more advanced techniques are necessary. To this end, we propose two methods for mapping neural network algorithms with high resolution weights to corresponding algorithms that work with low resolution weights and demonstrate that their performance is substantially better than standard rounding. We further use these methods to investigate the performance of three common neural network algorithms under fixed memory size of the weight matrix with different weight resolutions. We show that dedicated hardware systems, whose technology dictates very low weight resolutions (be they electronic or biological) could in principle implement the algorithms we study.