 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Test-Time Scaling for Zero-Shot Respiratory Audio Classification
Apr 14, 2026Automated respiratory audio analysis promises scalable, non-invasive disease screening, yet progress is limited by scarce labeled data and costly expert annotation. Zero-shot inference eliminates task-specific supervision, but existing methods apply uniform computation to every input regardless of difficulty. We introduce TRIAGE, a tiered zero-shot framework that adaptively scales test-time compute by routing each audio sample through progressively richer reasoning stages: fast label-cosine scoring in a joint audio-text embedding space (Tier-L), structured matching with clinician-style descriptors (Tier-M), and retrieval-augmented large language model reasoning (Tier-H). A confidence-based router finalizes easy predictions early while allocating additional computation to ambiguous inputs, enabling nearly half of all samples to exit at the cheapest tier. Across nine respiratory classification tasks without task-specific training, TRIAGE achieves a mean AUROC of 0.744, outperforming prior zero-shot methods and matching or exceeding supervised baselines on multiple tasks. Our analysis show that test-time scaling concentrates gains where they matter: uncertain cases see up to 19% relative improvement while confident predictions remain unchanged at minimal cost.
CaReAQA: A Cardiac and Respiratory Audio Question Answering Model for Open-Ended Diagnostic Reasoning
May 02, 2025Medical audio signals, such as heart and lung sounds, play a crucial role in clinical diagnosis. However, analyzing these signals remains challenging: traditional methods rely on handcrafted features or supervised deep learning models that demand extensive labeled datasets, limiting their scalability and applicability. To address these issues, we propose CaReAQA, an audio-language model that integrates a foundation audio model with the reasoning capabilities of large language models, enabling clinically relevant, open-ended diagnostic responses. Alongside CaReAQA, we introduce CaReSound, a benchmark dataset of annotated medical audio recordings enriched with metadata and paired question-answer examples, intended to drive progress in diagnostic reasoning research. Evaluation results show that CaReAQA achieves 86.2% accuracy on open-ended diagnostic reasoning tasks, outperforming baseline models. It also generalizes well to closed-ended classification tasks, achieving an average accuracy of 56.9% on unseen datasets. Our findings show how audio-language integration and reasoning advances medical diagnostics, enabling efficient AI systems for clinical decision support.
Human-AI Co-Learning for Data-Driven AI
Oct 28, 2019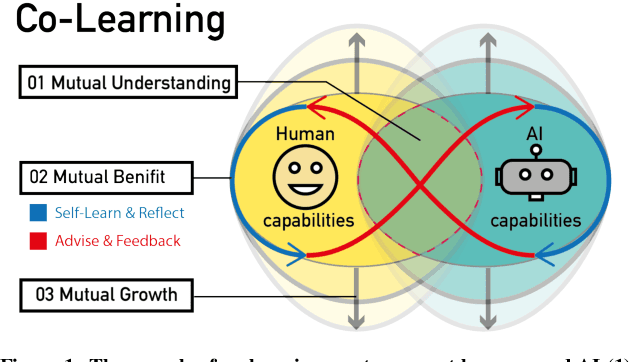
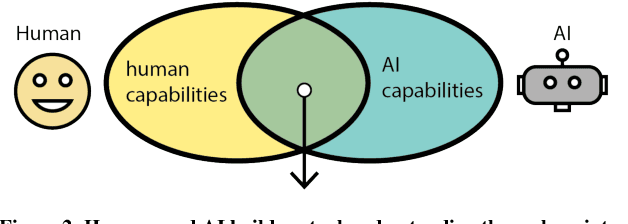
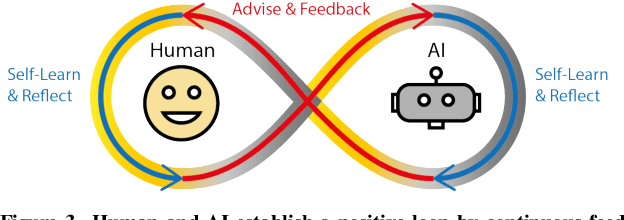
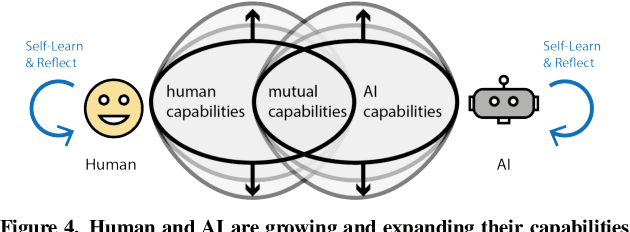
Human and AI are increasingly interacting and collaborating to accomplish various complex tasks in the context of diverse application domains (e.g., healthcare, transportation, and creative design). Two dynamic, learning entities (AI and human) have distinct mental model, expertise, and ability; such fundamental difference/mismatch offers opportunities for bringing new perspectives to achieve better results. However, this mismatch can cause unexpected failure and result in serious consequences. While recent research has paid much attention to enhancing interpretability or explainability to allow machine to explain how it makes a decision for supporting humans, this research argues that there is urging the need for both human and AI should develop specific, corresponding ability to interact and collaborate with each other to form a human-AI team to accomplish superior results. This research introduces a conceptual framework called "Co-Learning," in which people can learn with/from and grow with AI partners over time. We characterize three key concepts of co-learning: "mutual understanding," "mutual benefits," and "mutual growth" for facilitating human-AI collaboration on complex problem solving. We will present proof-of-concepts to investigate whether and how our approach can help human-AI team to understand and benefit each other, and ultimately improve productivity and creativity on creative problem domains. The insights will contribute to the design of Human-AI collaboration.