 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus-based Agentic Large Language Model Framework for Harmonized Tariff Schedule Code Classification
Jun 15, 2026Accurate Harmonized Tariff Schedule (HTS) code classification is essential for customs clearance, duty assessment, trade statistics, and regulatory compliance in maritime logistics. However, exact HTS classification remains challenging because product descriptions are often short, incomplete, or ambiguous, while correct classification depends on hierarchical tariff structures, legal notes, and jurisdiction-specific rules. This paper proposes an agentic large language model (LLM) framework for Canadian 10-digit HTS code classification in smart-port and maritime logistics environments. The framework integrates multi-agent information retrieval, semantic retrieval over official tariff documents, evidence-grounded reasoning, consensus-based validation, element-wise voting across hierarchical code components, confidence estimation, and human-in-the-loop escalation. We evaluate the framework on a private dataset of 3,300 domain-expert-labeled product records collected from logistics and delivery contexts. Experimental results show that exact 10-digit classification remains difficult even for advanced LLMs, with performance decreasing from coarse chapter-level prediction to fine-grained tariff and statistical suffix assignment. These findings demonstrate the need for evidence-grounded, uncertainty-aware, and human-centered classification workflows rather than fully autonomous single-step prediction. The proposed framework supports more interpretable, accountable, and compliance-oriented HTS classification for maritime logistics and smart-port operations. Our code is available at https://github.com/Analytics-Everywhere-Lab/hts.
Combinations of Jaccard with Numerical Measures for Collaborative Filtering Enhancement: Current Work and Future Proposal
Nov 24, 2021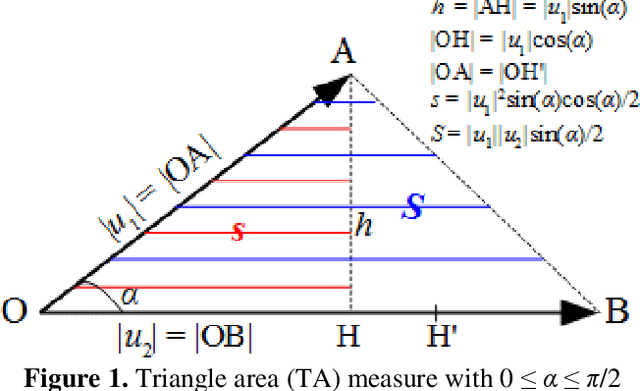
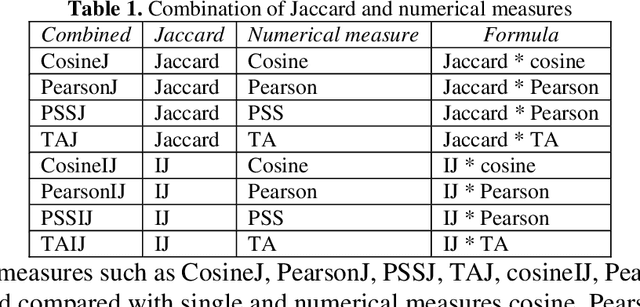
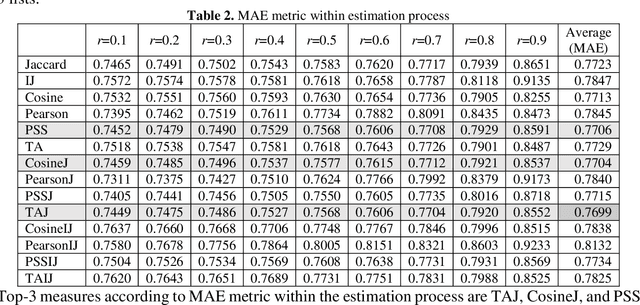
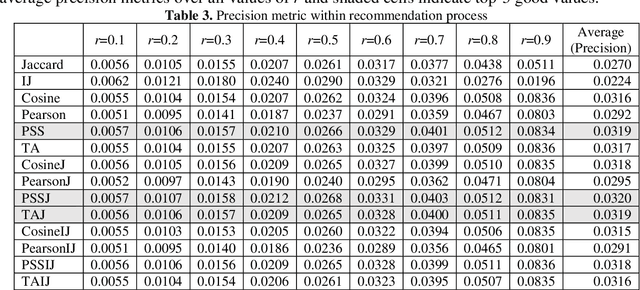
Collaborative filtering (CF) is an important approach for recommendation system which is widely used in a great number of aspects of our life, heavily in the online-based commercial systems. One popular algorithms in CF is the K-nearest neighbors (KNN) algorithm, in which the similarity measures are used to determine nearest neighbors of a user, and thus to quantify the dependency degree between the relative user/item pair. Consequently, CF approach is not just sensitive to the similarity measure, yet it is completely contingent on selection of that measure. While Jaccard - as one of those commonly used similarity measures for CF tasks - concerns the existence of ratings, other numerical measures such as cosine and Pearson concern the magnitude of ratings. Particularly speaking, Jaccard is not a dominant measure, but it is long proven to be an important factor to improve any measure. Therefore, in our continuous efforts to find the most effective similarity measures for CF, this research focuses on proposing new similarity measure via combining Jaccard with several numerical measures. The combined measures would take the advantages of both existence and magnitude. Experimental results on, Movie-lens dataset, showed that the combined measures are preeminent outperforming all single measures over the considered evaluation metrics.