 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
Gradient-Based Meta-Learning Using Uncertainty to Weigh Loss for Few-Shot Learning
Aug 17, 2022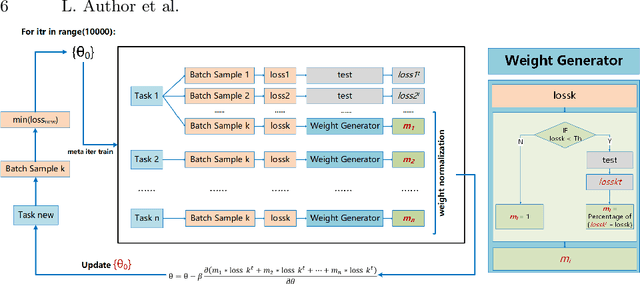
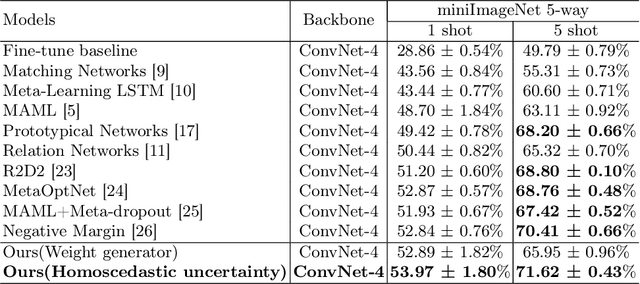
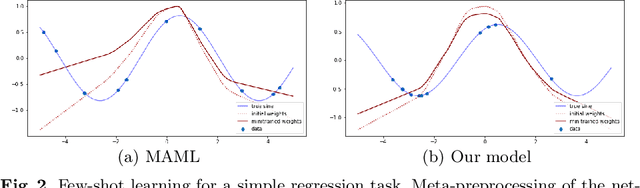
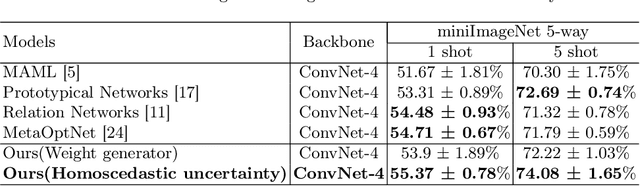
Model-Agnostic Meta-Learning (MAML) is one of the most successful meta-learning techniques for few-shot learning. It uses gradient descent to learn commonalities between various tasks, enabling the model to learn the meta-initialization of its own parameters to quickly adapt to new tasks using a small amount of labeled training data. A key challenge to few-shot learning is task uncertainty. Although a strong prior can be obtained from meta-learning with a large number of tasks, a precision model of the new task cannot be guaranteed because the volume of the training dataset is normally too small. In this study, first,in the process of choosing initialization parameters, the new method is proposed for task-specific learner adaptively learn to select initialization parameters that minimize the loss of new tasks. Then, we propose two improved methods for the meta-loss part: Method 1 generates weights by comparing meta-loss differences to improve the accuracy when there are few classes, and Method 2 introduces the homoscedastic uncertainty of each task to weigh multiple losses based on the original gradient descent,as a way to enhance the generalization ability to novel classes while ensuring accuracy improvement. Compared with previous gradient-based meta-learning methods, our model achieves better performance in regression tasks and few-shot classification and improves the robustness of the model to the learning rate and query sets in the meta-test set.