 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecureGaze: Defending Gaze Estimation Against Backdoor Attacks
Feb 27, 2025



Gaze estimation models are widely used in applications such as driver attention monitoring and human-computer interaction. While many methods for gaze estimation exist, they rely heavily on data-hungry deep learning to achieve high performance. This reliance often forces practitioners to harvest training data from unverified public datasets, outsource model training, or rely on pre-trained models. However, such practices expose gaze estimation models to backdoor attacks. In such attacks, adversaries inject backdoor triggers by poisoning the training data, creating a backdoor vulnerability: the model performs normally with benign inputs, but produces manipulated gaze directions when a specific trigger is present. This compromises the security of many gaze-based applications, such as causing the model to fail in tracking the driver's attention. To date, there is no defense that addresses backdoor attacks on gaze estimation models. In response, we introduce SecureGaze, the first solution designed to protect gaze estimation models from such attacks. Unlike classification models, defending gaze estimation poses unique challenges due to its continuous output space and globally activated backdoor behavior. By identifying distinctive characteristics of backdoored gaze estimation models, we develop a novel and effective approach to reverse-engineer the trigger function for reliable backdoor detection. Extensive evaluations in both digital and physical worlds demonstrate that SecureGaze effectively counters a range of backdoor attacks and outperforms seven state-of-the-art defenses adapted from classification models.
Defending Deep Regression Models against Backdoor Attacks
Nov 07, 2024



Deep regression models are used in a wide variety of safety-critical applications, but are vulnerable to backdoor attacks. Although many defenses have been proposed for classification models, they are ineffective as they do not consider the uniqueness of regression models. First, the outputs of regression models are continuous values instead of discretized labels. Thus, the potential infected target of a backdoored regression model has infinite possibilities, which makes it impossible to be determined by existing defenses. Second, the backdoor behavior of backdoored deep regression models is triggered by the activation values of all the neurons in the feature space, which makes it difficult to be detected and mitigated using existing defenses. To resolve these problems, we propose DRMGuard, the first defense to identify if a deep regression model in the image domain is backdoored or not. DRMGuard formulates the optimization problem for reverse engineering based on the unique output-space and feature-space characteristics of backdoored deep regression models. We conduct extensive evaluations on two regression tasks and four datasets. The results show that DRMGuard can consistently defend against various backdoor attacks. We also generalize four state-of-the-art defenses designed for classifiers to regression models, and compare DRMGuard with them. The results show that DRMGuard significantly outperforms all those defenses.
PrivateGaze: Preserving User Privacy in Black-box Mobile Gaze Tracking Services
Aug 01, 2024



Eye gaze contains rich information about human attention and cognitive processes. This capability makes the underlying technology, known as gaze tracking, a critical enabler for many ubiquitous applications and has triggered the development of easy-to-use gaze estimation services. Indeed, by utilizing the ubiquitous cameras on tablets and smartphones, users can readily access many gaze estimation services. In using these services, users must provide their full-face images to the gaze estimator, which is often a black box. This poses significant privacy threats to the users, especially when a malicious service provider gathers a large collection of face images to classify sensitive user attributes. In this work, we present PrivateGaze, the first approach that can effectively preserve users' privacy in black-box gaze tracking services without compromising gaze estimation performance. Specifically, we proposed a novel framework to train a privacy preserver that converts full-face images into obfuscated counterparts, which are effective for gaze estimation while containing no privacy information. Evaluation on four datasets shows that the obfuscated image can protect users' private information, such as identity and gender, against unauthorized attribute classification. Meanwhile, when used directly by the black-box gaze estimator as inputs, the obfuscated images lead to comparable tracking performance to the conventional, unprotected full-face images.
Unsupervised Gaze-aware Contrastive Learning with Subject-specific Condition
Sep 08, 2023



Appearance-based gaze estimation has shown great promise in many applications by using a single general-purpose camera as the input device. However, its success is highly depending on the availability of large-scale well-annotated gaze datasets, which are sparse and expensive to collect. To alleviate this challenge we propose ConGaze, a contrastive learning-based framework that leverages unlabeled facial images to learn generic gaze-aware representations across subjects in an unsupervised way. Specifically, we introduce the gaze-specific data augmentation to preserve the gaze-semantic features and maintain the gaze consistency, which are proven to be crucial for effective contrastive gaze representation learning. Moreover, we devise a novel subject-conditional projection module that encourages a share feature extractor to learn gaze-aware and generic representations. Our experiments on three public gaze estimation datasets show that ConGaze outperforms existing unsupervised learning solutions by 6.7% to 22.5%; and achieves 15.1% to 24.6% improvement over its supervised learning-based counterpart in cross-dataset evaluations.
FreeGaze: Resource-efficient Gaze Estimation via Frequency Domain Contrastive Learning
Sep 14, 2022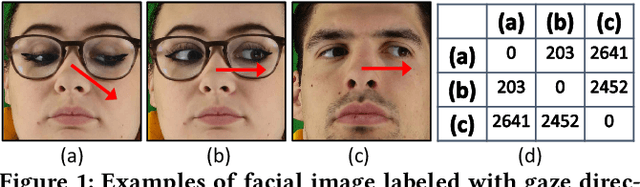
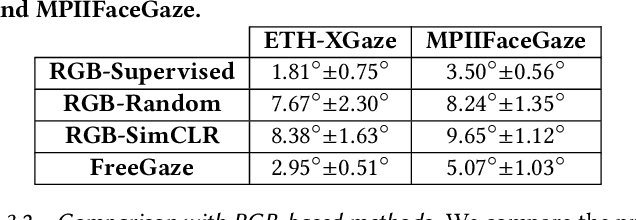
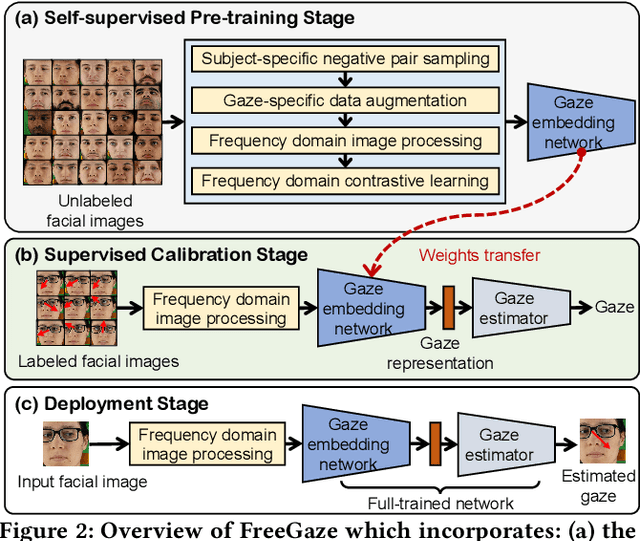
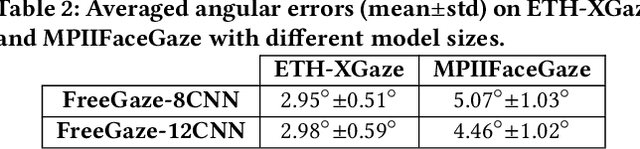
Gaze estimation is of great importance to many scientific fields and daily applications, ranging from fundamental research in cognitive psychology to attention-aware mobile systems. While recent advancements in deep learning have yielded remarkable successes in building highly accurate gaze estimation systems, the associated high computational cost and the reliance on large-scale labeled gaze data for supervised learning place challenges on the practical use of existing solutions. To move beyond these limitations, we present FreeGaze, a resource-efficient framework for unsupervised gaze representation learning. FreeGaze incorporates the frequency domain gaze estimation and the contrastive gaze representation learning in its design. The former significantly alleviates the computational burden in both system calibration and gaze estimation, and dramatically reduces the system latency; while the latter overcomes the data labeling hurdle of existing supervised learning-based counterparts, and ensures efficient gaze representation learning in the absence of gaze label. Our evaluation on two gaze estimation datasets shows that FreeGaze can achieve comparable gaze estimation accuracy with existing supervised learning-based approach, while enabling up to 6.81 and 1.67 times speedup in system calibration and gaze estimation, respectively.