 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Evolving Multi-Agent Network for Industrial IoT Predictive Maintenance
Feb 17, 2026Industrial IoT predictive maintenance requires systems capable of real-time anomaly detection without sacrificing interpretability or demanding excessive computational resources. Traditional approaches rely on static, offline-trained models that cannot adapt to evolving operational conditions, while LLM-based monolithic systems demand prohibitive memory and latency, rendering them impractical for on-site edge deployment. We introduce SEMAS, a self-evolving hierarchical multi-agent system that distributes specialized agents across Edge, Fog, and Cloud computational tiers. Edge agents perform lightweight feature extraction and pre-filtering; Fog agents execute diversified ensemble detection with dynamic consensus voting; and Cloud agents continuously optimize system policies via Proximal Policy Optimization (PPO) while maintaining asynchronous, non-blocking inference. The framework incorporates LLM-based response generation for explainability and federated knowledge aggregation for adaptive policy distribution. This architecture enables resource-aware specialization without sacrificing real-time performance or model interpretability. Empirical evaluation on two industrial benchmarks (Boiler Emulator and Wind Turbine) demonstrates that SEMAS achieves superior anomaly detection performance with exceptional stability under adaptation, sustains prediction accuracy across evolving operational contexts, and delivers substantial latency improvements enabling genuine real-time deployment. Ablation studies confirm that PPO-driven policy evolution, consensus voting, and federated aggregation each contribute materially to system effectiveness. These findings indicate that resource-aware, self-evolving 1multi-agent coordination is essential for production-ready industrial IoT predictive maintenance under strict latency and explainability constraints.
Vision Transformer Visualization: What Neurons Tell and How Neurons Behave?
Oct 18, 2022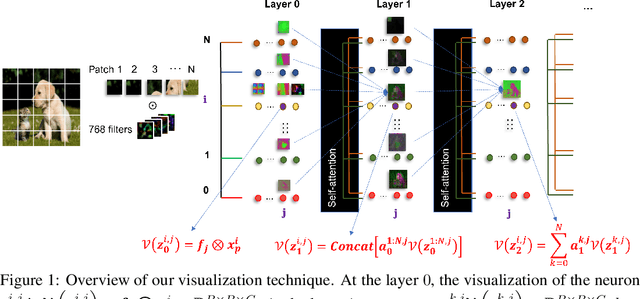
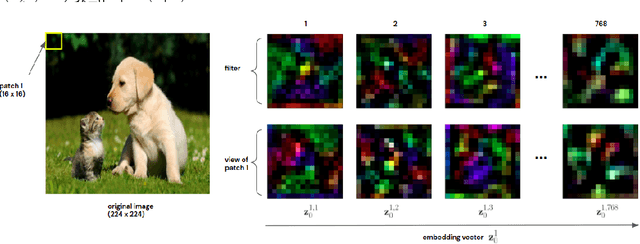


Recently vision transformers (ViT) have been applied successfully for various tasks in computer vision. However, important questions such as why they work or how they behave still remain largely unknown. In this paper, we propose an effective visualization technique, to assist us in exposing the information carried in neurons and feature embeddings across the ViT's layers. Our approach departs from the computational process of ViTs with a focus on visualizing the local and global information in input images and the latent feature embeddings at multiple levels. Visualizations at the input and embeddings at level 0 reveal interesting findings such as providing support as to why ViTs are rather generally robust to image occlusions and patch shuffling; or unlike CNNs, level 0 embeddings already carry rich semantic details. Next, we develop a rigorous framework to perform effective visualizations across layers, exposing the effects of ViTs filters and grouping/clustering behaviors to object patches. Finally, we provide comprehensive experiments on real datasets to qualitatively and quantitatively demonstrate the merit of our proposed methods as well as our findings. https://github.com/byM1902/ViT_visualization