 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Effective are Generative Large Language Models in Performing Requirements Classification?
Apr 23, 2025In recent years, transformer-based large language models (LLMs) have revolutionised natural language processing (NLP), with generative models opening new possibilities for tasks that require context-aware text generation. Requirements engineering (RE) has also seen a surge in the experimentation of LLMs for different tasks, including trace-link detection, regulatory compliance, and others. Requirements classification is a common task in RE. While non-generative LLMs like BERT have been successfully applied to this task, there has been limited exploration of generative LLMs. This gap raises an important question: how well can generative LLMs, which produce context-aware outputs, perform in requirements classification? In this study, we explore the effectiveness of three generative LLMs-Bloom, Gemma, and Llama-in performing both binary and multi-class requirements classification. We design an extensive experimental study involving over 400 experiments across three widely used datasets (PROMISE NFR, Functional-Quality, and SecReq). Our study concludes that while factors like prompt design and LLM architecture are universally important, others-such as dataset variations-have a more situational impact, depending on the complexity of the classification task. This insight can guide future model development and deployment strategies, focusing on optimising prompt structures and aligning model architectures with task-specific needs for improved performance.
A Machine Learning Approach for Hierarchical Classification of Software Requirements
Feb 24, 2023Context: Classification of software requirements into different categories is a critically important task in requirements engineering (RE). Developing machine learning (ML) approaches for requirements classification has attracted great interest in the RE community since the 2000s. Objective: This paper aims to address two related problems that have been challenging real-world applications of ML approaches: the problems of class imbalance and high dimensionality with low sample size data (HDLSS). These problems can greatly degrade the classification performance of ML methods. Method: The paper proposes HC4RC, a novel ML approach for multiclass classification of requirements. HC4RC solves the aforementioned problems through semantic-role-based feature selection, dataset decomposition and hierarchical classification. We experimentally compare the effectiveness of HC4RC with three closely related approaches - two of which are based on a traditional statistical classification model whereas one uses an advanced deep learning model. Results: Our experiment shows: 1) The class imbalance and HDLSS problems present a challenge to both traditional and advanced ML approaches. 2) The HC4RC approach is simple to use and can effectively address the class imbalance and HDLSS problems compared to similar approaches. Conclusion: This paper makes an important practical contribution to addressing the class imbalance and HDLSS problems in multiclass classification of software requirements.
Zero-Shot Learning for Requirements Classification: An Exploratory Study
Feb 09, 2023



Context and motivation: Requirements Engineering (RE) researchers have been experimenting Machine Learning (ML) and Deep Learning (DL) approaches for a range of RE tasks, such as requirements classification, requirements tracing, ambiguity detection, and modelling. Question-problem: Most of today's ML-DL approaches are based on supervised learning techniques, meaning that they need to be trained using annotated datasets to learn how to assign a class label to sample items from an application domain. This constraint poses an enormous challenge to RE researchers, as the lack of annotated datasets makes it difficult for them to fully exploit the benefit of advanced ML-DL technologies. Principal ideas-results: To address this challenge, this paper proposes an approach that employs the embedding-based unsupervised Zero-Shot Learning (ZSL) technique to perform requirements classification. We focus on the classification task because many RE tasks can be framed as classification problems. In this study, we demonstrate our approach for three tasks. (1) FR-NFR: classification functional requirements vs non-functional requirements; (2) NFR: identification of NFR classes; (3) Security: classification of security vs non-security requirements. The study shows that the ZSL approach achieves an F1 score of 0.66 for the FR-NFR task. For the NFR task, the approach yields F1 ~ 0.72-0.80, considering the most frequent classes. For the Security task, F1 ~ 0.66. All of the aforementioned F1 scores are achieved with zero-training efforts. Contribution: This study demonstrates the potential of ZSL for requirements classification. An important implication is that it is possible to have very little or no training data to perform multiple tasks. The proposed approach thus contributes to the solution of the longstanding problem of data shortage in RE.
Classification of Natural Language Processing Techniques for Requirements Engineering
Apr 08, 2022
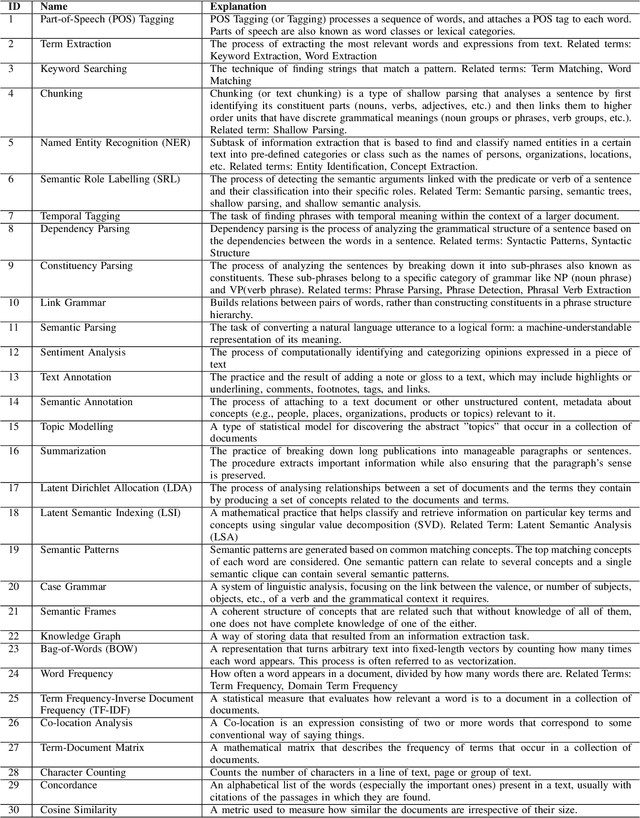
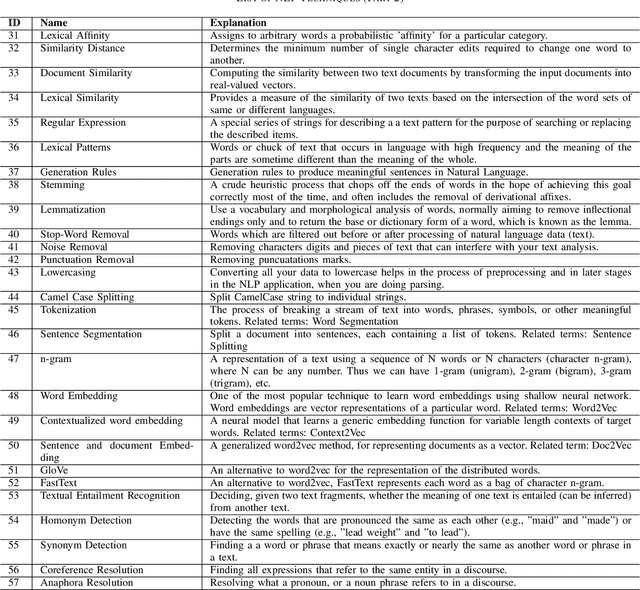
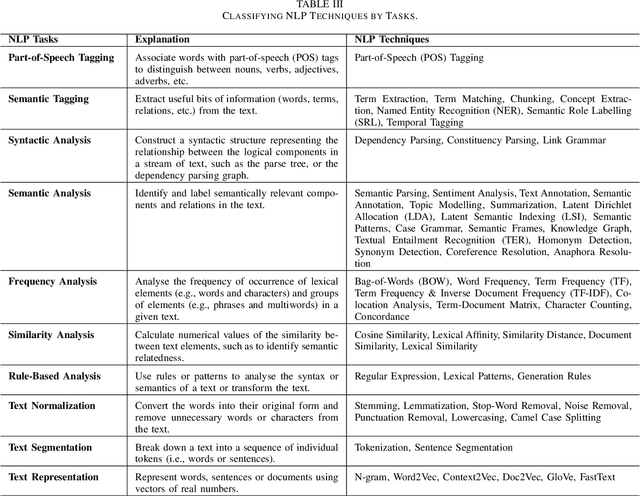
Research in applying natural language processing (NLP) techniques to requirements engineering (RE) tasks spans more than 40 years, from initial efforts carried out in the 1980s to more recent attempts with machine learning (ML) and deep learning (DL) techniques. However, in spite of the progress, our recent survey shows that there is still a lack of systematic understanding and organization of commonly used NLP techniques in RE. We believe one hurdle facing the industry is lack of shared knowledge of NLP techniques and their usage in RE tasks. In this paper, we present our effort to synthesize and organize 57 most frequently used NLP techniques in RE. We classify these NLP techniques in two ways: first, by their NLP tasks in typical pipelines and second, by their linguist analysis levels. We believe these two ways of classification are complementary, contributing to a better understanding of the NLP techniques in RE and such understanding is crucial to the development of better NLP tools for RE.