Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sample Selection Approach for Universal Domain Adaptation
Jan 14, 2020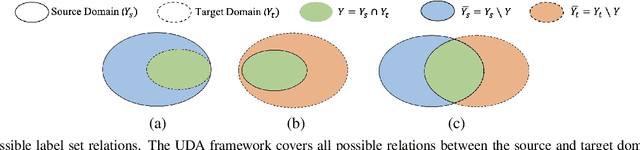
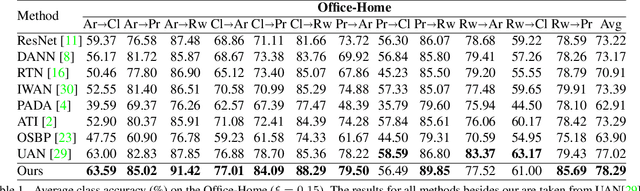
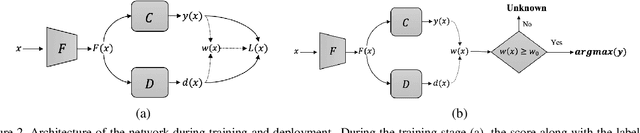
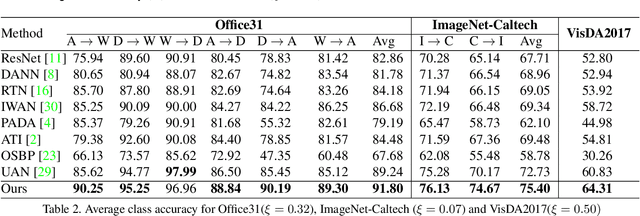
We study the problem of unsupervised domain adaption in the universal scenario, in which only some of the classes are shared between the source and target domains. We present a scoring scheme that is effective in identifying the samples of the shared classes. The score is used to select which samples in the target domain to pseudo-label during training. Another loss term encourages diversity of labels within each batch. Taken together, our method is shown to outperform, by a sizable margin, the current state of the art on the literature benchmarks.
Via