 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrune-Quantize-Distill: An Ordered Pipeline for Efficient Neural Network Compression
Apr 05, 2026Modern deployment often requires trading accuracy for efficiency under tight CPU and memory constraints, yet common compression proxies such as parameter count or FLOPs do not reliably predict wall-clock inference time. In particular, unstructured sparsity can reduce model storage while failing to accelerate (and sometimes slightly slowing down) standard CPU execution due to irregular memory access and sparse kernel overhead. Motivated by this gap between compression and acceleration, we study a practical, ordered pipeline that targets measured latency by combining three widely used techniques: unstructured pruning, INT8 quantization-aware training (QAT), and knowledge distillation (KD). Empirically, INT8 QAT provides the dominant runtime benefit, while pruning mainly acts as a capacity-reduction pre-conditioner that improves the robustness of subsequent low-precision optimization; KD, applied last, recovers accuracy within the already constrained sparse INT8 regime without changing the deployment form. We evaluate on CIFAR-10/100 using three backbones (ResNet-18, WRN-28-10, and VGG-16-BN). Across all settings, the ordered pipeline achieves a stronger accuracy-size-latency frontier than any single technique alone, reaching 0.99-1.42 ms CPU latency with competitive accuracy and compact checkpoints. Controlled ordering ablations with a fixed 20/40/40 epoch allocation further confirm that stage order is consequential, with the proposed ordering generally performing best among the tested permutations. Overall, our results provide a simple guideline for edge deployment: evaluate compression choices in the joint accuracy-size-latency space using measured runtime, rather than proxy metrics alone.
Fairness Assessment for Artificial Intelligence in Financial Industry
Dec 16, 2019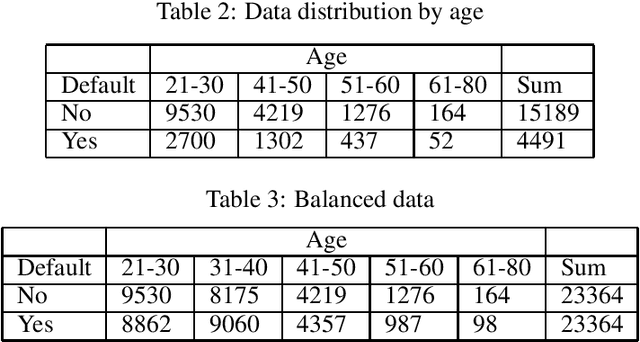
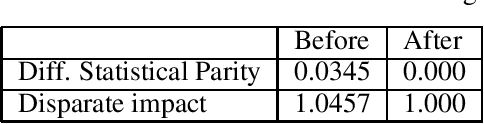
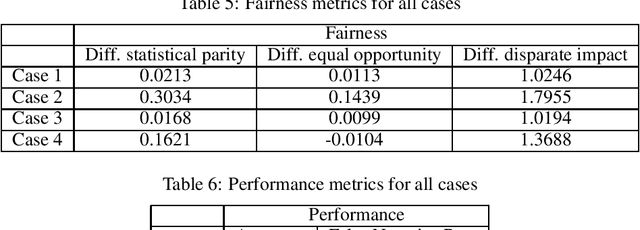
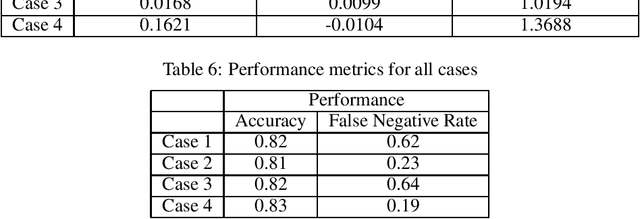
Artificial Intelligence (AI) is an important driving force for the development and transformation of the financial industry. However, with the fast-evolving AI technology and application, unintentional bias, insufficient model validation, immature contingency plan and other underestimated threats may expose the company to operational and reputational risks. In this paper, we focus on fairness evaluation, one of the key components of AI Governance, through a quantitative lens. Statistical methods are reviewed for imbalanced data treatment and bias mitigation. These methods and fairness evaluation metrics are then applied to a credit card default payment example.