 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXAI for Transformers: Better Explanations through Conservative Propagation
Feb 15, 2022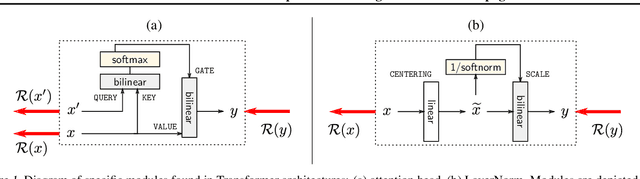
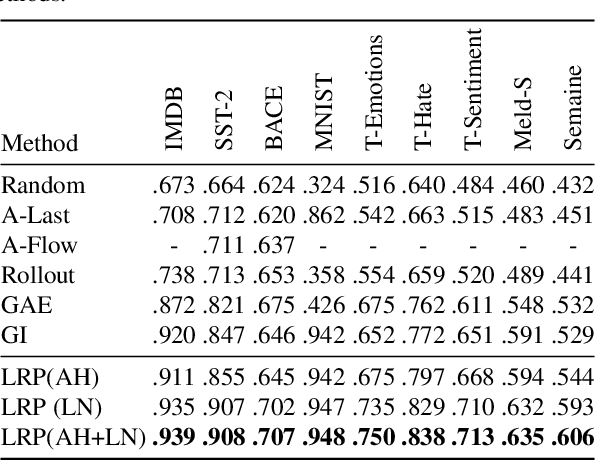
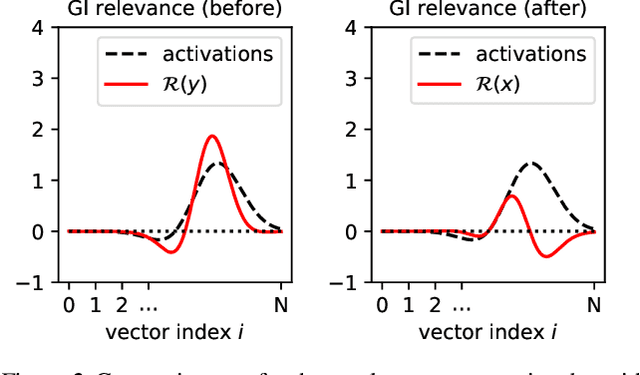
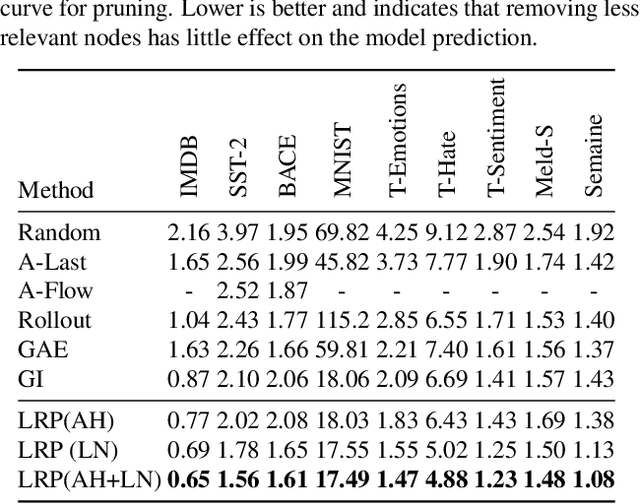
Transformers have become an important workhorse of machine learning, with numerous applications. This necessitates the development of reliable methods for increasing their transparency. Multiple interpretability methods, often based on gradient information, have been proposed. We show that the gradient in a Transformer reflects the function only locally, and thus fails to reliably identify the contribution of input features to the prediction. We identify Attention Heads and LayerNorm as main reasons for such unreliable explanations and propose a more stable way for propagation through these layers. Our proposal, which can be seen as a proper extension of the well-established LRP method to Transformers, is shown both theoretically and empirically to overcome the deficiency of a simple gradient-based approach, and achieves state-of-the-art explanation performance on a broad range of Transformer models and datasets.
Unsupervised Disentanglement with Tensor Product Representations on the Torus
Feb 13, 2022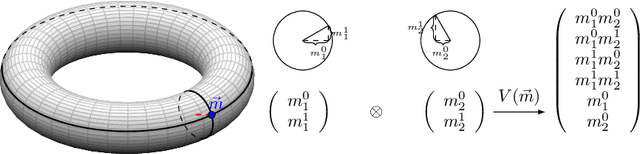
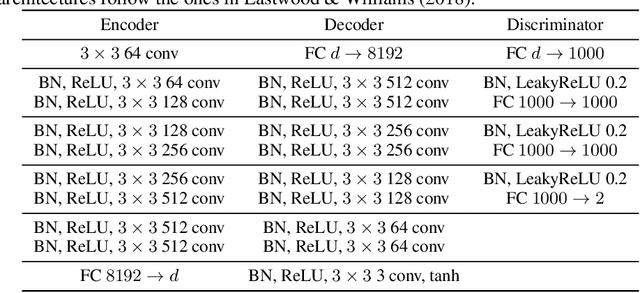
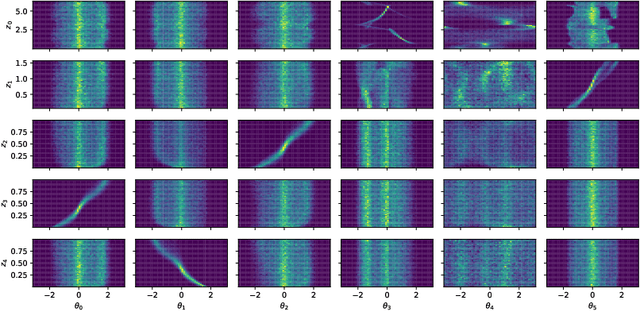
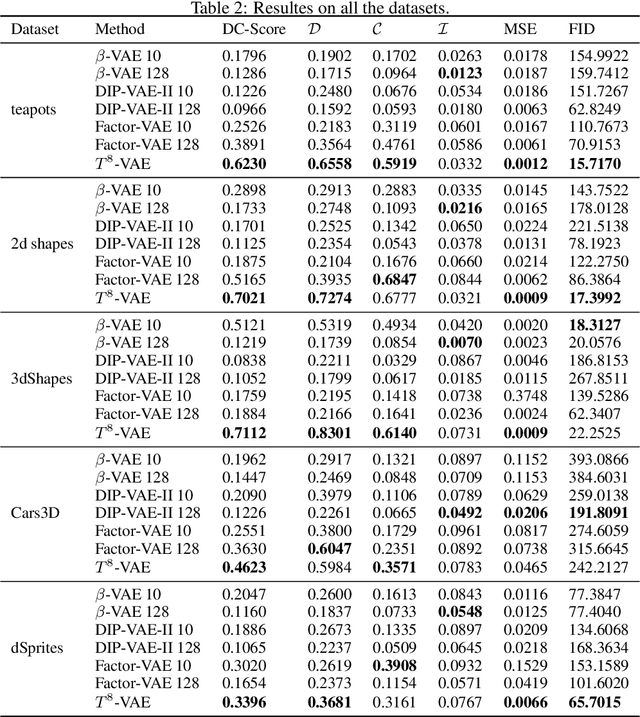
The current methods for learning representations with auto-encoders almost exclusively employ vectors as the latent representations. In this work, we propose to employ a tensor product structure for this purpose. This way, the obtained representations are naturally disentangled. In contrast to the conventional variations methods, which are targeted toward normally distributed features, the latent space in our representation is distributed uniformly over a set of unit circles. We argue that the torus structure of the latent space captures the generative factors effectively. We employ recent tools for measuring unsupervised disentanglement, and in an extensive set of experiments demonstrate the advantage of our method in terms of disentanglement, completeness, and informativeness. The code for our proposed method is available at https://github.com/rotmanmi/Unsupervised-Disentanglement-Torus.
Locally Shifted Attention With Early Global Integration
Dec 22, 2021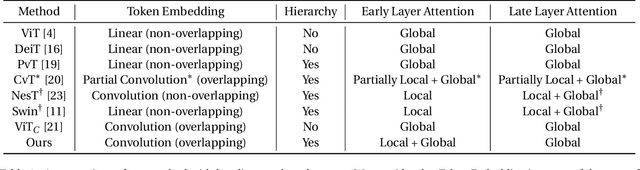

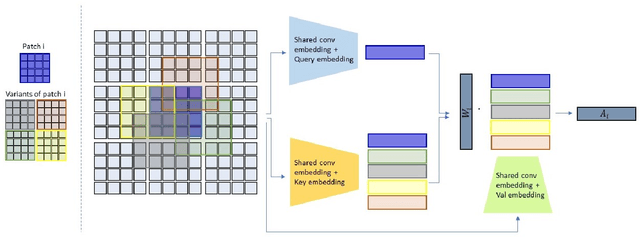
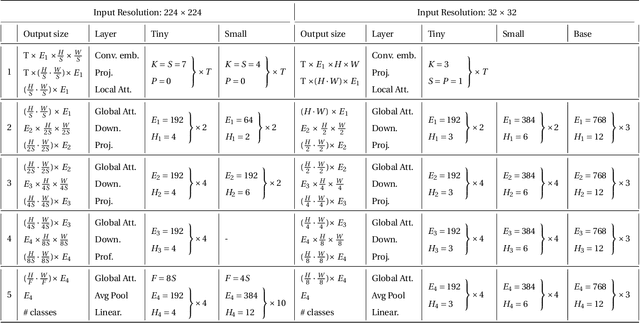
Recent work has shown the potential of transformers for computer vision applications. An image is first partitioned into patches, which are then used as input tokens for the attention mechanism. Due to the expensive quadratic cost of the attention mechanism, either a large patch size is used, resulting in coarse-grained global interactions, or alternatively, attention is applied only on a local region of the image, at the expense of long-range interactions. In this work, we propose an approach that allows for both coarse global interactions and fine-grained local interactions already at early layers of a vision transformer. At the core of our method is the application of local and global attention layers. In the local attention layer, we apply attention to each patch and its local shifts, resulting in virtually located local patches, which are not bound to a single, specific location. These virtually located patches are then used in a global attention layer. The separation of the attention layer into local and global counterparts allows for a low computational cost in the number of patches, while still supporting data-dependent localization already at the first layer, as opposed to the static positioning in other visual transformers. Our method is shown to be superior to both convolutional and transformer-based methods for image classification on CIFAR10, CIFAR100, and ImageNet. Code is available at: https://github.com/shellysheynin/Locally-SAG-Transformer.
fMRI Neurofeedback Learning Patterns are Predictive of Personal and Clinical Traits
Dec 21, 2021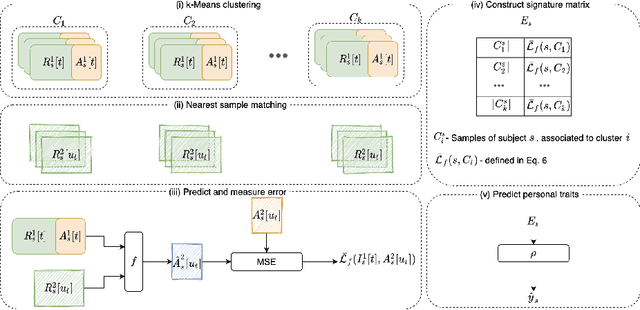
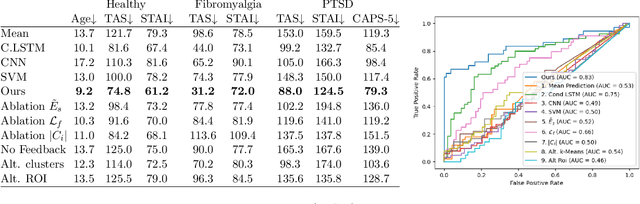
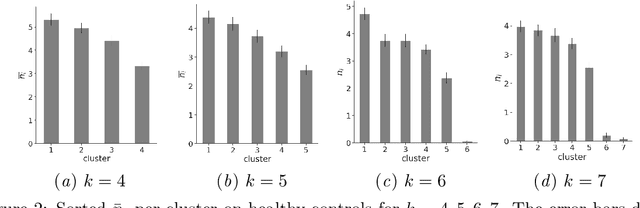

We obtain a personal signature of a person's learning progress in a self-neuromodulation task, guided by functional MRI (fMRI). The signature is based on predicting the activity of the Amygdala in a second neurofeedback session, given a similar fMRI-derived brain state in the first session. The prediction is made by a deep neural network, which is trained on the entire training cohort of patients. This signal, which is indicative of a person's progress in performing the task of Amygdala modulation, is aggregated across multiple prototypical brain states and then classified by a linear classifier to various personal and clinical indications. The predictive power of the obtained signature is stronger than previous approaches for obtaining a personal signature from fMRI neurofeedback and provides an indication that a person's learning pattern may be used as a diagnostic tool. Our code has been made available, and data would be shared, subject to ethical approvals.
Pre-training and Fine-tuning Transformers for fMRI Prediction Tasks
Dec 10, 2021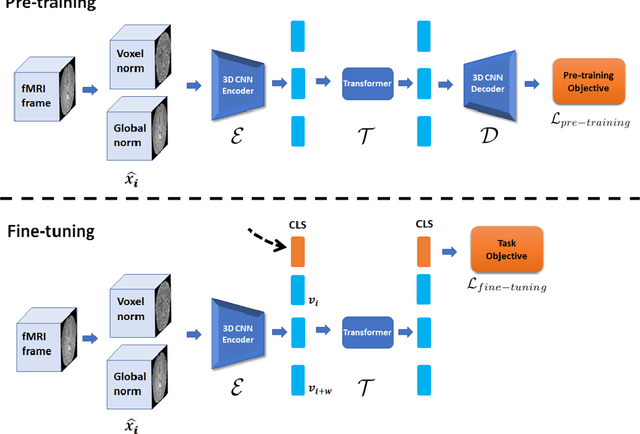
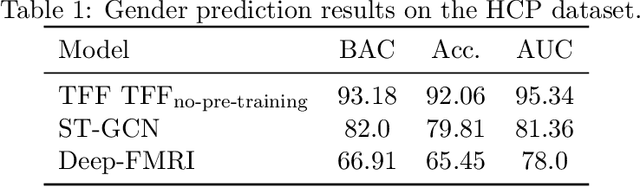
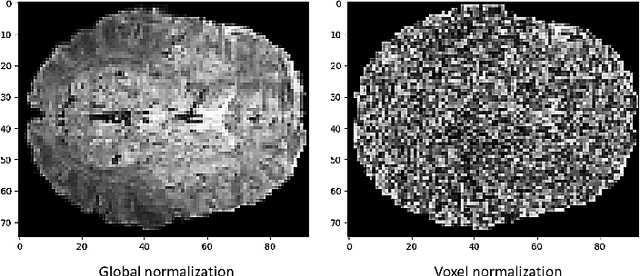
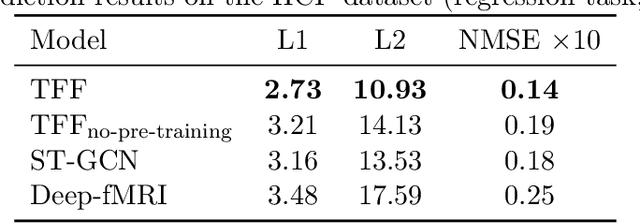
We present the TFF Transformer framework for the analysis of functional Magnetic Resonance Imaging (fMRI) data. TFF employs a transformer-based architecture and a two-phase training approach. First, self-supervised training is applied to a collection of fMRI scans, where the model is trained for the reconstruction of 3D volume data. Second, the pre-trained model is fine-tuned on specific tasks, utilizing ground truth labels. Our results show state-of-the-art performance on a variety of fMRI tasks, including age and gender prediction, as well as schizophrenia recognition.
Learning Personal Representations from fMRIby Predicting Neurofeedback Performance
Dec 06, 2021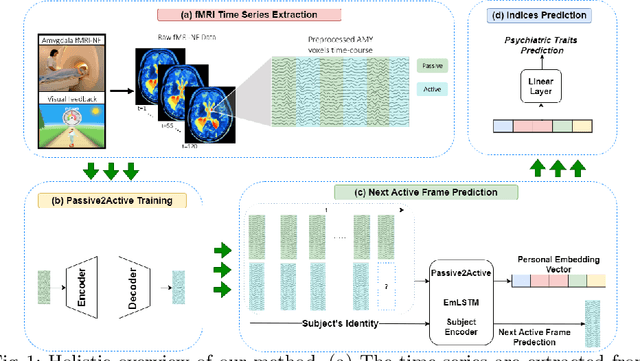
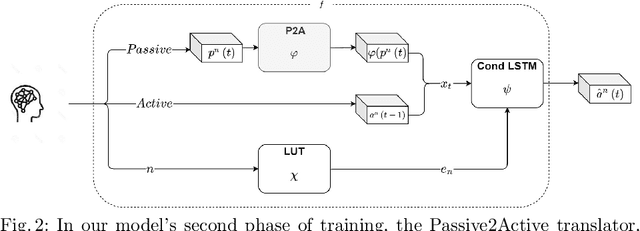
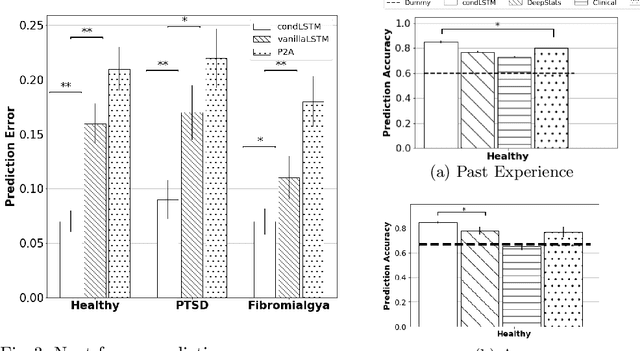
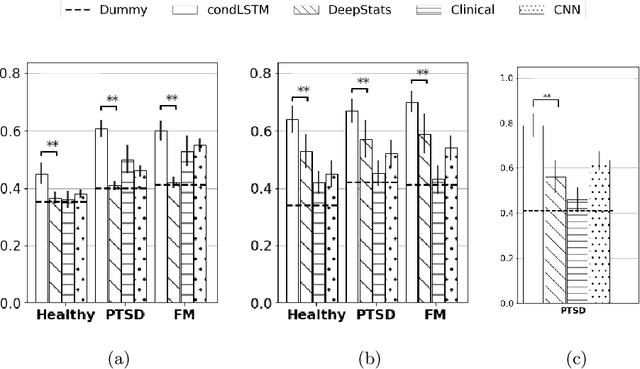
We present a deep neural network method for learning a personal representation for individuals that are performing a self neuromodulation task, guided by functional MRI (fMRI). This neurofeedback task (watch vs. regulate) provides the subjects with a continuous feedback contingent on down regulation of their Amygdala signal and the learning algorithm focuses on this region's time-course of activity. The representation is learned by a self-supervised recurrent neural network, that predicts the Amygdala activity in the next fMRI frame given recent fMRI frames and is conditioned on the learned individual representation. It is shown that the individuals' representation improves the next-frame prediction considerably. Moreover, this personal representation, learned solely from fMRI images, yields good performance in linear prediction of psychiatric traits, which is better than performing such a prediction based on clinical data and personality tests. Our code is attached as supplementary and the data would be shared subject to ethical approvals.
Learning Query Expansion over the Nearest Neighbor Graph
Dec 05, 2021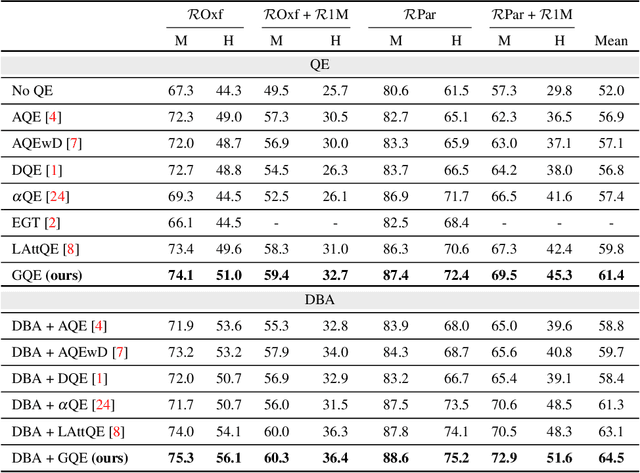
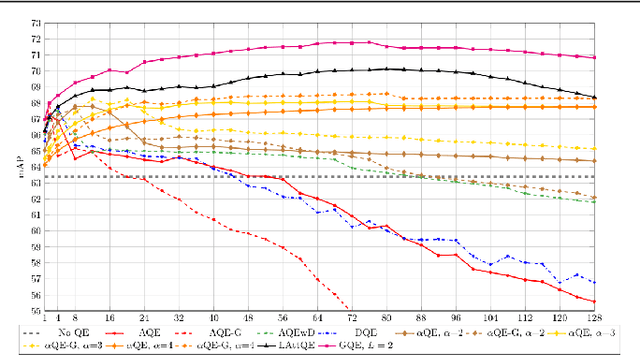
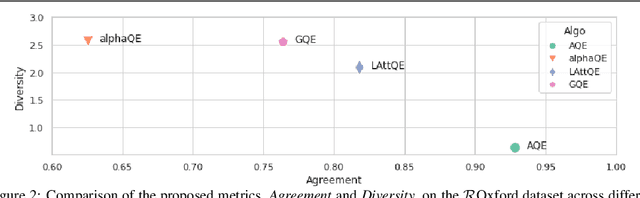
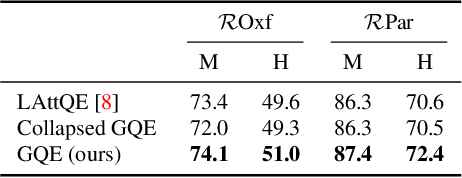
Query Expansion (QE) is a well established method for improving retrieval metrics in image search applications. When using QE, the search is conducted on a new query vector, constructed using an aggregation function over the query and images from the database. Recent works gave rise to QE techniques in which the aggregation function is learned, whereas previous techniques were based on hand-crafted aggregation functions, e.g., taking the mean of the query's nearest neighbors. However, most QE methods have focused on aggregation functions that work directly over the query and its immediate nearest neighbors. In this work, a hierarchical model, Graph Query Expansion (GQE), is presented, which is learned in a supervised manner and performs aggregation over an extended neighborhood of the query, thus increasing the information used from the database when computing the query expansion, and using the structure of the nearest neighbors graph. The technique achieves state-of-the-art results over known benchmarks.
End-to-End Segmentation via Patch-wise Polygons Prediction
Dec 05, 2021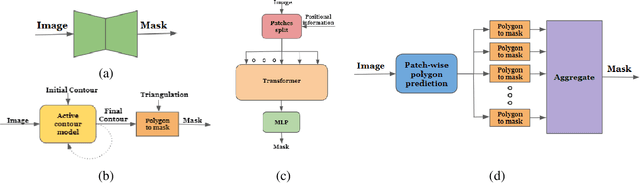
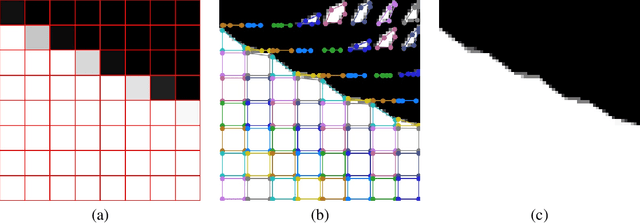
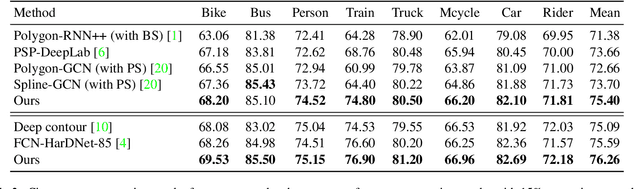
The leading segmentation methods represent the output map as a pixel grid. We study an alternative representation in which the object edges are modeled, per image patch, as a polygon with $k$ vertices that is coupled with per-patch label probabilities. The vertices are optimized by employing a differentiable neural renderer to create a raster image. The delineated region is then compared with the ground truth segmentation. Our method obtains multiple state-of-the-art results: 76.26\% mIoU on the Cityscapes validation, 90.92\% IoU on the Vaihingen building segmentation benchmark, 66.82\% IoU for the MoNU microscopy dataset, and 90.91\% for the bird benchmark CUB. Our code for training and reproducing these results is attached as supplementary.
SegDiff: Image Segmentation with Diffusion Probabilistic Models
Dec 01, 2021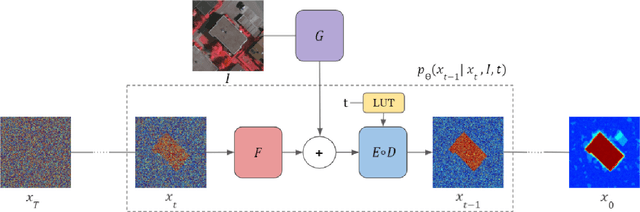
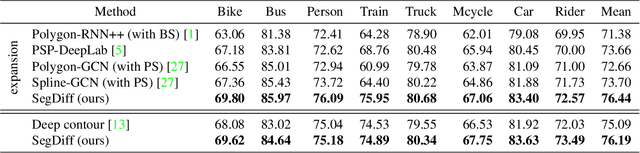

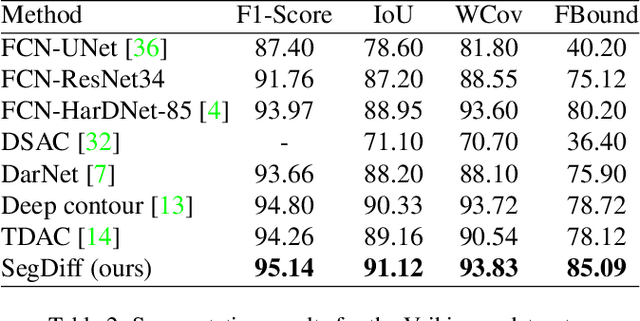
Diffusion Probabilistic Methods are employed for state-of-the-art image generation. In this work, we present a method for extending such models for performing image segmentation. The method learns end-to-end, without relying on a pre-trained backbone. The information in the input image and in the current estimation of the segmentation map is merged by summing the output of two encoders. Additional encoding layers and a decoder are then used to iteratively refine the segmentation map using a diffusion model. Since the diffusion model is probabilistic, it is applied multiple times and the results are merged into a final segmentation map. The new method obtains state-of-the-art results on the Cityscapes validation set, the Vaihingen building segmentation benchmark, and the MoNuSeg dataset.
Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Nov 29, 2021
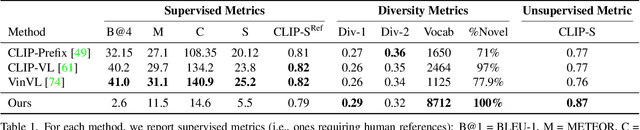
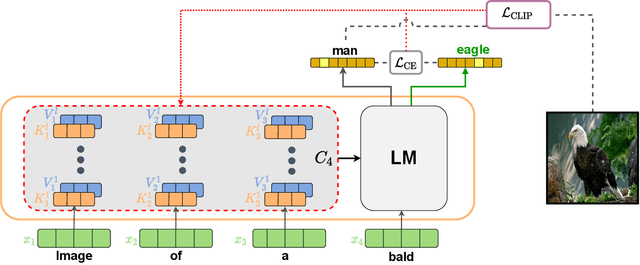

Recent text-to-image matching models apply contrastive learning to large corpora of uncurated pairs of images and sentences. While such models can provide a powerful score for matching and subsequent zero-shot tasks, they are not capable of generating caption given an image. In this work, we repurpose such models to generate a descriptive text given an image at inference time, without any further training or tuning step. This is done by combining the visual-semantic model with a large language model, benefiting from the knowledge in both web-scale models. The resulting captions are much less restrictive than those obtained by supervised captioning methods. Moreover, as a zero-shot learning method, it is extremely flexible and we demonstrate its ability to perform image arithmetic in which the inputs can be either images or text and the output is a sentence. This enables novel high-level vision capabilities such as comparing two images or solving visual analogy tests.