 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Discovery of Multimodal Links in Multi-Image, Multi-Sentence Documents
Apr 16, 2019
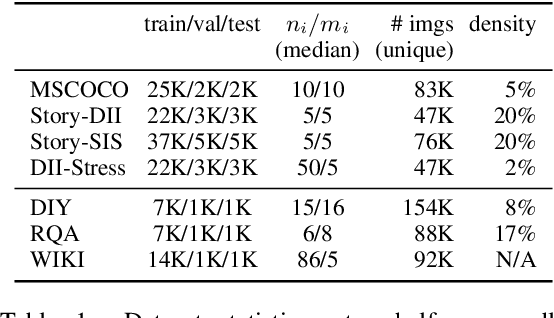

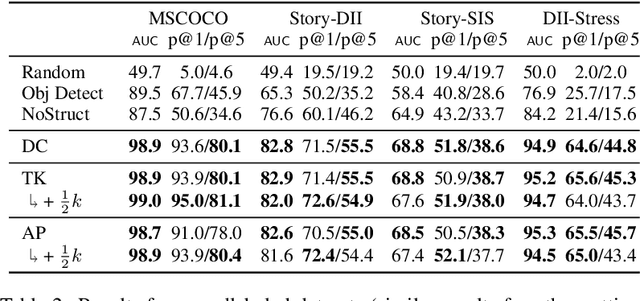
Images and text co-occur everywhere on the web, but explicit links between images and sentences (or other intra-document textual units) are often not annotated by users. We present algorithms that successfully discover image-sentence relationships without relying on any explicit multimodal annotation. We explore several variants of our approach on seven datasets of varying difficulty, ranging from images that were captioned post hoc by crowd-workers to naturally-occurring user-generated multimodal documents, wherein correspondences between illustrations and individual textual units may not be one-to-one. We find that a structured training objective based on identifying whether sets of images and sentences co-occur in documents can be sufficient to predict links between specific sentences and specific images within the same document at test time.
Something's Brewing! Early Prediction of Controversy-causing Posts from Discussion Features
Apr 15, 2019
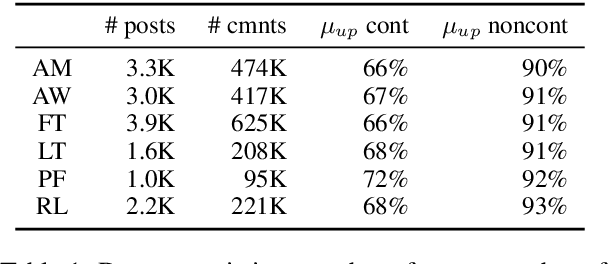
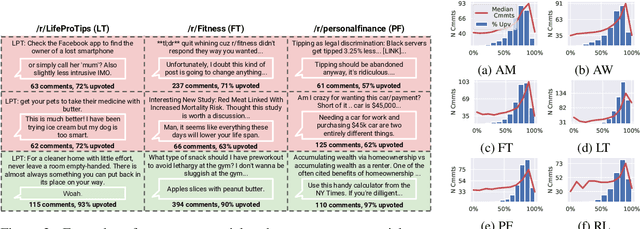
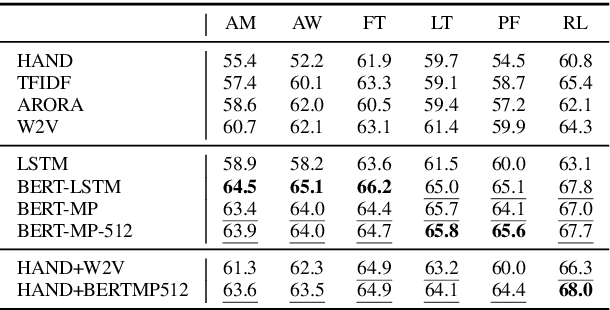
Controversial posts are those that split the preferences of a community, receiving both significant positive and significant negative feedback. Our inclusion of the word "community" here is deliberate: what is controversial to some audiences may not be so to others. Using data from several different communities on reddit.com, we predict the ultimate controversiality of posts, leveraging features drawn from both the textual content and the tree structure of the early comments that initiate the discussion. We find that even when only a handful of comments are available, e.g., the first 5 comments made within 15 minutes of the original post, discussion features often add predictive capacity to strong content-and-rate only baselines. Additional experiments on domain transfer suggest that conversation-structure features often generalize to other communities better than conversation-content features do.
Global Transition-based Non-projective Dependency Parsing
Jul 04, 2018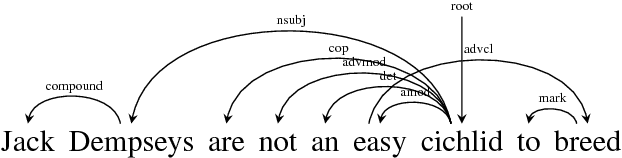

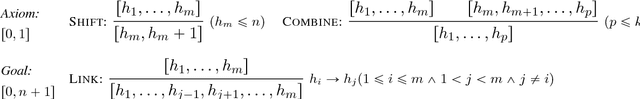

Shi, Huang, and Lee (2017) obtained state-of-the-art results for English and Chinese dependency parsing by combining dynamic-programming implementations of transition-based dependency parsers with a minimal set of bidirectional LSTM features. However, their results were limited to projective parsing. In this paper, we extend their approach to support non-projectivity by providing the first practical implementation of the MH_4 algorithm, an $O(n^4)$ mildly nonprojective dynamic-programming parser with very high coverage on non-projective treebanks. To make MH_4 compatible with minimal transition-based feature sets, we introduce a transition-based interpretation of it in which parser items are mapped to sequences of transitions. We thus obtain the first implementation of global decoding for non-projective transition-based parsing, and demonstrate empirically that it is more effective than its projective counterpart in parsing a number of highly non-projective languages
* Proceedings of ACL 2018. 13 pages
Quantifying the visual concreteness of words and topics in multimodal datasets
May 23, 2018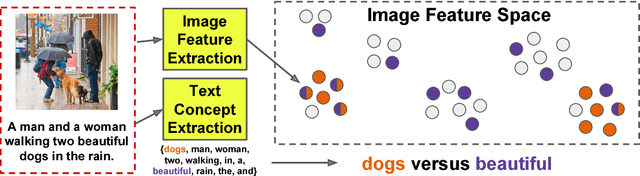
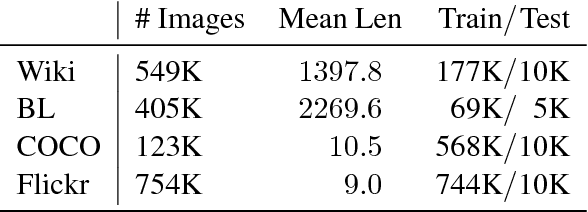

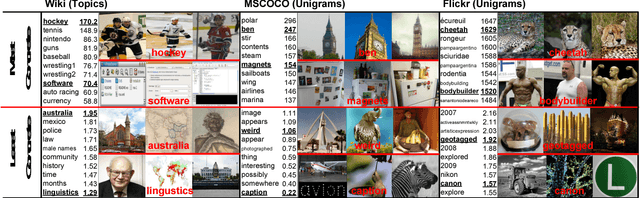
Multimodal machine learning algorithms aim to learn visual-textual correspondences. Previous work suggests that concepts with concrete visual manifestations may be easier to learn than concepts with abstract ones. We give an algorithm for automatically computing the visual concreteness of words and topics within multimodal datasets. We apply the approach in four settings, ranging from image captions to images/text scraped from historical books. In addition to enabling explorations of concepts in multimodal datasets, our concreteness scores predict the capacity of machine learning algorithms to learn textual/visual relationships. We find that 1) concrete concepts are indeed easier to learn; 2) the large number of algorithms we consider have similar failure cases; 3) the precise positive relationship between concreteness and performance varies between datasets. We conclude with recommendations for using concreteness scores to facilitate future multimodal research.
* NAACL HLT 2018, 14 pages, 6 figures, data available at http://www.cs.cornell.edu/~jhessel/concreteness/concreteness.html
Improving Coverage and Runtime Complexity for Exact Inference in Non-Projective Transition-Based Dependency Parsers
May 02, 2018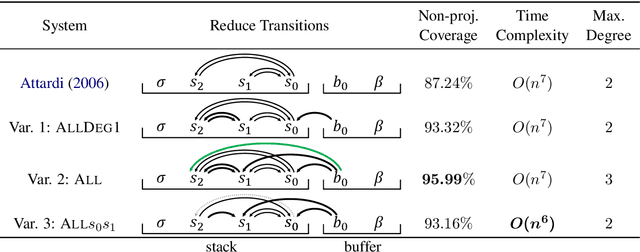
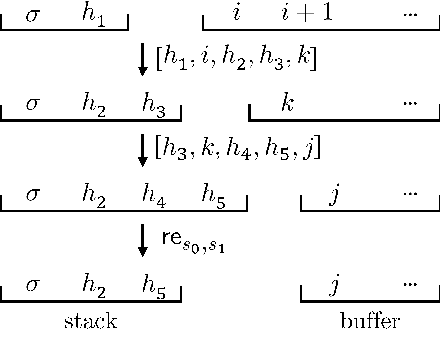
We generalize Cohen, G\'omez-Rodr\'iguez, and Satta's (2011) parser to a family of non-projective transition-based dependency parsers allowing polynomial-time exact inference. This includes novel parsers with better coverage than Cohen et al. (2011), and even a variant that reduces time complexity to $O(n^6)$, improving over the known bounds in exact inference for non-projective transition-based parsing. We hope that this piece of theoretical work inspires design of novel transition systems with better coverage and better run-time guarantees. Code available at https://github.com/tzshi/nonproj-dp-variants-naacl2018
* Proceedings of NAACL-HLT 2018. 6 pages. This version fixes display issue in an author name
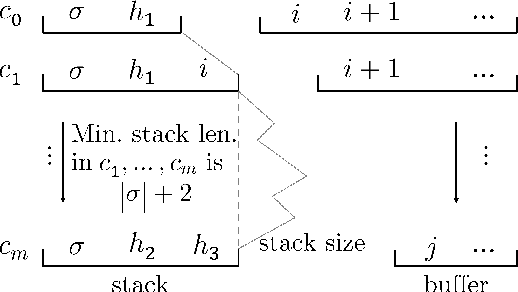
Fast Exact Decoding and Global Training for Transition-Based Dependency Parsing via a Minimal Feature Set
Aug 30, 2017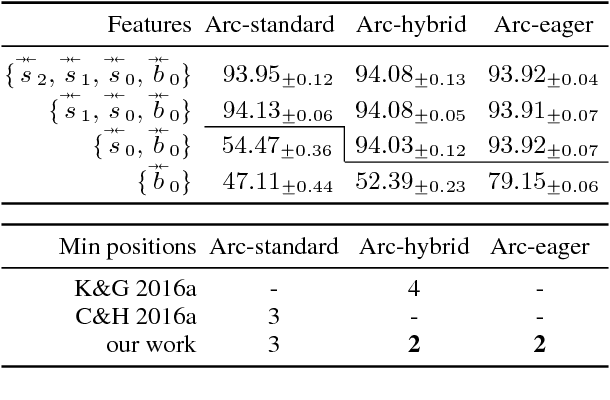
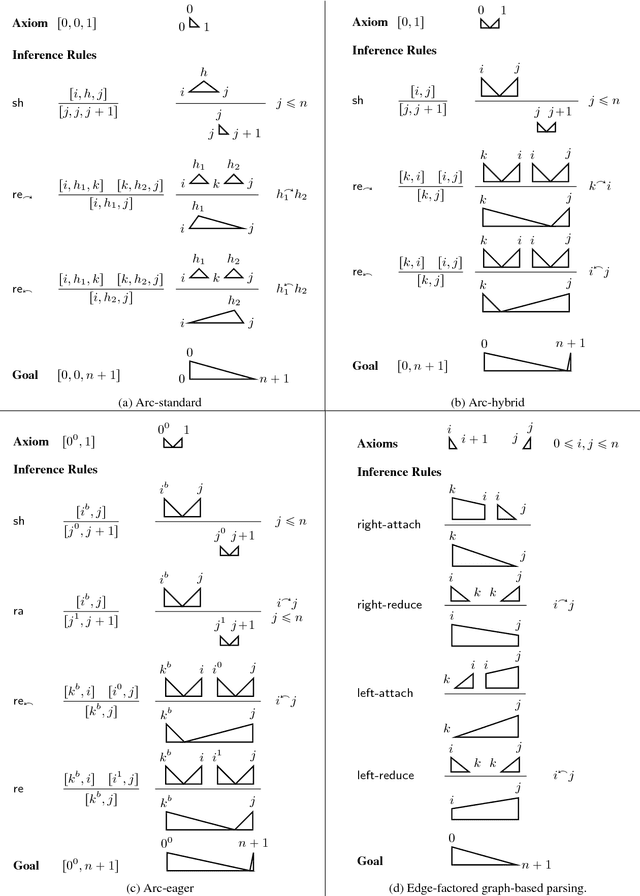
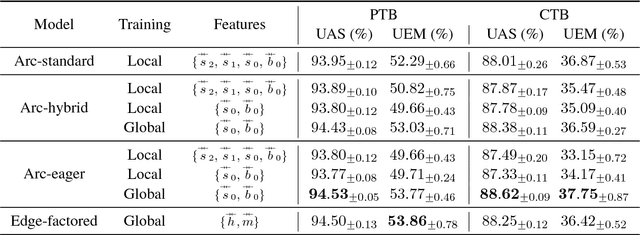
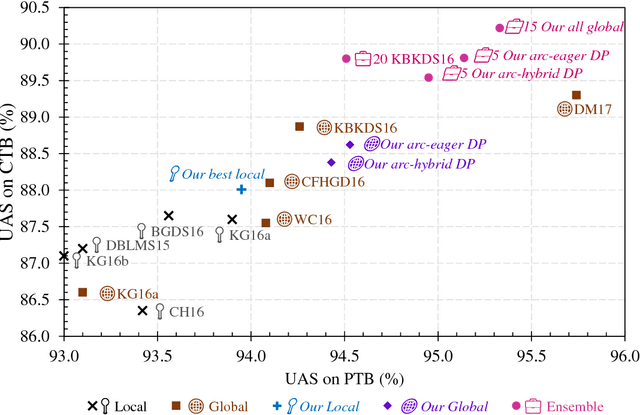
We first present a minimal feature set for transition-based dependency parsing, continuing a recent trend started by Kiperwasser and Goldberg (2016a) and Cross and Huang (2016a) of using bi-directional LSTM features. We plug our minimal feature set into the dynamic-programming framework of Huang and Sagae (2010) and Kuhlmann et al. (2011) to produce the first implementation of worst-case O(n^3) exact decoders for arc-hybrid and arc-eager transition systems. With our minimal features, we also present O(n^3) global training methods. Finally, using ensembles including our new parsers, we achieve the best unlabeled attachment score reported (to our knowledge) on the Chinese Treebank and the "second-best-in-class" result on the English Penn Treebank.
* Proceedings of EMNLP, 2017. 12 pages
Cats and Captions vs. Creators and the Clock: Comparing Multimodal Content to Context in Predicting Relative Popularity
Mar 06, 2017
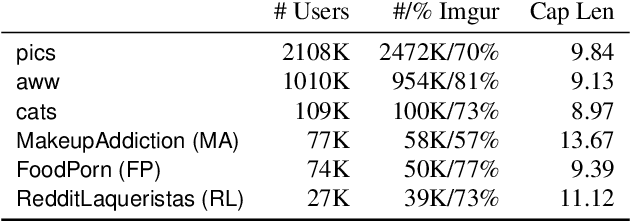
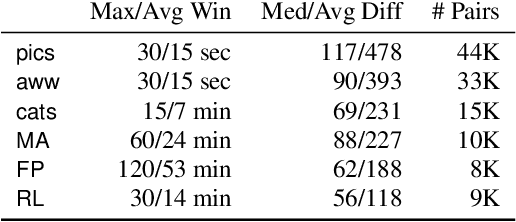
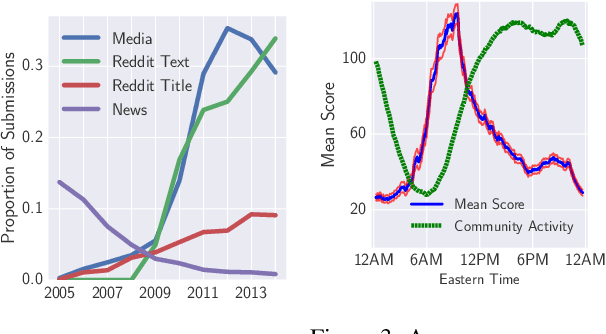
The content of today's social media is becoming more and more rich, increasingly mixing text, images, videos, and audio. It is an intriguing research question to model the interplay between these different modes in attracting user attention and engagement. But in order to pursue this study of multimodal content, we must also account for context: timing effects, community preferences, and social factors (e.g., which authors are already popular) also affect the amount of feedback and reaction that social-media posts receive. In this work, we separate out the influence of these non-content factors in several ways. First, we focus on ranking pairs of submissions posted to the same community in quick succession, e.g., within 30 seconds, this framing encourages models to focus on time-agnostic and community-specific content features. Within that setting, we determine the relative performance of author vs. content features. We find that victory usually belongs to "cats and captions," as visual and textual features together tend to outperform identity-based features. Moreover, our experiments show that when considered in isolation, simple unigram text features and deep neural network visual features yield the highest accuracy individually, and that the combination of the two modalities generally leads to the best accuracies overall.
When confidence and competence collide: Effects on online decision-making discussions
Mar 05, 2017
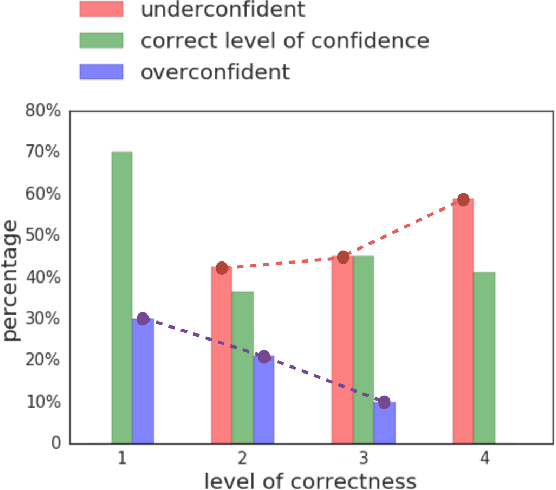

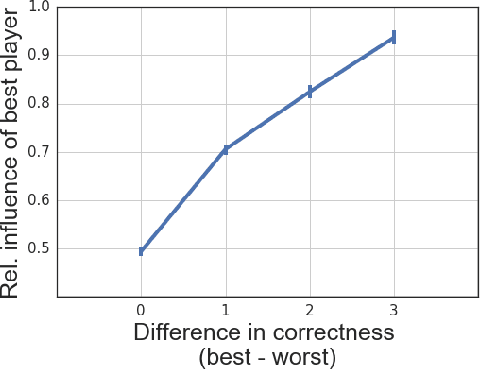
Group discussions are a way for individuals to exchange ideas and arguments in order to reach better decisions than they could on their own. One of the premises of productive discussions is that better solutions will prevail, and that the idea selection process is mediated by the (relative) competence of the individuals involved. However, since people may not know their actual competence on a new task, their behavior is influenced by their self-estimated competence --- that is, their confidence --- which can be misaligned with their actual competence. Our goal in this work is to understand the effects of confidence-competence misalignment on the dynamics and outcomes of discussions. To this end, we design a large-scale natural setting, in the form of an online team-based geography game, that allows us to disentangle confidence from competence and thus separate their effects. We find that in task-oriented discussions, the more-confident individuals have a larger impact on the group's decisions even when these individuals are at the same level of competence as their teammates. Furthermore, this unjustified role of confidence in the decision-making process often leads teams to under-perform. We explore this phenomenon by investigating the effects of confidence on conversational dynamics.
Talk it up or play it down? expected correlations between emphasis and recurrence of discussion points in consequential U.S. economic policy meetings
Dec 19, 2016

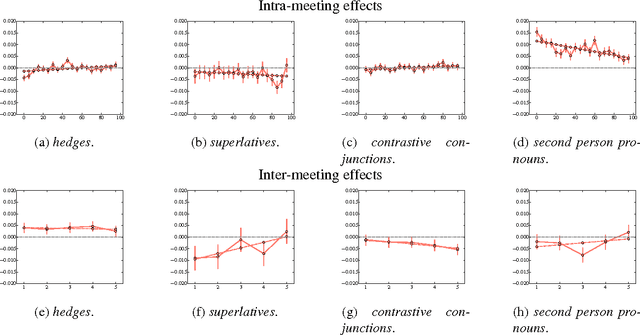
In meetings where important decisions get made, what items receive more attention may influence the outcome. We examine how different types of rhetorical (de-)emphasis -- including hedges, superlatives, and contrastive conjunctions -- correlate with what gets revisited later, controlling for item frequency and speaker. Our data consists of transcripts of recurring meetings of the Federal Reserve's Open Market Committee (FOMC), where important aspects of U.S. monetary policy are decided on. Surprisingly, we find that words appearing in the context of hedging, which is usually considered a way to express uncertainty, are more likely to be repeated in subsequent meetings, while strong emphasis indicated by superlatives has a slightly negative effect on word recurrence in subsequent meetings. We also observe interesting patterns in how these effects vary depending on social factors such as status and gender of the speaker. For instance, the positive effects of hedging are more pronounced for female speakers than for male speakers.
Tie-breaker: Using language models to quantify gender bias in sports journalism
Jul 13, 2016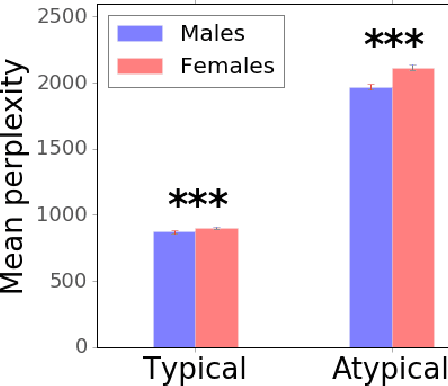
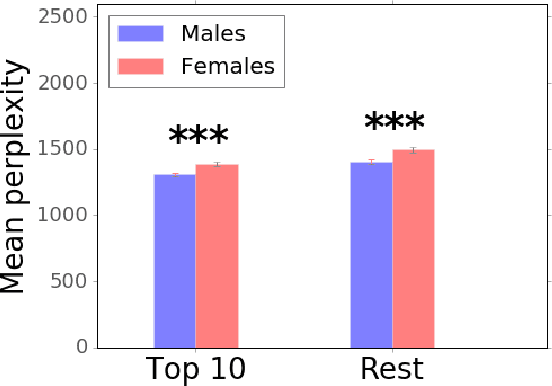
Gender bias is an increasingly important issue in sports journalism. In this work, we propose a language-model-based approach to quantify differences in questions posed to female vs. male athletes, and apply it to tennis post-match interviews. We find that journalists ask male players questions that are generally more focused on the game when compared with the questions they ask their female counterparts. We also provide a fine-grained analysis of the extent to which the salience of this bias depends on various factors, such as question type, game outcome or player rank.