 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models
Jan 31, 2023Recent text-to-image generative models have demonstrated an unparalleled ability to generate diverse and creative imagery guided by a target text prompt. While revolutionary, current state-of-the-art diffusion models may still fail in generating images that fully convey the semantics in the given text prompt. We analyze the publicly available Stable Diffusion model and assess the existence of catastrophic neglect, where the model fails to generate one or more of the subjects from the input prompt. Moreover, we find that in some cases the model also fails to correctly bind attributes (e.g., colors) to their corresponding subjects. To help mitigate these failure cases, we introduce the concept of Generative Semantic Nursing (GSN), where we seek to intervene in the generative process on the fly during inference time to improve the faithfulness of the generated images. Using an attention-based formulation of GSN, dubbed Attend-and-Excite, we guide the model to refine the cross-attention units to attend to all subject tokens in the text prompt and strengthen - or excite - their activations, encouraging the model to generate all subjects described in the text prompt. We compare our approach to alternative approaches and demonstrate that it conveys the desired concepts more faithfully across a range of text prompts.
Deep Quantum Error Correction
Jan 27, 2023Quantum error correction codes (QECC) are a key component for realizing the potential of quantum computing. QECC, as its classical counterpart (ECC), enables the reduction of error rates, by distributing quantum logical information across redundant physical qubits, such that errors can be detected and corrected. In this work, we efficiently train novel deep quantum error decoders. We resolve the quantum measurement collapse by augmenting syndrome decoding to predict an initial estimate of the system noise, which is then refined iteratively through a deep neural network. The logical error rates calculated over finite fields are directly optimized via a differentiable objective, enabling efficient decoding under the constraints imposed by the code. Finally, our architecture is extended to support faulty syndrome measurement, to allow efficient decoding over repeated syndrome sampling. The proposed method demonstrates the power of neural decoders for QECC by achieving state-of-the-art accuracy, outperforming, for a broad range of topological codes, the existing neural and classical decoders, which are often computationally prohibitive.
Separate And Diffuse: Using a Pretrained Diffusion Model for Improving Source Separation
Jan 25, 2023



The problem of speech separation, also known as the cocktail party problem, refers to the task of isolating a single speech signal from a mixture of speech signals. Previous work on source separation derived an upper bound for the source separation task in the domain of human speech. This bound is derived for deterministic models. Recent advancements in generative models challenge this bound. We show how the upper bound can be generalized to the case of random generative models. Applying a diffusion model Vocoder that was pretrained to model single-speaker voices on the output of a deterministic separation model leads to state-of-the-art separation results. It is shown that this requires one to combine the output of the separation model with that of the diffusion model. In our method, a linear combination is performed, in the frequency domain, using weights that are inferred by a learned model. We show state-of-the-art results on 2, 3, 5, 10, and 20 speakers on multiple benchmarks. In particular, for two speakers, our method is able to surpass what was previously considered the upper performance bound.
Generating 2D and 3D Master Faces for Dictionary Attacks with a Network-Assisted Latent Space Evolution
Nov 28, 2022A master face is a face image that passes face-based identity authentication for a high percentage of the population. These faces can be used to impersonate, with a high probability of success, any user, without having access to any user information. We optimize these faces for 2D and 3D face verification models, by using an evolutionary algorithm in the latent embedding space of the StyleGAN face generator. For 2D face verification, multiple evolutionary strategies are compared, and we propose a novel approach that employs a neural network to direct the search toward promising samples, without adding fitness evaluations. The results we present demonstrate that it is possible to obtain a considerable coverage of the identities in the LFW or RFW datasets with less than 10 master faces, for six leading deep face recognition systems. In 3D, we generate faces using the 2D StyleGAN2 generator and predict a 3D structure using a deep 3D face reconstruction network. When employing two different 3D face recognition systems, we are able to obtain a coverage of 40%-50%. Additionally, we present the generation of paired 2D RGB and 3D master faces, which simultaneously match 2D and 3D models with high impersonation rates.
OCD: Learning to Overfit with Conditional Diffusion Models
Oct 10, 2022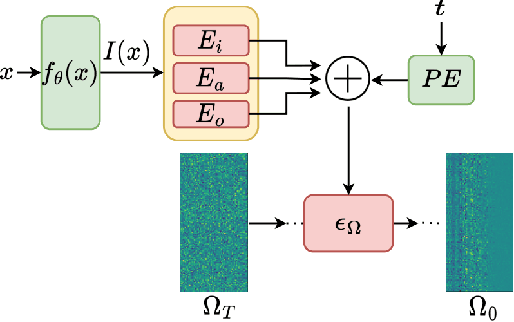
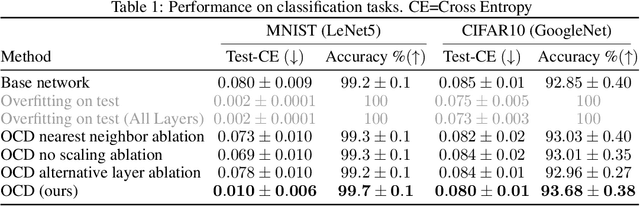
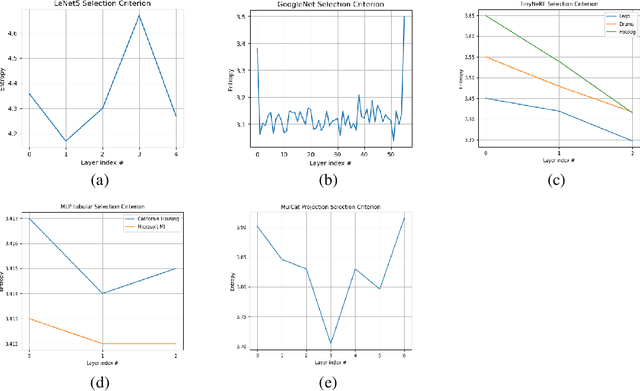
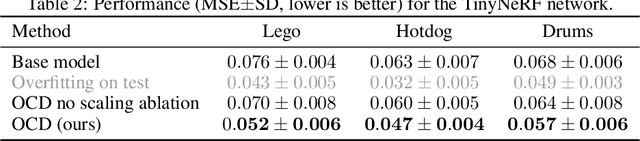
We present a dynamic model in which the weights are conditioned on an input sample x and are learned to match those that would be obtained by finetuning a base model on x and its label y. This mapping between an input sample and network weights is shown to be approximated by a linear transformation of the sample distribution, which suggests that a denoising diffusion model can be suitable for this task. The diffusion model we therefore employ focuses on modifying a single layer of the base model and is conditioned on the input, activations, and output of this layer. Our experiments demonstrate the wide applicability of the method for image classification, 3D reconstruction, tabular data, and speech separation. Our code is available at https://github.com/ShaharLutatiPersonal/OCD.
Denoising Diffusion Error Correction Codes
Sep 16, 2022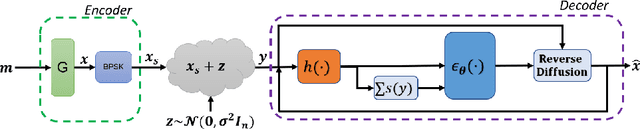
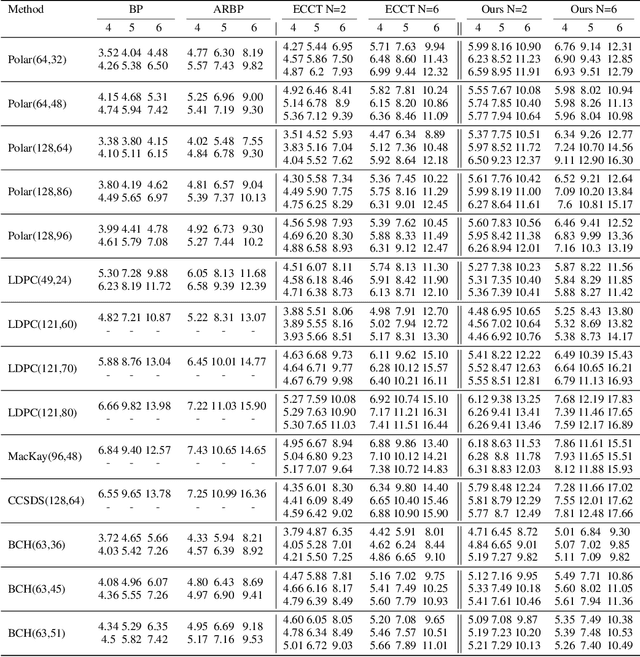
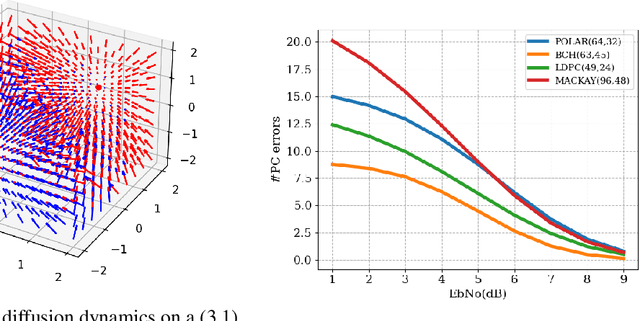
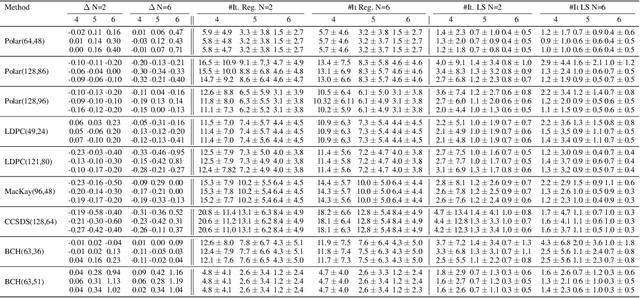
Error correction code (ECC) is an integral part of the physical communication layer, ensuring reliable data transfer over noisy channels. Recently, neural decoders have demonstrated their advantage over classical decoding techniques. However, recent state-of-the-art neural decoders suffer from high complexity and lack the important iterative scheme characteristic of many legacy decoders. In this work, we propose to employ denoising diffusion models for the soft decoding of linear codes at arbitrary block lengths. Our framework models the forward channel corruption as a series of diffusion steps that can be reversed iteratively. Three contributions are made: (i) a diffusion process suitable for the decoding setting is introduced, (ii) the neural diffusion decoder is conditioned on the number of parity errors, which indicates the level of corruption at a given step, (iii) a line search procedure based on the code's syndrome obtains the optimal reverse diffusion step size. The proposed approach demonstrates the power of diffusion models for ECC and is able to achieve state of the art accuracy, outperforming the other neural decoders by sizable margins, even for a single reverse diffusion step.
Semi-supervised Learning of Partial Differential Operators and Dynamical Flows
Jul 28, 2022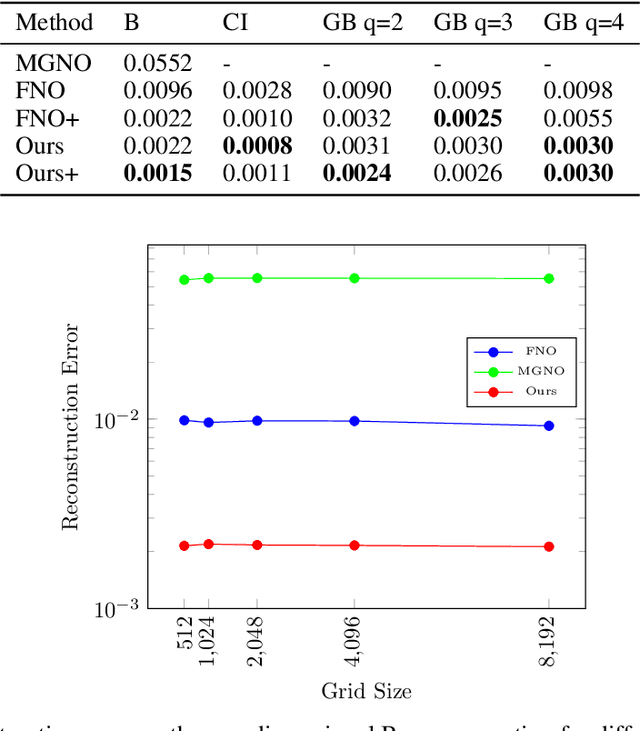
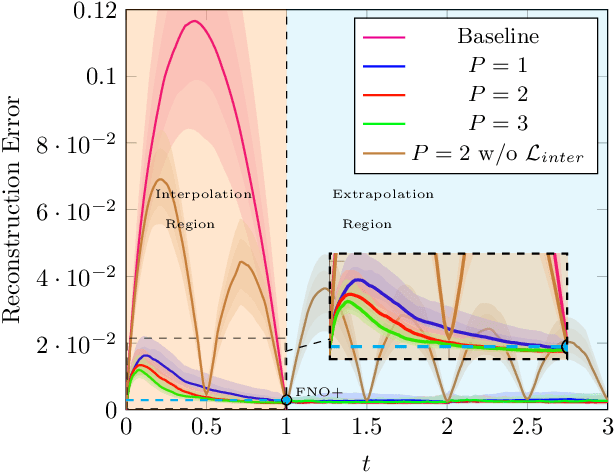

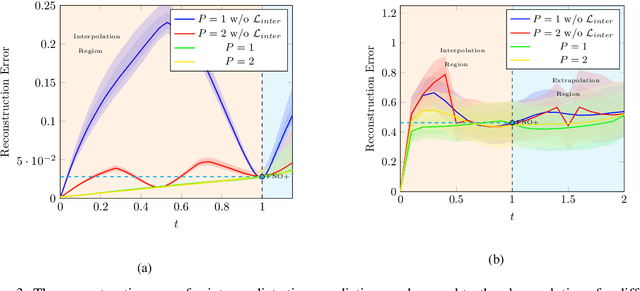
The evolution of dynamical systems is generically governed by nonlinear partial differential equations (PDEs), whose solution, in a simulation framework, requires vast amounts of computational resources. In this work, we present a novel method that combines a hyper-network solver with a Fourier Neural Operator architecture. Our method treats time and space separately. As a result, it successfully propagates initial conditions in continuous time steps by employing the general composition properties of the partial differential operators. Following previous work, supervision is provided at a specific time point. We test our method on various time evolution PDEs, including nonlinear fluid flows in one, two, and three spatial dimensions. The results show that the new method improves the learning accuracy at the time point of supervision point, and is able to interpolate and the solutions to any intermediate time.
Zero-Shot Video Captioning with Evolving Pseudo-Tokens
Jul 27, 2022
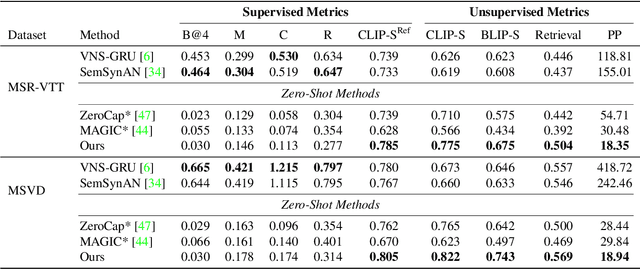
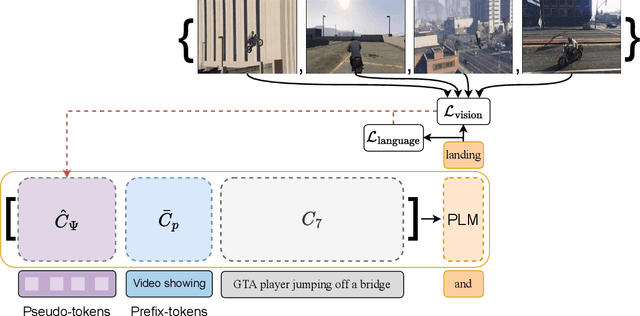
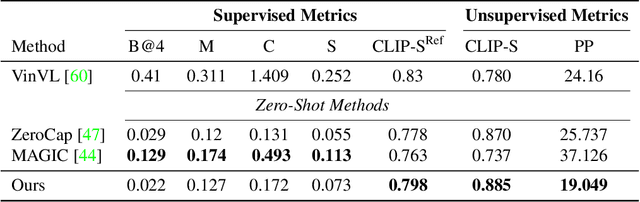
We introduce a zero-shot video captioning method that employs two frozen networks: the GPT-2 language model and the CLIP image-text matching model. The matching score is used to steer the language model toward generating a sentence that has a high average matching score to a subset of the video frames. Unlike zero-shot image captioning methods, our work considers the entire sentence at once. This is achieved by optimizing, during the generation process, part of the prompt from scratch, by modifying the representation of all other tokens in the prompt, and by repeating the process iteratively, gradually improving the specificity and comprehensiveness of the generated sentence. Our experiments show that the generated captions are coherent and display a broad range of real-world knowledge. Our code is available at: https://github.com/YoadTew/zero-shot-video-to-text
FewGAN: Generating from the Joint Distribution of a Few Images
Jul 18, 2022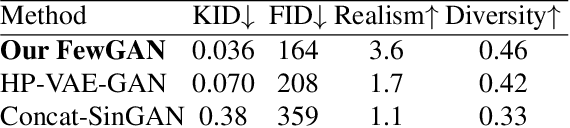
We introduce FewGAN, a generative model for generating novel, high-quality and diverse images whose patch distribution lies in the joint patch distribution of a small number of N>1 training samples. The method is, in essence, a hierarchical patch-GAN that applies quantization at the first coarse scale, in a similar fashion to VQ-GAN, followed by a pyramid of residual fully convolutional GANs at finer scales. Our key idea is to first use quantization to learn a fixed set of patch embeddings for training images. We then use a separate set of side images to model the structure of generated images using an autoregressive model trained on the learned patch embeddings of training images. Using quantization at the coarsest scale allows the model to generate both conditional and unconditional novel images. Subsequently, a patch-GAN renders the fine details, resulting in high-quality images. In an extensive set of experiments, it is shown that FewGAN outperforms baselines both quantitatively and qualitatively.
What is Where by Looking: Weakly-Supervised Open-World Phrase-Grounding without Text Inputs
Jun 27, 2022

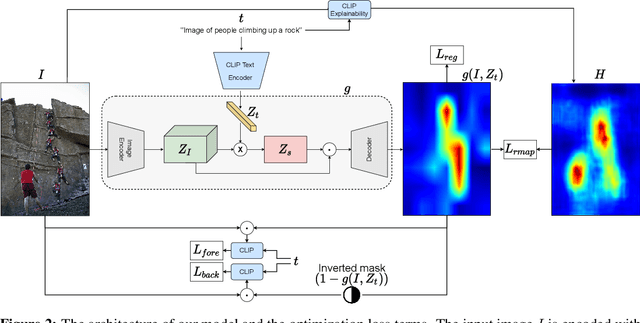

Given an input image, and nothing else, our method returns the bounding boxes of objects in the image and phrases that describe the objects. This is achieved within an open world paradigm, in which the objects in the input image may not have been encountered during the training of the localization mechanism. Moreover, training takes place in a weakly supervised setting, where no bounding boxes are provided. To achieve this, our method combines two pre-trained networks: the CLIP image-to-text matching score and the BLIP image captioning tool. Training takes place on COCO images and their captions and is based on CLIP. Then, during inference, BLIP is used to generate a hypothesis regarding various regions of the current image. Our work generalizes weakly supervised segmentation and phrase grounding and is shown empirically to outperform the state of the art in both domains. It also shows very convincing results in the novel task of weakly-supervised open-world purely visual phrase-grounding presented in our work. For example, on the datasets used for benchmarking phrase-grounding, our method results in a very modest degradation in comparison to methods that employ human captions as an additional input. Our code is available at https://github.com/talshaharabany/what-is-where-by-looking and a live demo can be found at https://replicate.com/talshaharabany/what-is-where-by-looking.