 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApollo: A Posteriori Label-Only Membership Inference Attack Towards Machine Unlearning
Jun 11, 2025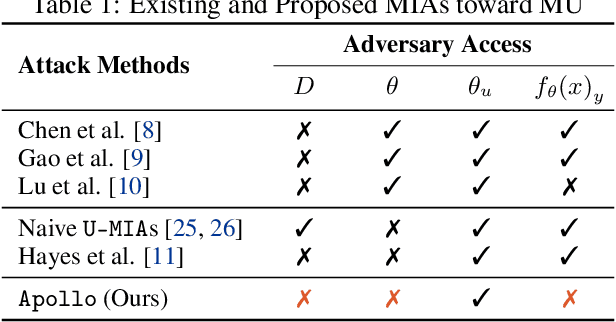
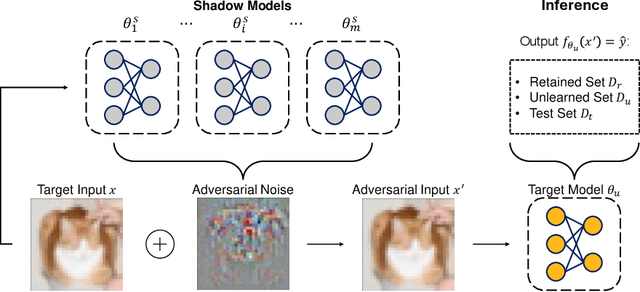
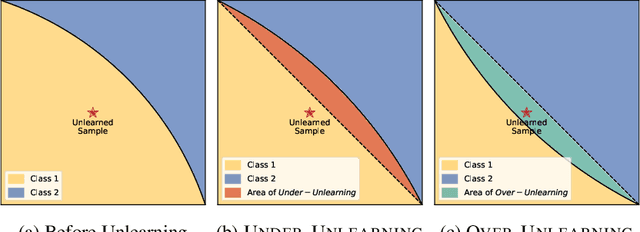

Machine Unlearning (MU) aims to update Machine Learning (ML) models following requests to remove training samples and their influences on a trained model efficiently without retraining the original ML model from scratch. While MU itself has been employed to provide privacy protection and regulatory compliance, it can also increase the attack surface of the model. Existing privacy inference attacks towards MU that aim to infer properties of the unlearned set rely on the weaker threat model that assumes the attacker has access to both the unlearned model and the original model, limiting their feasibility toward real-life scenarios. We propose a novel privacy attack, A Posteriori Label-Only Membership Inference Attack towards MU, Apollo, that infers whether a data sample has been unlearned, following a strict threat model where an adversary has access to the label-output of the unlearned model only. We demonstrate that our proposed attack, while requiring less access to the target model compared to previous attacks, can achieve relatively high precision on the membership status of the unlearned samples.