 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Weight Map for Weakly-Supervised Localization
Nov 28, 2021
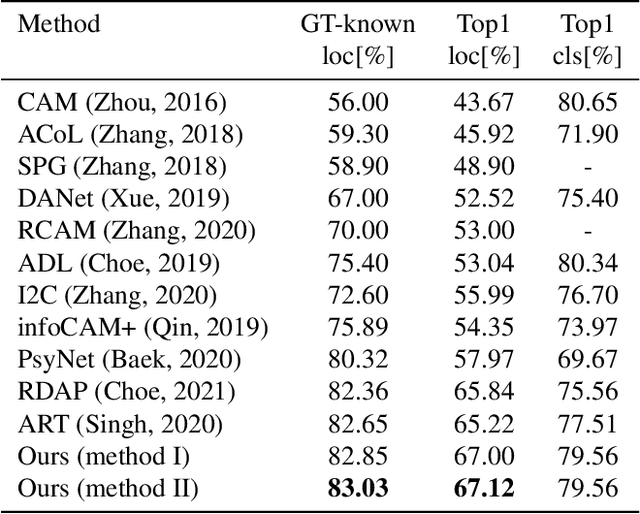
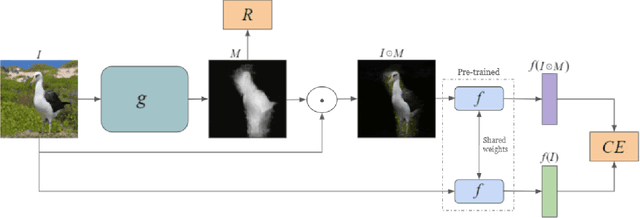
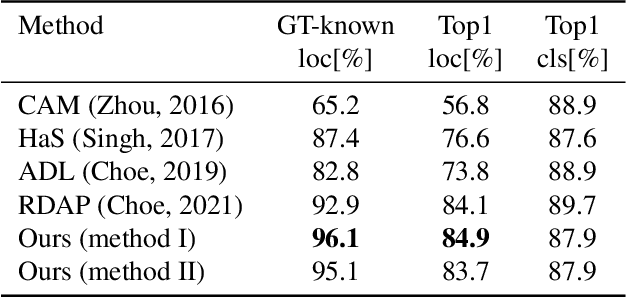
In the weakly supervised localization setting, supervision is given as an image-level label. We propose to employ an image classifier $f$ and to train a generative network $g$ that outputs, given the input image, a per-pixel weight map that indicates the location of the object within the image. Network $g$ is trained by minimizing the discrepancy between the output of the classifier $f$ on the original image and its output given the same image weighted by the output of $g$. The scheme requires a regularization term that ensures that $g$ does not provide a uniform weight, and an early stopping criterion in order to prevent $g$ from over-segmenting the image. Our results indicate that the method outperforms existing localization methods by a sizable margin on the challenging fine-grained classification datasets, as well as a generic image recognition dataset. Additionally, the obtained weight map is also state-of-the-art in weakly supervised segmentation in fine-grained categorization datasets.
A-Muze-Net: Music Generation by Composing the Harmony based on the Generated Melody
Nov 25, 2021
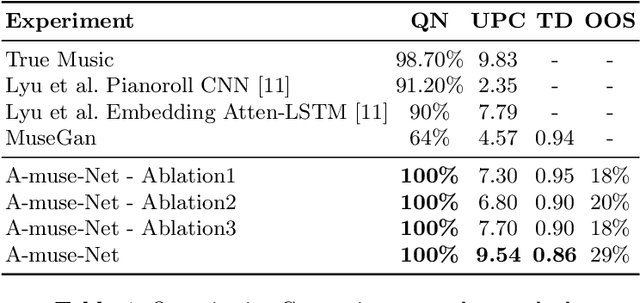

We present a method for the generation of Midi files of piano music. The method models the right and left hands using two networks, where the left hand is conditioned on the right hand. This way, the melody is generated before the harmony. The Midi is represented in a way that is invariant to the musical scale, and the melody is represented, for the purpose of conditioning the harmony, by the content of each bar, viewed as a chord. Finally, notes are added randomly, based on this chord representation, in order to enrich the generated audio. Our experiments show a significant improvement over the state of the art for training on such datasets, and demonstrate the contribution of each of the novel components.
Geometric Transformer for End-to-End Molecule Properties Prediction
Oct 26, 2021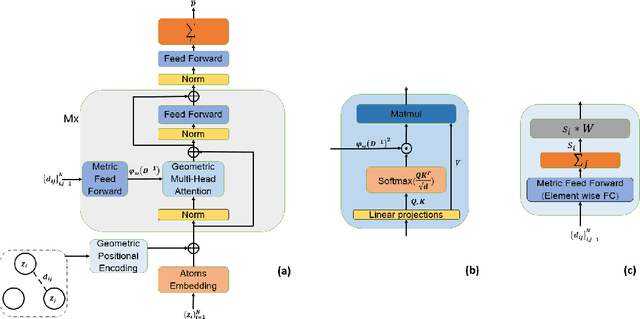
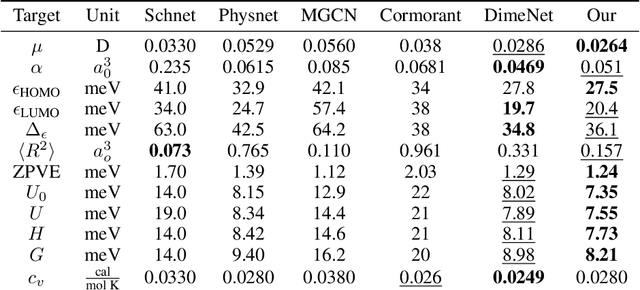
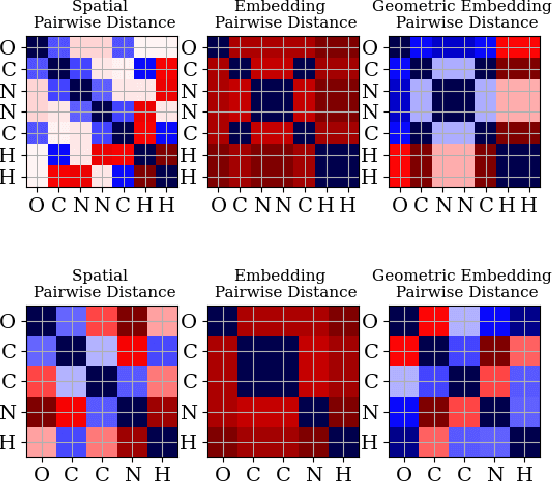
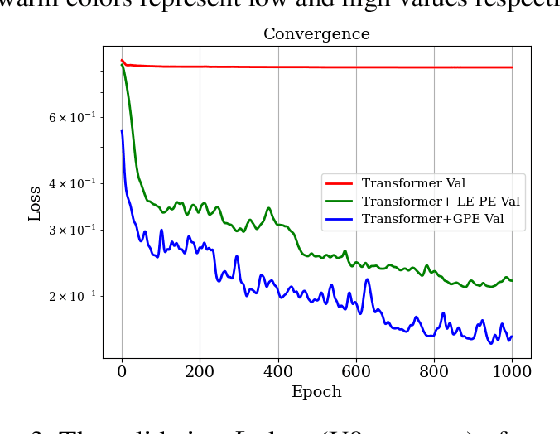
Transformers have become methods of choice in many applications thanks to their ability to represent complex interaction between elements. However, extending the Transformer architecture to non-sequential data such as molecules and enabling its training on small datasets remain a challenge. In this work, we introduce a Transformer-based architecture for molecule property prediction, which is able to capture the geometry of the molecule. We modify the classical positional encoder by an initial encoding of the molecule geometry, as well as a learned gated self-attention mechanism. We further suggest an augmentation scheme for molecular data capable of avoiding the overfitting induced by the overparameterized architecture. The proposed framework outperforms the state-of-the-art methods while being based on pure machine learning solely, i.e. the method does not incorporate domain knowledge from quantum chemistry and does not use extended geometric inputs beside the pairwise atomic distances.
Image-Based CLIP-Guided Essence Transfer
Oct 26, 2021


The conceptual blending of two signals is a semantic task that may underline both creativity and intelligence. We propose to perform such blending in a way that incorporates two latent spaces: that of the generator network and that of the semantic network. For the first network, we employ the powerful StyleGAN generator, and for the second, the powerful image-language matching network of CLIP. The new method creates a blending operator that is optimized to be simultaneously additive in both latent spaces. Our results demonstrate that this leads to blending that is much more natural than what can be obtained in each space separately.
Video and Text Matching with Conditioned Embeddings
Oct 21, 2021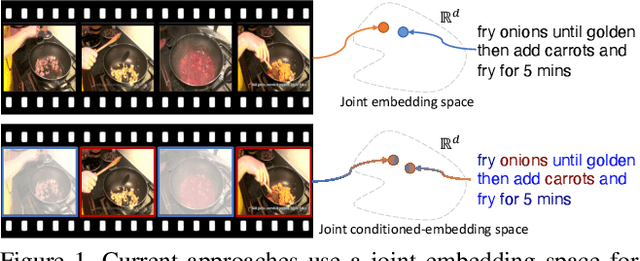
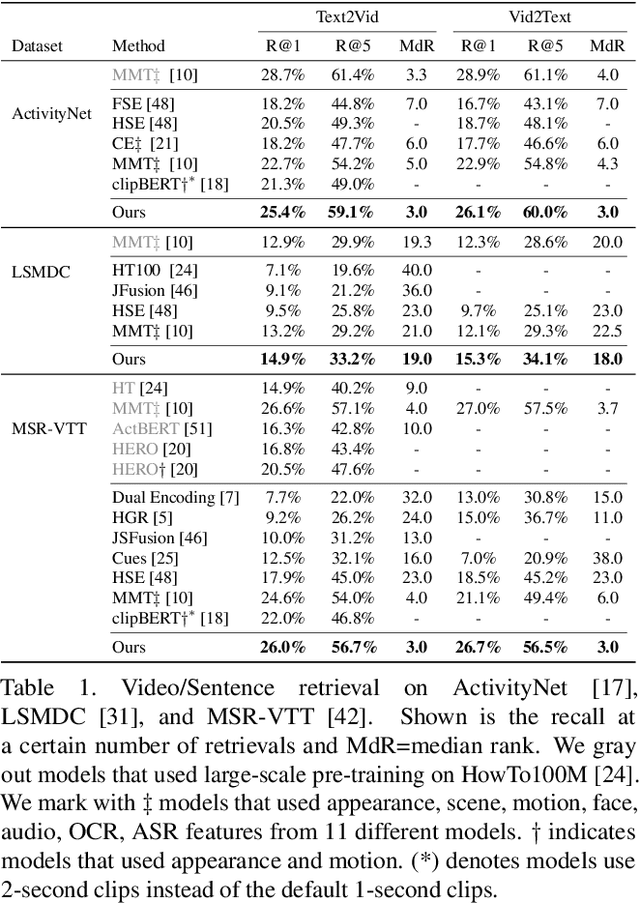
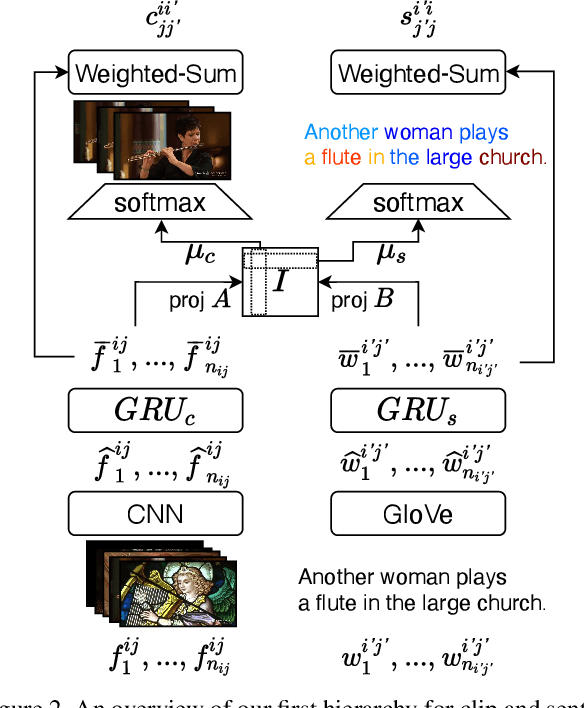
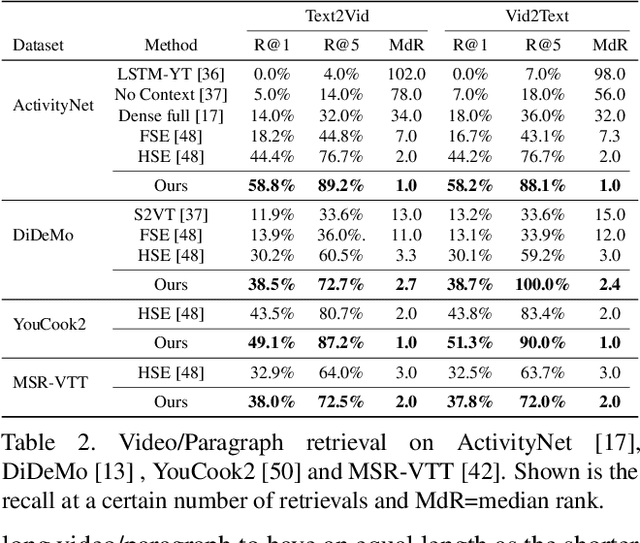
We present a method for matching a text sentence from a given corpus to a given video clip and vice versa. Traditionally video and text matching is done by learning a shared embedding space and the encoding of one modality is independent of the other. In this work, we encode the dataset data in a way that takes into account the query's relevant information. The power of the method is demonstrated to arise from pooling the interaction data between words and frames. Since the encoding of the video clip depends on the sentence compared to it, the representation needs to be recomputed for each potential match. To this end, we propose an efficient shallow neural network. Its training employs a hierarchical triplet loss that is extendable to paragraph/video matching. The method is simple, provides explainability, and achieves state-of-the-art results for both sentence-clip and video-text by a sizable margin across five different datasets: ActivityNet, DiDeMo, YouCook2, MSR-VTT, and LSMDC. We also show that our conditioned representation can be transferred to video-guided machine translation, where we improved the current results on VATEX. Source code is available at https://github.com/AmeenAli/VideoMatch.
Denoising Diffusion Gamma Models
Oct 10, 2021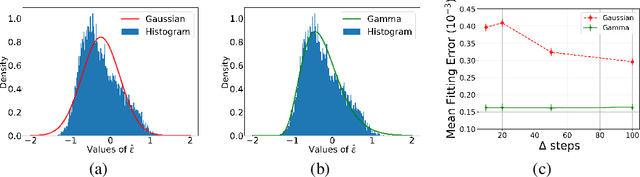
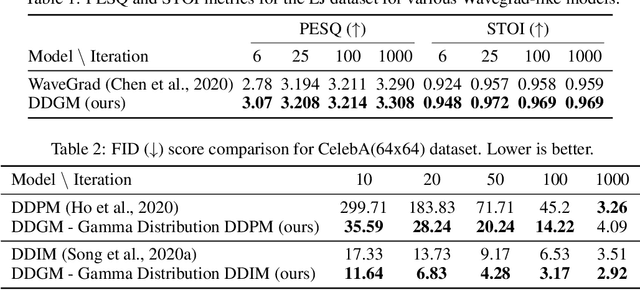
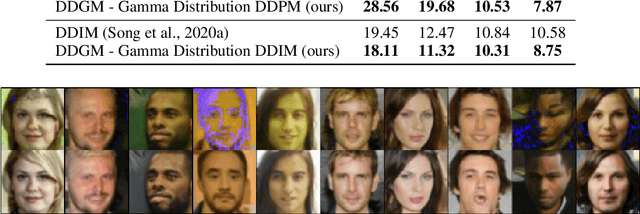
Generative diffusion processes are an emerging and effective tool for image and speech generation. In the existing methods, the underlying noise distribution of the diffusion process is Gaussian noise. However, fitting distributions with more degrees of freedom could improve the performance of such generative models. In this work, we investigate other types of noise distribution for the diffusion process. Specifically, we introduce the Denoising Diffusion Gamma Model (DDGM) and show that noise from Gamma distribution provides improved results for image and speech generation. Our approach preserves the ability to efficiently sample state in the training diffusion process while using Gamma noise.
Meta Internal Learning
Oct 06, 2021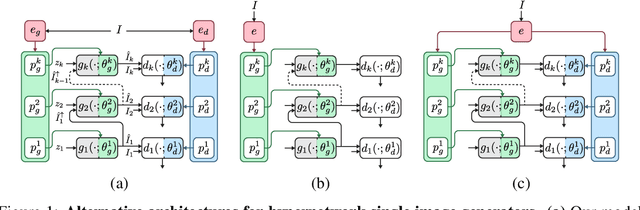
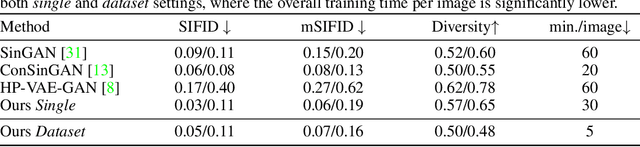


Internal learning for single-image generation is a framework, where a generator is trained to produce novel images based on a single image. Since these models are trained on a single image, they are limited in their scale and application. To overcome these issues, we propose a meta-learning approach that enables training over a collection of images, in order to model the internal statistics of the sample image more effectively. In the presented meta-learning approach, a single-image GAN model is generated given an input image, via a convolutional feedforward hypernetwork $f$. This network is trained over a dataset of images, allowing for feature sharing among different models, and for interpolation in the space of generative models. The generated single-image model contains a hierarchy of multiple generators and discriminators. It is therefore required to train the meta-learner in an adversarial manner, which requires careful design choices that we justify by a theoretical analysis. Our results show that the models obtained are as suitable as single-image GANs for many common image applications, significantly reduce the training time per image without loss in performance, and introduce novel capabilities, such as interpolation and feedforward modeling of novel images.
Caption Enriched Samples for Improving Hateful Memes Detection
Sep 22, 2021
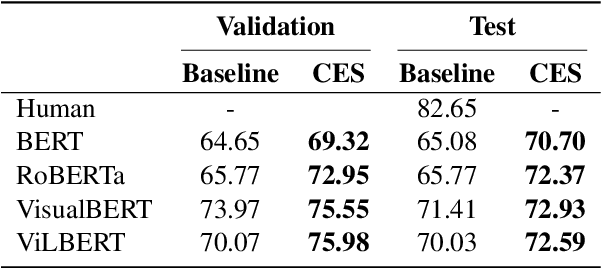

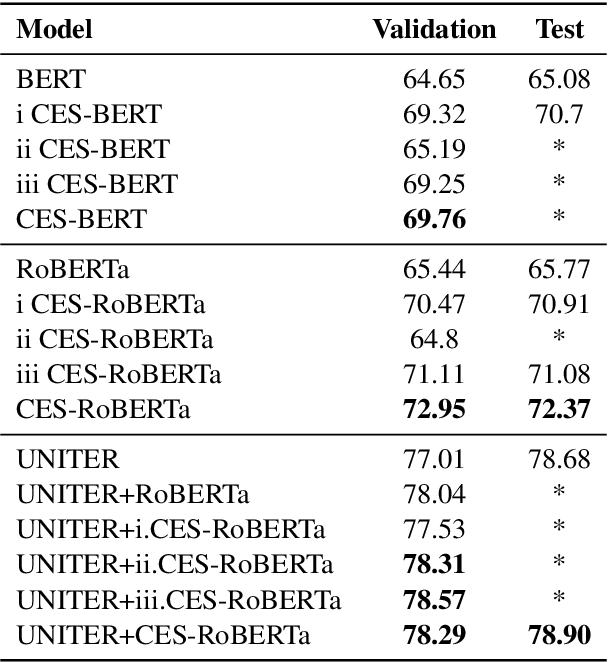
The recently introduced hateful meme challenge demonstrates the difficulty of determining whether a meme is hateful or not. Specifically, both unimodal language models and multimodal vision-language models cannot reach the human level of performance. Motivated by the need to model the contrast between the image content and the overlayed text, we suggest applying an off-the-shelf image captioning tool in order to capture the first. We demonstrate that the incorporation of such automatic captions during fine-tuning improves the results for various unimodal and multimodal models. Moreover, in the unimodal case, continuing the pre-training of language models on augmented and original caption pairs, is highly beneficial to the classification accuracy.
Mixing between the Cross Entropy and the Expectation Loss Terms
Sep 12, 2021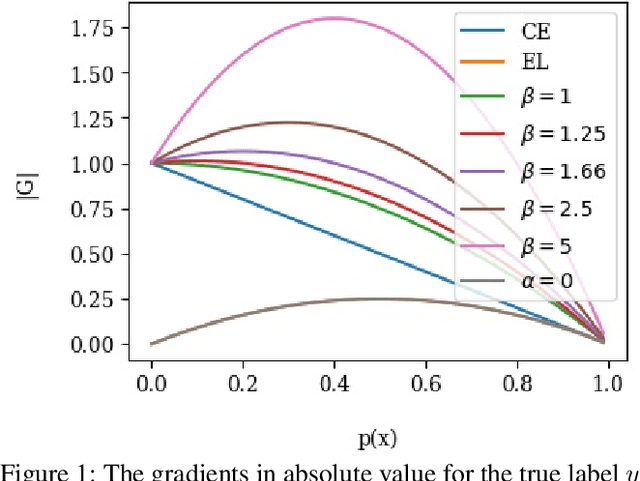
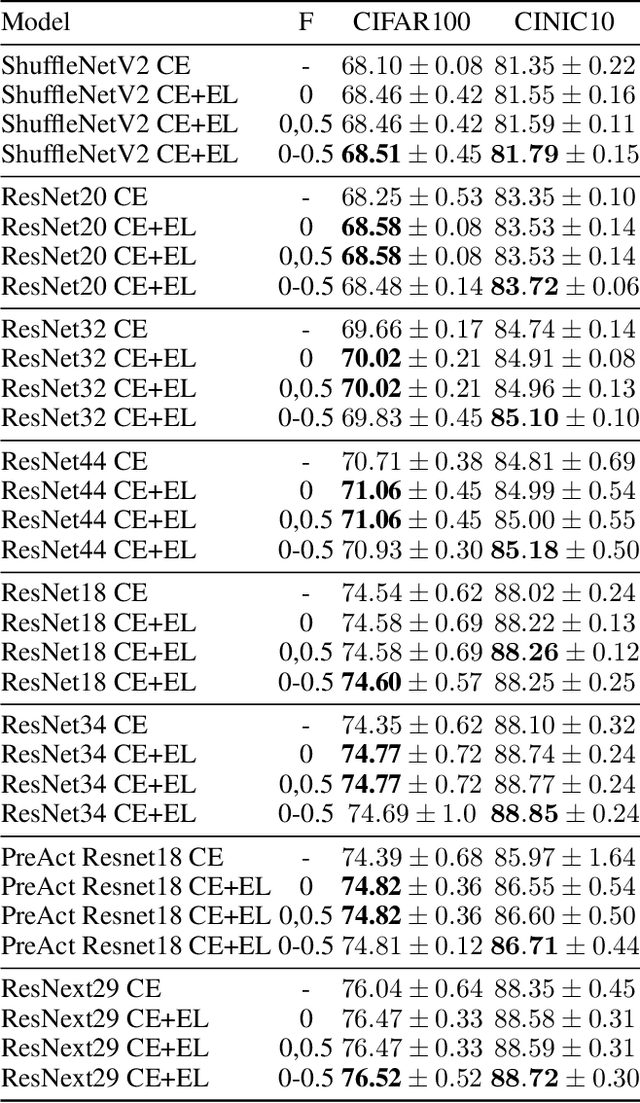
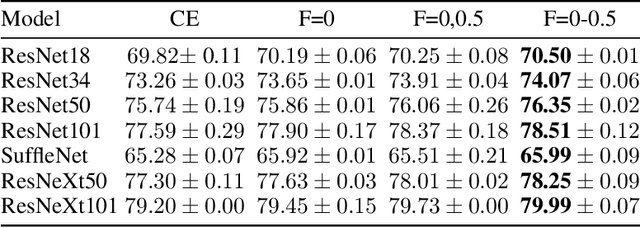
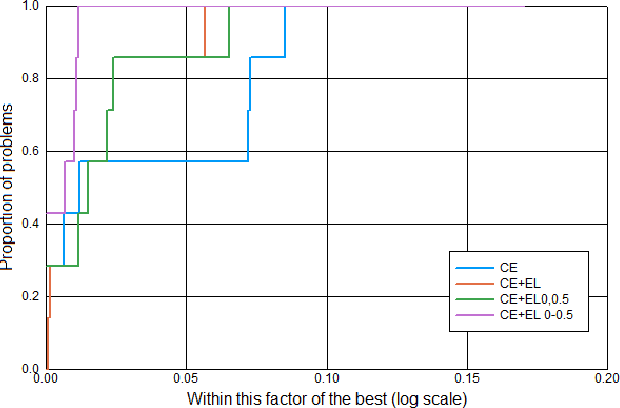
The cross entropy loss is widely used due to its effectiveness and solid theoretical grounding. However, as training progresses, the loss tends to focus on hard to classify samples, which may prevent the network from obtaining gains in performance. While most work in the field suggest ways to classify hard negatives, we suggest to strategically leave hard negatives behind, in order to focus on misclassified samples with higher probabilities. We show that adding to the optimization goal the expectation loss, which is a better approximation of the zero-one loss, helps the network to achieve better accuracy. We, therefore, propose to shift between the two losses during training, focusing more on the expectation loss gradually during the later stages of training. Our experiments show that the new training protocol improves performance across a diverse set of classification domains, including computer vision, natural language processing, tabular data, and sequences. Our code and scripts are available at supplementary.
Generating Master Faces for Dictionary Attacks with a Network-Assisted Latent Space Evolution
Aug 19, 2021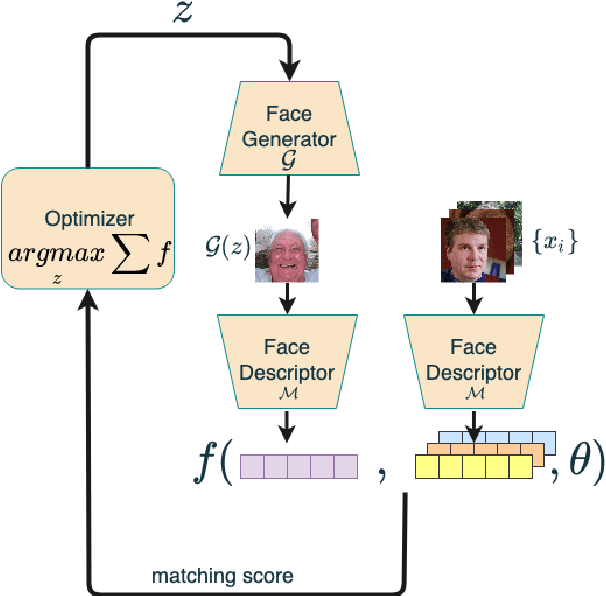


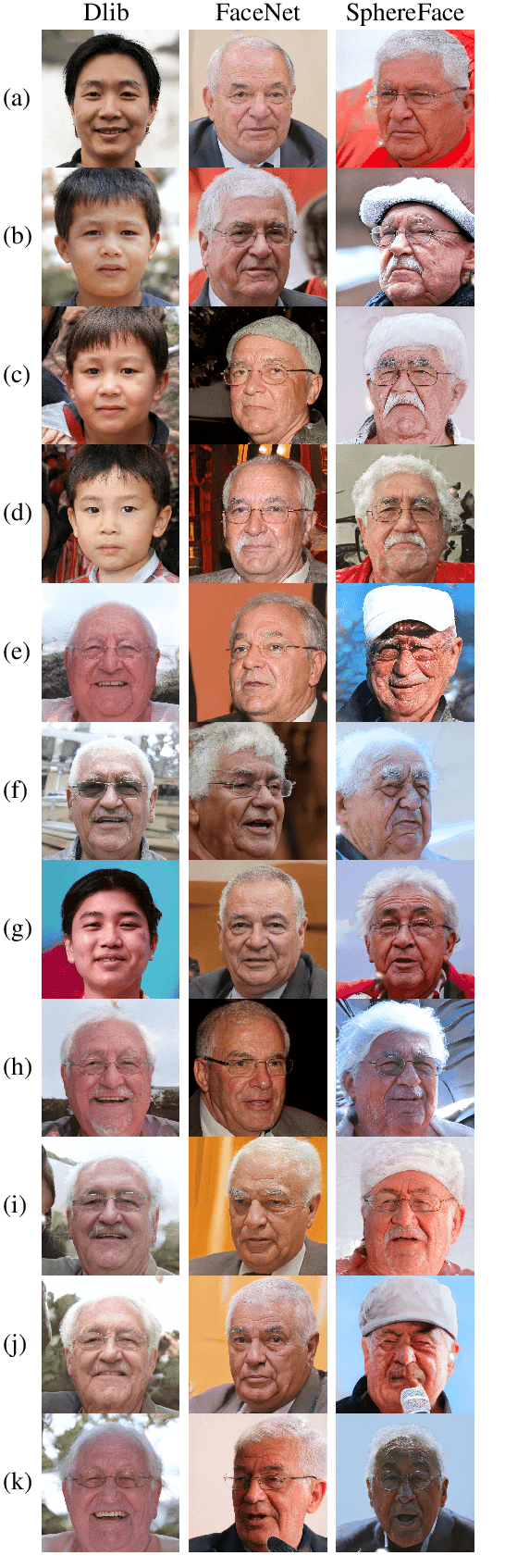
A master face is a face image that passes face-based identity-authentication for a large portion of the population. These faces can be used to impersonate, with a high probability of success, any user, without having access to any user-information. We optimize these faces, by using an evolutionary algorithm in the latent embedding space of the StyleGAN face generator. Multiple evolutionary strategies are compared, and we propose a novel approach that employs a neural network in order to direct the search in the direction of promising samples, without adding fitness evaluations. The results we present demonstrate that it is possible to obtain a high coverage of the LFW identities (over 40%) with less than 10 master faces, for three leading deep face recognition systems.