 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the factors affecting usefulness of Self-Supervised Pre-trained Representations for Speech Recognition
Apr 04, 2022
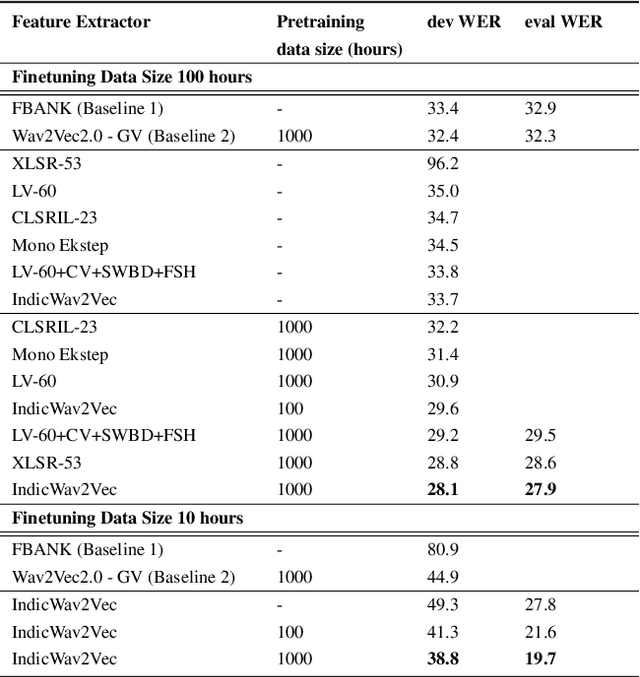
Self-supervised learning (SSL) to learn high-level speech representations has been a popular approach to building Automatic Speech Recognition (ASR) systems in low-resource settings. However, the common assumption made in literature is that a considerable amount of unlabeled data is available for the same domain or language that can be leveraged for SSL pre-training, which we acknowledge is not feasible in a real-world setting. In this paper, as part of the Interspeech Gram Vaani ASR challenge, we try to study the effect of domain, language, dataset size, and other aspects of our upstream pre-training SSL data on the final performance low-resource downstream ASR task. We also build on the continued pre-training paradigm to study the effect of prior knowledge possessed by models trained using SSL. Extensive experiments and studies reveal that the performance of ASR systems is susceptible to the data used for SSL pre-training. Their performance improves with an increase in similarity and volume of pre-training data. We believe our work will be helpful to the speech community in building better ASR systems in low-resource settings and steer research towards improving generalization in SSL-based pre-training for speech systems.
PADA: Pruning Assisted Domain Adaptation for Self-Supervised Speech Representations
Mar 31, 2022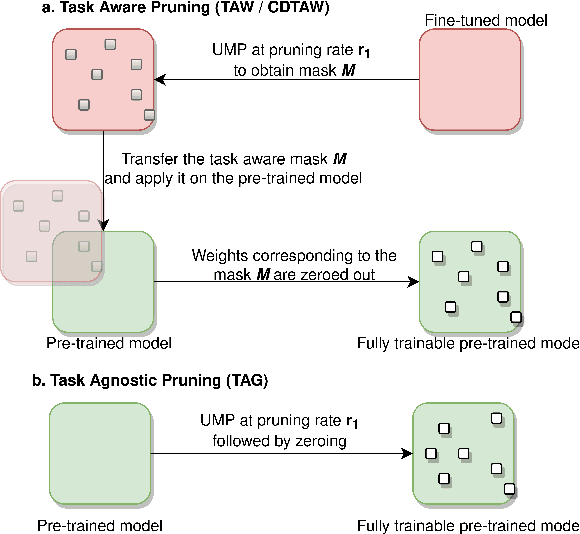
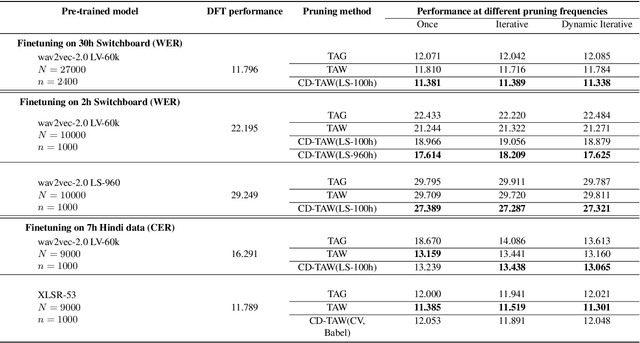
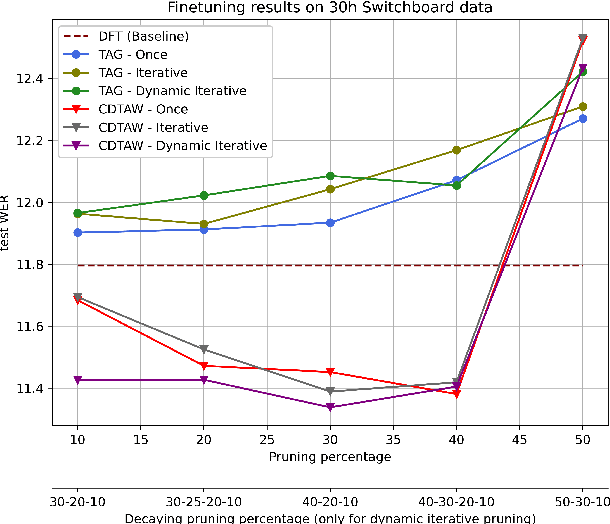
While self-supervised speech representation learning (SSL) models serve a variety of downstream tasks, these models have been observed to overfit to the domain from which the unlabelled data originates. To alleviate this issue, we propose PADA (Pruning Assisted Domain Adaptation) and zero out redundant weights from models pre-trained on large amounts of out-of-domain (OOD) data. Intuitively, this helps to make space for the target-domain ASR finetuning. The redundant weights can be identified through various pruning strategies which have been discussed in detail as a part of this work. Specifically, we investigate the effect of the recently discovered Task-Agnostic and Task-Aware pruning on PADA and propose a new pruning paradigm based on the latter, which we call Cross-Domain Task-Aware Pruning (CD-TAW). CD-TAW obtains the initial pruning mask from a well fine-tuned OOD model, which makes it starkly different from the rest of the pruning strategies discussed in the paper. Our proposed CD-TAW methodology achieves up to 20.6% relative WER improvement over our baseline when fine-tuned on a 2-hour subset of Switchboard data without language model (LM) decoding. Furthermore, we conduct a detailed analysis to highlight the key design choices of our proposed method.