 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Tangent Kernels
Feb 18, 2020
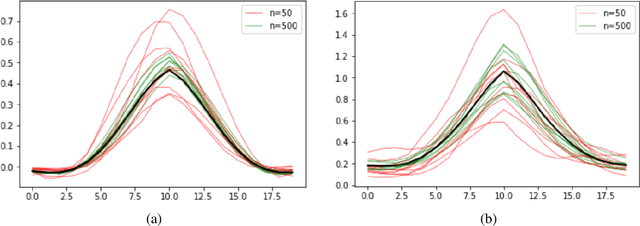

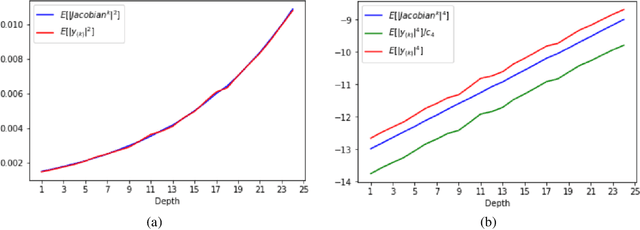
A recent body of work has focused on the theoretical study of neural networks at the regime of large width. Specifically, it was shown that training infinitely-wide and properly scaled vanilla ReLU networks using the L2 loss, is equivalent to kernel regression using the Neural Tangent Kernel (NTK), which is deterministic, and remains constant during training. In this work, we derive the form of the limiting kernel for architectures incorporating bypass connections, namely residual networks (ResNets), as well as to densely connected networks (DenseNets). In addition, we derive finite width and depth corrections for both cases. Our analysis reveals that deep practical residual architectures might operate much closer to the ``kernel regime'' than their vanilla counterparts: while in networks that do not use skip connections, convergence to the NTK requires one to fix depth, while increasing the layers' width. Our findings show that in ResNets, convergence to the NTK may occur when depth and width simultaneously tend to infinity, provided proper initialization. In DenseNets, however, convergence to the NTK as the width tend to infinity is guaranteed, at a rate that is independent of both depth and scale of the weights.
Molecule Property Prediction and Classification with Graph Hypernetworks
Feb 01, 2020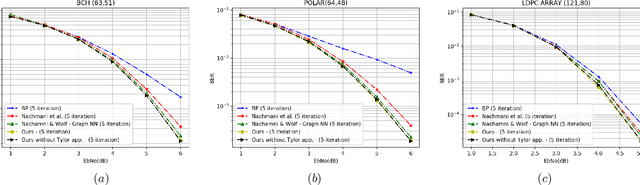
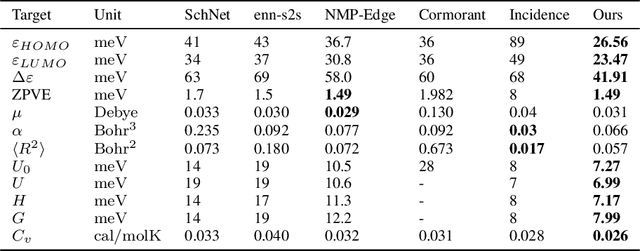

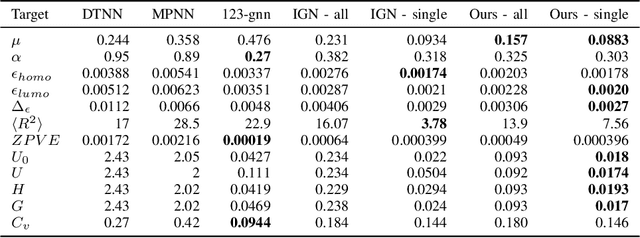
Graph neural networks are currently leading the performance charts in learning-based molecule property prediction and classification. Computational chemistry has, therefore, become the a prominent testbed for generic graph neural networks, as well as for specialized message passing methods. In this work, we demonstrate that the replacement of the underlying networks with hypernetworks leads to a boost in performance, obtaining state of the art results in various benchmarks. A major difficulty in the application of hypernetworks is their lack of stability. We tackle this by combining the current message and the first message. A recent work has tackled the training instability of hypernetworks in the context of error correcting codes, by replacing the activation function of the message passing network with a low-order Taylor approximation of it. We demonstrate that our generic solution can replace this domain-specific solution.
Structured GANs
Jan 15, 2020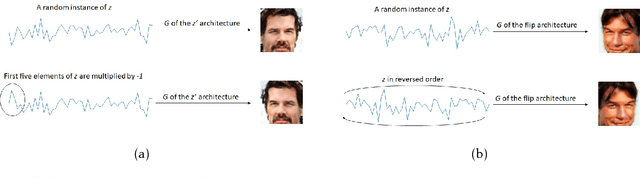

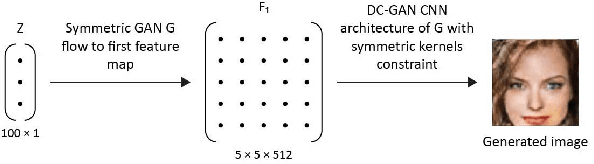
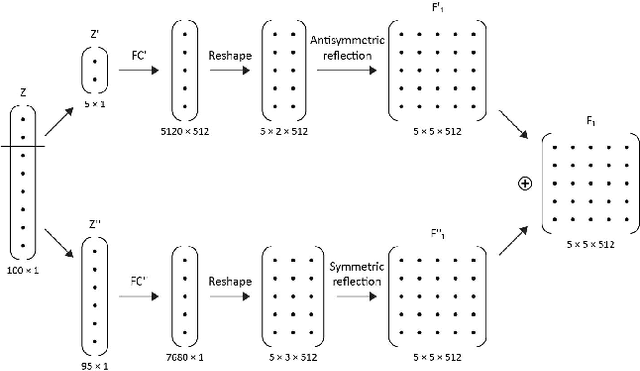
We present Generative Adversarial Networks (GANs), in which the symmetric property of the generated images is controlled. This is obtained through the generator network's architecture, while the training procedure and the loss remain the same. The symmetric GANs are applied to face image synthesis in order to generate novel faces with a varying amount of symmetry. We also present an unsupervised face rotation capability, which is based on the novel notion of one-shot fine tuning.
A Formal Approach to Explainability
Jan 15, 2020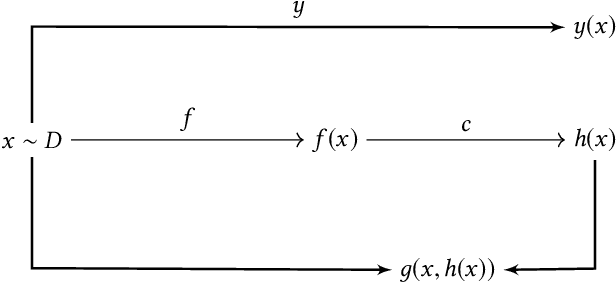
We regard explanations as a blending of the input sample and the model's output and offer a few definitions that capture various desired properties of the function that generates these explanations. We study the links between these properties and between explanation-generating functions and intermediate representations of learned models and are able to show, for example, that if the activations of a given layer are consistent with an explanation, then so do all other subsequent layers. In addition, we study the intersection and union of explanations as a way to construct new explanations.
Microvascular Dynamics from 4D Microscopy Using Temporal Segmentation
Jan 14, 2020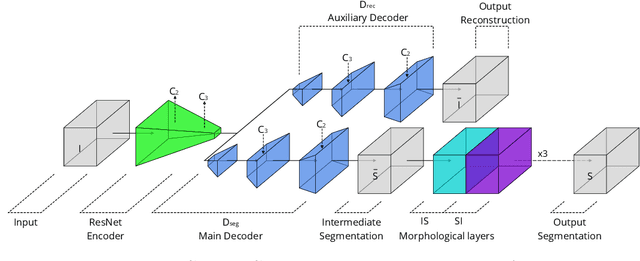



Recently developed methods for rapid continuous volumetric two-photon microscopy facilitate the observation of neuronal activity in hundreds of individual neurons and changes in blood flow in adjacent blood vessels across a large volume of living brain at unprecedented spatio-temporal resolution. However, the high imaging rate necessitates fully automated image analysis, whereas tissue turbidity and photo-toxicity limitations lead to extremely sparse and noisy imagery. In this work, we extend a recently proposed deep learning volumetric blood vessel segmentation network, such that it supports temporal analysis. With this technology, we are able to track changes in cerebral blood volume over time and identify spontaneous arterial dilations that propagate towards the pial surface. This new capability is a promising step towards characterizing the hemodynamic response function upon which functional magnetic resonance imaging (fMRI) is based.
A Sample Selection Approach for Universal Domain Adaptation
Jan 14, 2020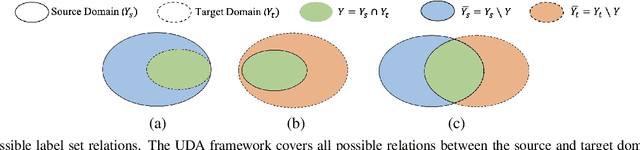
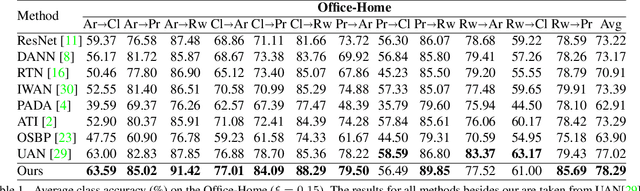
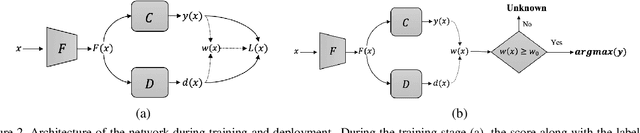
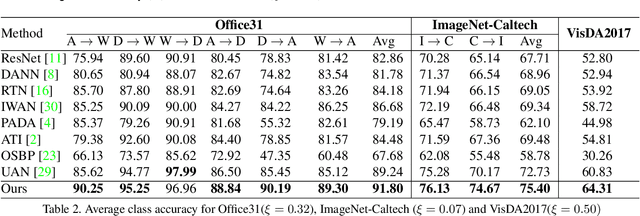
We study the problem of unsupervised domain adaption in the universal scenario, in which only some of the classes are shared between the source and target domains. We present a scoring scheme that is effective in identifying the samples of the shared classes. The score is used to select which samples in the target domain to pseudo-label during training. Another loss term encourages diversity of labels within each batch. Taken together, our method is shown to outperform, by a sizable margin, the current state of the art on the literature benchmarks.
Single Image Depth Estimation Trained via Depth from Defocus Cues
Jan 14, 2020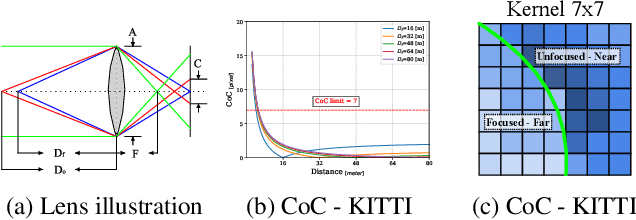


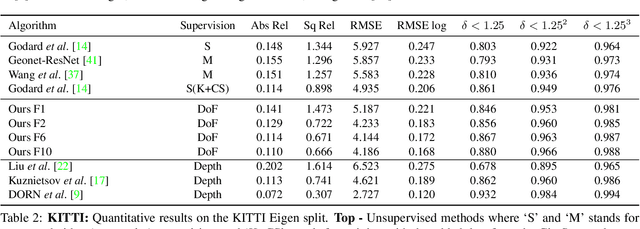
Estimating depth from a single RGB images is a fundamental task in computer vision, which is most directly solved using supervised deep learning. In the field of unsupervised learning of depth from a single RGB image, depth is not given explicitly. Existing work in the field receives either a stereo pair, a monocular video, or multiple views, and, using losses that are based on structure-from-motion, trains a depth estimation network. In this work, we rely, instead of different views, on depth from focus cues. Learning is based on a novel Point Spread Function convolutional layer, which applies location specific kernels that arise from the Circle-Of-Confusion in each image location. We evaluate our method on data derived from five common datasets for depth estimation and lightfield images, and present results that are on par with supervised methods on KITTI and Make3D datasets and outperform unsupervised learning approaches. Since the phenomenon of depth from defocus is not dataset specific, we hypothesize that learning based on it would overfit less to the specific content in each dataset. Our experiments show that this is indeed the case, and an estimator learned on one dataset using our method provides better results on other datasets, than the directly supervised methods.
Unsupervised Learning of the Set of Local Maxima
Jan 14, 2020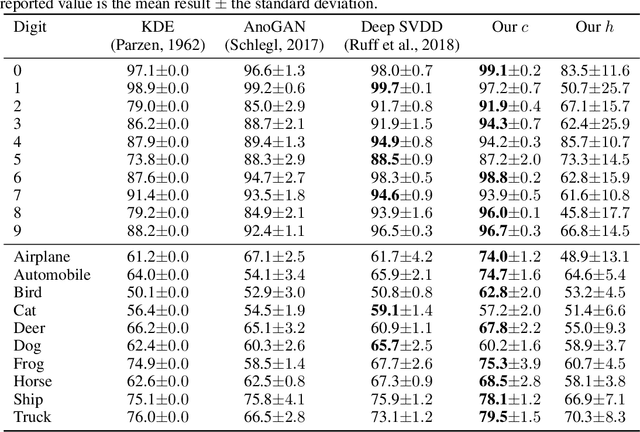
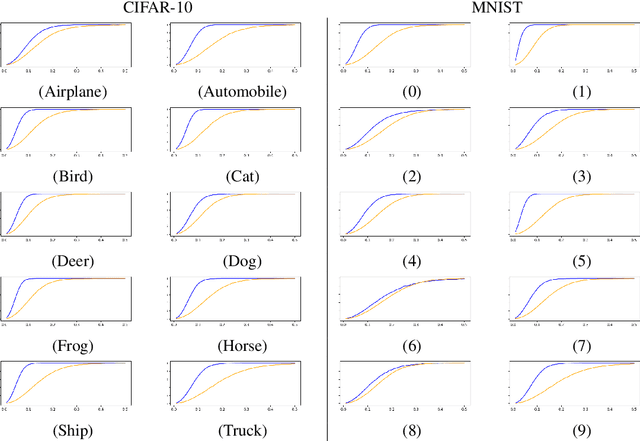
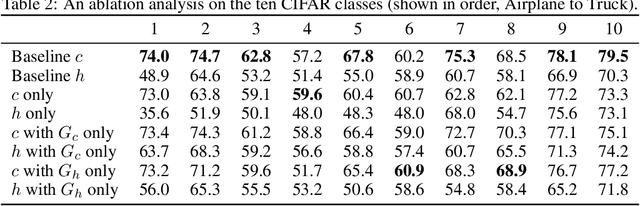
This paper describes a new form of unsupervised learning, whose input is a set of unlabeled points that are assumed to be local maxima of an unknown value function v in an unknown subset of the vector space. Two functions are learned: (i) a set indicator c, which is a binary classifier, and (ii) a comparator function h that given two nearby samples, predicts which sample has the higher value of the unknown function v. Loss terms are used to ensure that all training samples x are a local maxima of v, according to h and satisfy c(x)=1. Therefore, c and h provide training signals to each other: a point x' in the vicinity of x satisfies c(x)=-1 or is deemed by h to be lower in value than x. We present an algorithm, show an example where it is more efficient to use local maxima as an indicator function than to employ conventional classification, and derive a suitable generalization bound. Our experiments show that the method is able to outperform one-class classification algorithms in the task of anomaly detection and also provide an additional signal that is extracted in a completely unsupervised way.
Emerging Disentanglement in Auto-Encoder Based Unsupervised Image Content Transfer
Jan 14, 2020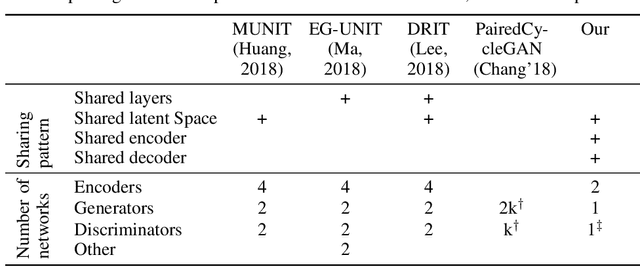


We study the problem of learning to map, in an unsupervised way, between domains A and B, such that the samples b in B contain all the information that exists in samples a in A and some additional information. For example, ignoring occlusions, B can be people with glasses, A people without, and the glasses, would be the added information. When mapping a sample a from the first domain to the other domain, the missing information is replicated from an independent reference sample b in B. Thus, in the above example, we can create, for every person without glasses a version with the glasses observed in any face image. Our solution employs a single two-pathway encoder and a single decoder for both domains. The common part of the two domains and the separate part are encoded as two vectors, and the separate part is fixed at zero for domain A. The loss terms are minimal and involve reconstruction losses for the two domains and a domain confusion term. Our analysis shows that under mild assumptions, this architecture, which is much simpler than the literature guided-translation methods, is enough to ensure disentanglement between the two domains. We present convincing results in a few visual domains, such as no-glasses to glasses, adding facial hair based on a reference image, etc.
On the Convex Behavior of Deep Neural Networks in Relation to the Layers' Width
Jan 14, 2020
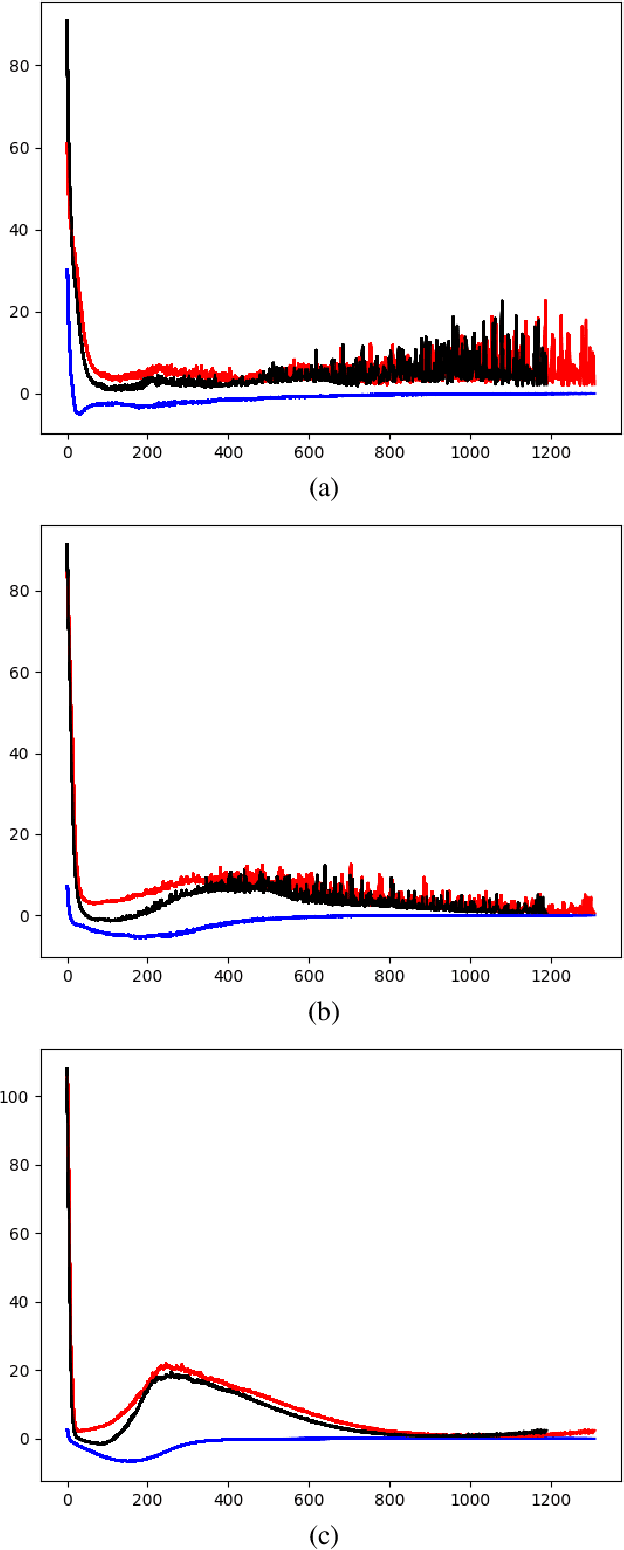
The Hessian of neural networks can be decomposed into a sum of two matrices: (i) the positive semidefinite generalized Gauss-Newton matrix G, and (ii) the matrix H containing negative eigenvalues. We observe that for wider networks, minimizing the loss with the gradient descent optimization maneuvers through surfaces of positive curvatures at the start and end of training, and close to zero curvatures in between. In other words, it seems that during crucial parts of the training process, the Hessian in wide networks is dominated by the component G. To explain this phenomenon, we show that when initialized using common methodologies, the gradients of over-parameterized networks are approximately orthogonal to H, such that the curvature of the loss surface is strictly positive in the direction of the gradient.