 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Inference Performance of Deep Learning Models on Analog Devices
Dec 16, 2020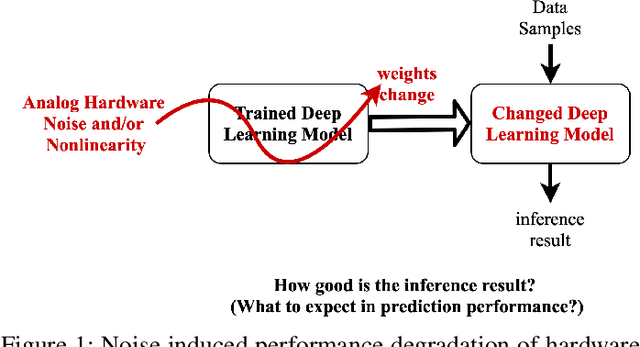
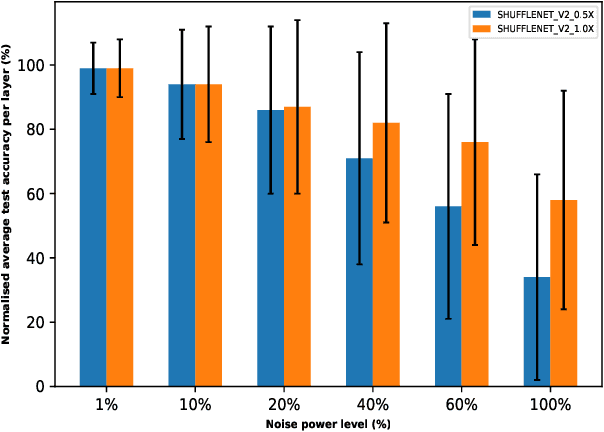
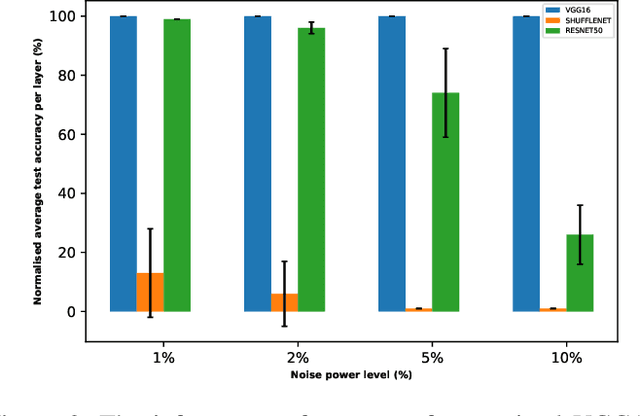
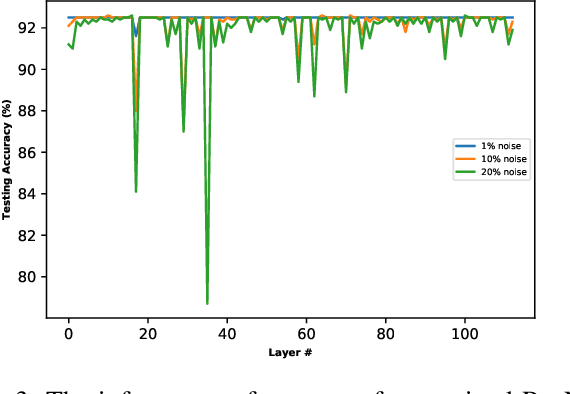
Analog hardware implemented deep learning models are promising for computation and energy constrained systems such as edge computing devices. However, the analog nature of the device and the associated many noise sources will cause changes to the value of the weights in the trained deep learning models deployed on such devices. In this study, systematic evaluation of the inference performance of trained popular deep learning models for image classification deployed on analog devices has been carried out, where additive white Gaussian noise has been added to the weights of the trained models during inference. It is observed that deeper models and models with more redundancy in design such as VGG are more robust to the noise in general. However, the performance is also affected by the design philosophy of the model, the detailed structure of the model, the exact machine learning task, as well as the datasets.
Offloading Optimization in Edge Computing for Deep Learning Enabled Target Tracking by Internet-of-UAVs
Aug 18, 2020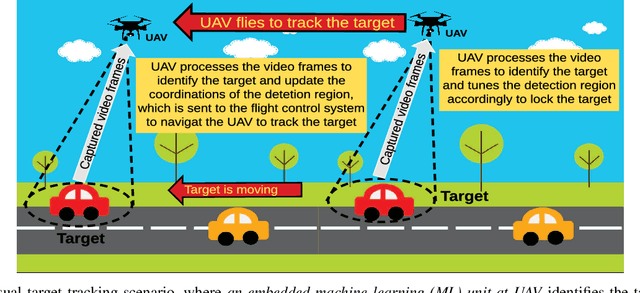
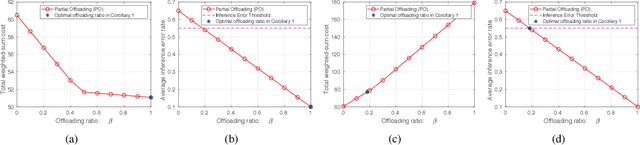
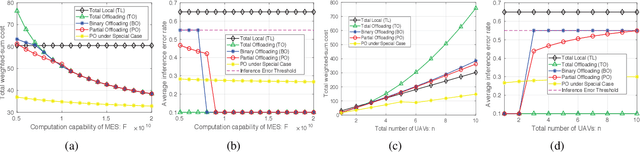
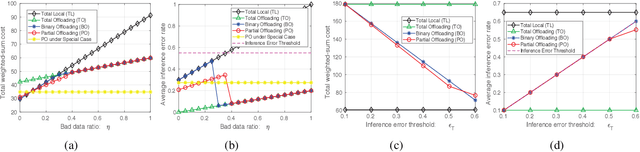
The empowering unmanned aerial vehicles (UAVs) have been extensively used in providing intelligence such as target tracking. In our field experiments, a pre-trained convolutional neural network (CNN) is deployed at the UAV to identify a target (a vehicle) from the captured video frames and enable the UAV to keep tracking. However, this kind of visual target tracking demands a lot of computational resources due to the desired high inference accuracy and stringent delay requirement. This motivates us to consider offloading this type of deep learning (DL) tasks to a mobile edge computing (MEC) server due to limited computational resource and energy budget of the UAV, and further improve the inference accuracy. Specifically, we propose a novel hierarchical DL tasks distribution framework, where the UAV is embedded with lower layers of the pre-trained CNN model, while the MEC server with rich computing resources will handle the higher layers of the CNN model. An optimization problem is formulated to minimize the weighted-sum cost including the tracking delay and energy consumption introduced by communication and computing of the UAVs, while taking into account the quality of data (e.g., video frames) input to the DL model and the inference errors. Analytical results are obtained and insights are provided to understand the tradeoff between the weighted-sum cost and inference error rate in the proposed framework. Numerical results demonstrate the effectiveness of the proposed offloading framework.
Computation Offloading in Multi-Access Edge Computing Networks: A Multi-Task Learning Approach
Jun 29, 2020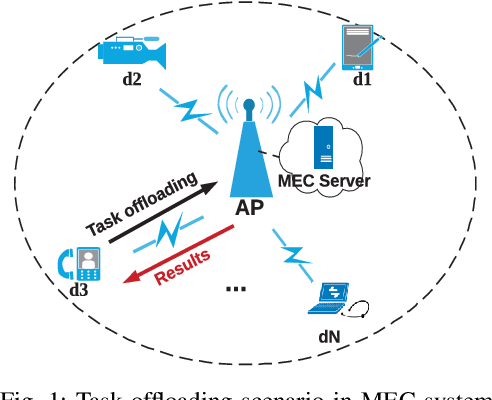
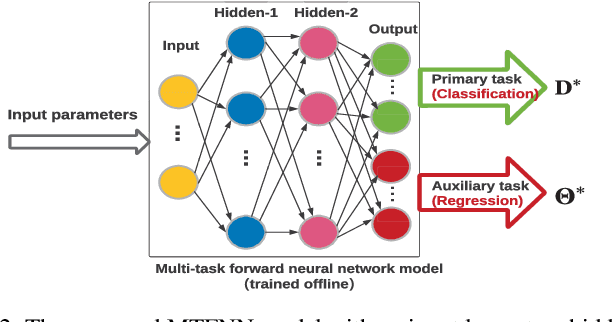
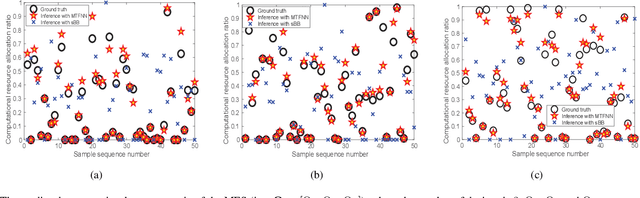
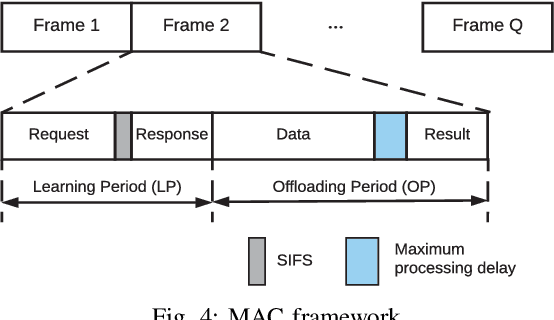
Multi-access edge computing (MEC) has already shown the potential in enabling mobile devices to bear the computation-intensive applications by offloading some tasks to a nearby access point (AP) integrated with a MEC server (MES). However, due to the varying network conditions and limited computation resources of the MES, the offloading decisions taken by a mobile device and the computational resources allocated by the MES may not be efficiently achieved with the lowest cost. In this paper, we propose a dynamic offloading framework for the MEC network, in which the uplink non-orthogonal multiple access (NOMA) is used to enable multiple devices to upload their tasks via the same frequency band. We formulate the offloading decision problem as a multiclass classification problem and formulate the MES computational resource allocation problem as a regression problem. Then a multi-task learning based feedforward neural network (MTFNN) model is designed to jointly optimize the offloading decision and computational resource allocation. Numerical results illustrate that the proposed MTFNN outperforms the conventional optimization method in terms of inference accuracy and computation complexity.
Lessons Learned from Accident of Autonomous Vehicle Testing: An Edge Learning-aided Offloading Framework
Jun 27, 2020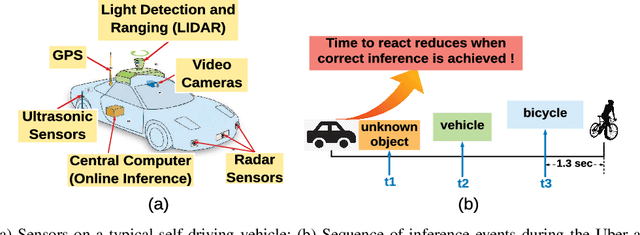
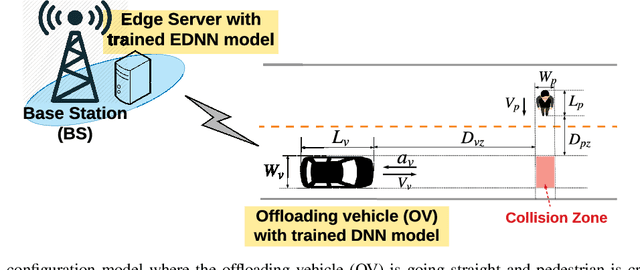
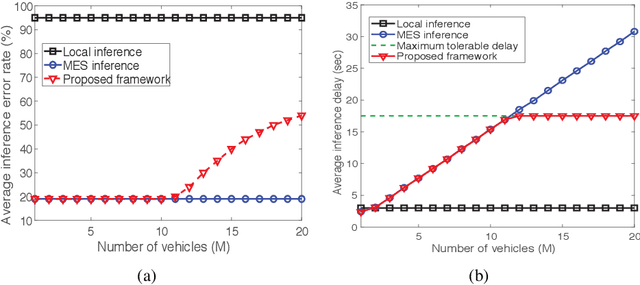
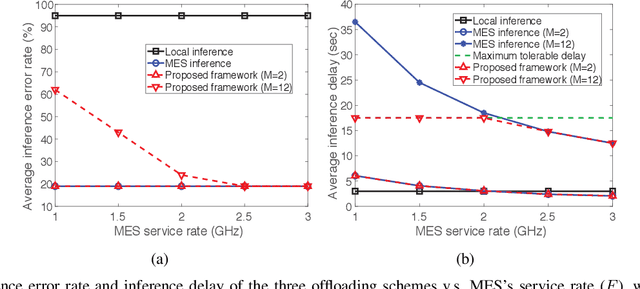
This letter proposes an edge learning-based offloading framework for autonomous driving, where the deep learning tasks can be offloaded to the edge server to improve the inference accuracy while meeting the latency constraint. Since the delay and the inference accuracy are incurred by wireless communications and computing, an optimization problem is formulated to maximize the inference accuracy subject to the offloading probability, the pre-braking probability, and data quality. Simulations demonstrate the superiority of the proposed offloading framework.
Efficient Privacy Preserving Edge Computing Framework for Image Classification
May 10, 2020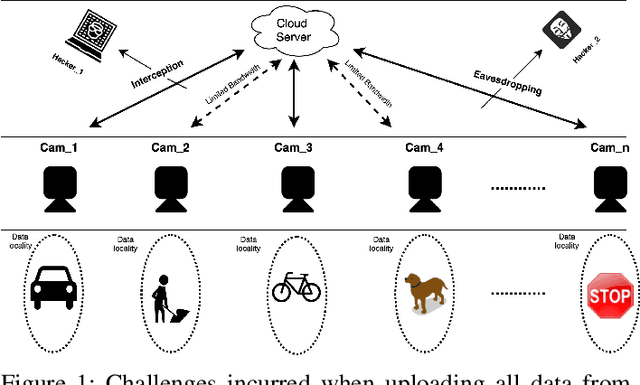
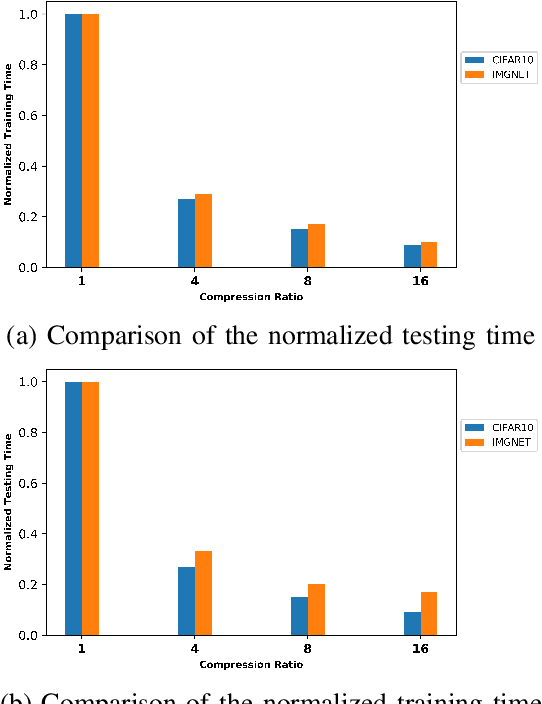
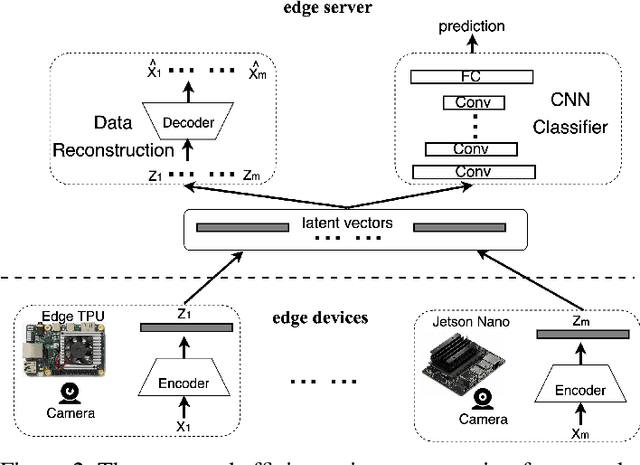
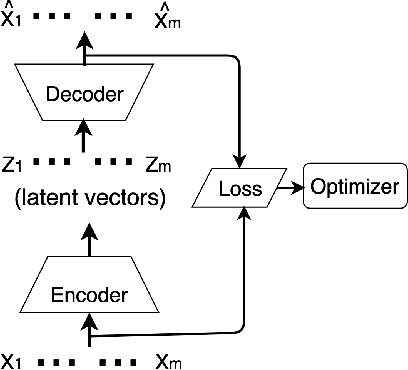
In order to extract knowledge from the large data collected by edge devices, traditional cloud based approach that requires data upload may not be feasible due to communication bandwidth limitation as well as privacy and security concerns of end users. To address these challenges, a novel privacy preserving edge computing framework is proposed in this paper for image classification. Specifically, autoencoder will be trained unsupervised at each edge device individually, then the obtained latent vectors will be transmitted to the edge server for the training of a classifier. This framework would reduce the communications overhead and protect the data of the end users. Comparing to federated learning, the training of the classifier in the proposed framework does not subject to the constraints of the edge devices, and the autoencoder can be trained independently at each edge device without any server involvement. Furthermore, the privacy of the end users' data is protected by transmitting latent vectors without additional cost of encryption. Experimental results provide insights on the image classification performance vs. various design parameters such as the data compression ratio of the autoencoder and the model complexity.
Cell Type Identification from Single-Cell Transcriptomic Data via Semi-supervised Learning
May 06, 2020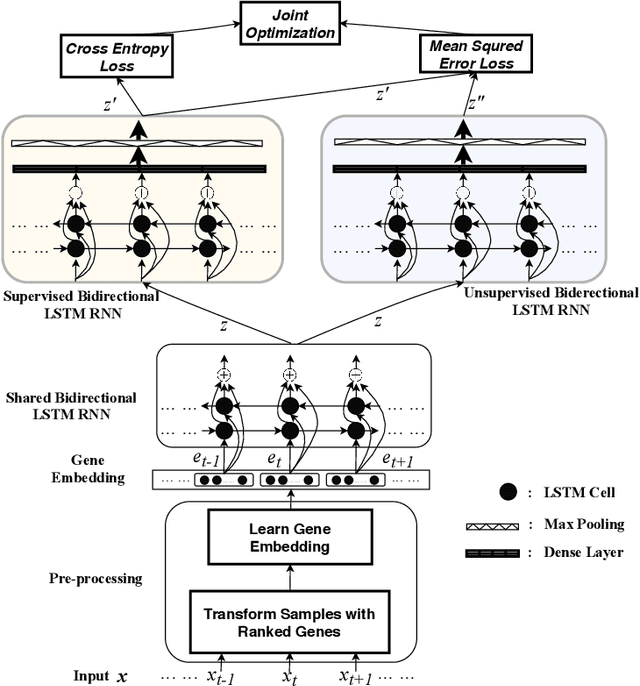

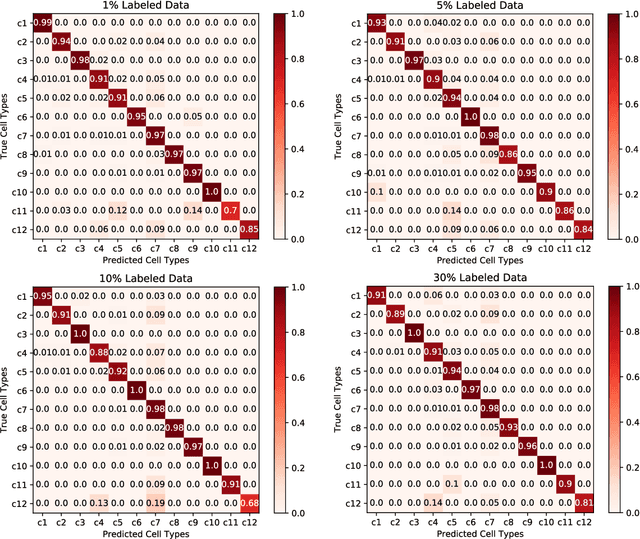

Cell type identification from single-cell transcriptomic data is a common goal of single-cell RNA sequencing (scRNAseq) data analysis. Neural networks have been employed to identify cell types from scRNAseq data with high performance. However, it requires a large mount of individual cells with accurate and unbiased annotated types to build the identification models. Unfortunately, labeling the scRNAseq data is cumbersome and time-consuming as it involves manual inspection of marker genes. To overcome this challenge, we propose a semi-supervised learning model to use unlabeled scRNAseq cells and limited amount of labeled scRNAseq cells to implement cell identification. Firstly, we transform the scRNAseq cells to "gene sentences", which is inspired by similarities between natural language system and gene system. Then genes in these sentences are represented as gene embeddings to reduce data sparsity. With these embeddings, we implement a semi-supervised learning model based on recurrent convolutional neural networks (RCNN), which includes a shared network, a supervised network and an unsupervised network. The proposed model is evaluated on macosko2015, a large scale single-cell transcriptomic dataset with ground truth of individual cell types. It is observed that the proposed model is able to achieve encouraging performance by learning on very limited amount of labeled scRNAseq cells together with a large number of unlabeled scRNAseq cells.
Ensemble Deep Learning on Time-Series Representation of Tweets for Rumor Detection in Social Media
Apr 26, 2020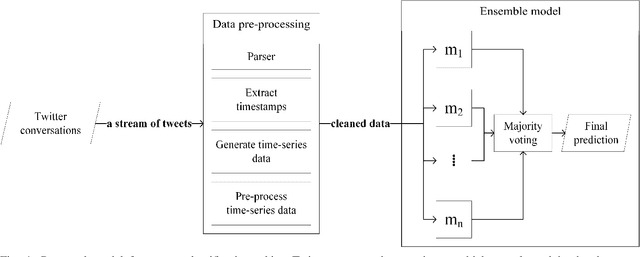
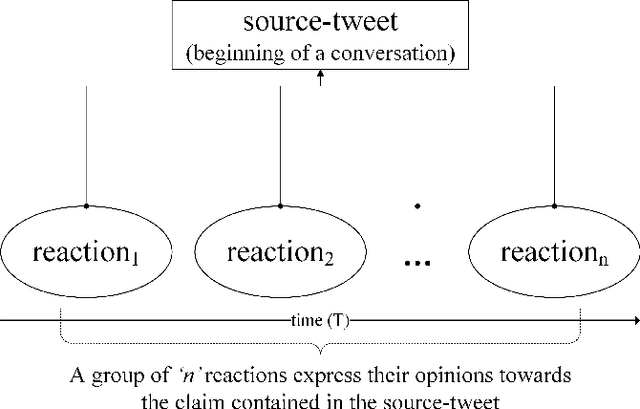


Social media is a popular platform for timely information sharing. One of the important challenges for social media platforms like Twitter is whether to trust news shared on them when there is no systematic news verification process. On the other hand, timely detection of rumors is a non-trivial task, given the fast-paced social media environment. In this work, we proposed an ensemble model, which performs majority-voting on a collection of predictions by deep neural networks using time-series vector representation of Twitter data for timely detection of rumors. By combining the proposed data pre-processing method with the ensemble model, better performance of rumor detection has been demonstrated in the experiments using PHEME dataset. Experimental results show that the classification performance has been improved by 7.9% in terms of micro F1 score compared to the baselines.
Device Authentication Codes based on RF Fingerprinting using Deep Learning
Apr 19, 2020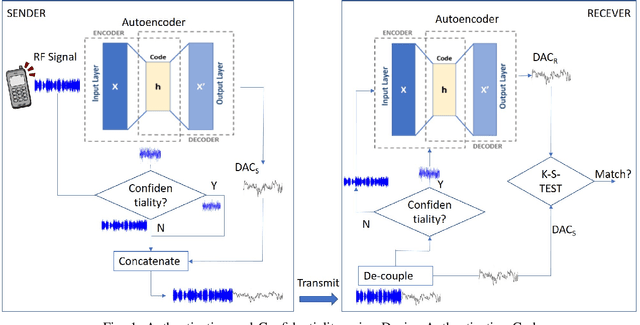
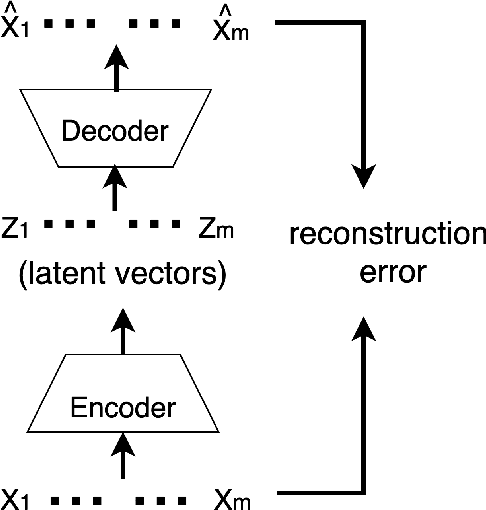
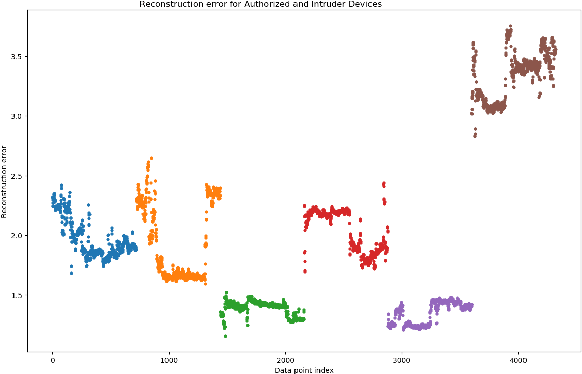
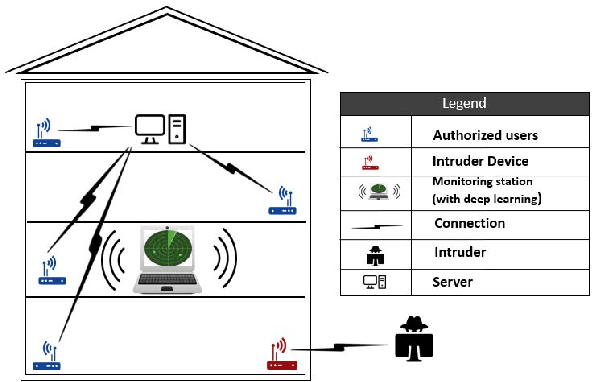
In this paper, we propose Device Authentication Code (DAC), a novel method for authenticating IoT devices with wireless interface by exploiting their radio frequency (RF) signatures. The proposed DAC is based on RF fingerprinting, information theoretic method, feature learning, and discriminatory power of deep learning. Specifically, an autoencoder is used to automatically extract features from the RF traces, and the reconstruction error is used as the DAC and this DAC is unique to the device and the particular message of interest. Then Kolmogorov-Smirnov (K-S) test is used to match the distribution of the reconstruction error generated by the autoencoder and the received message, and the result will determine whether the device of interest belongs to an authorized user. We validate this concept on two experimentally collected RF traces from six ZigBee and five universal software defined radio peripheral (USRP) devices, respectively. The traces span a range of Signalto- Noise Ratio by varying locations and mobility of the devices and channel interference and noise to ensure robustness of the model. Experimental results demonstrate that DAC is able to prevent device impersonation by extracting salient features that are unique to any wireless device of interest and can be used to identify RF devices. Furthermore, the proposed method does not need the RF traces of the intruder during model training yet be able to identify devices not seen during training, which makes it practical.
Two-path Deep Semi-supervised Learning for Timely Fake News Detection
Jan 31, 2020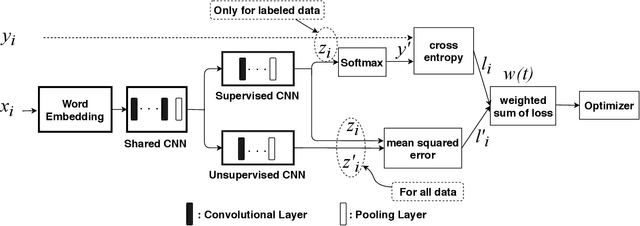
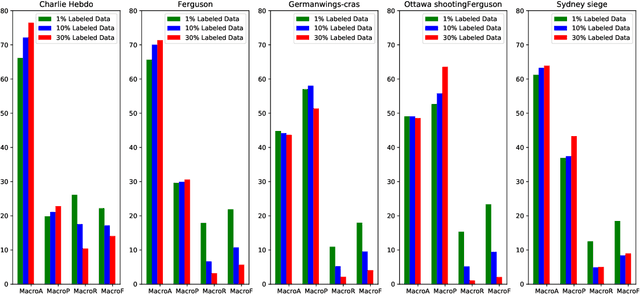
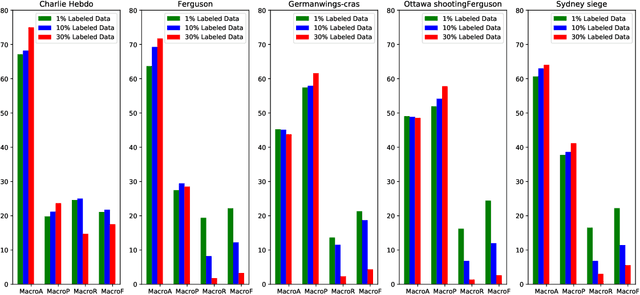
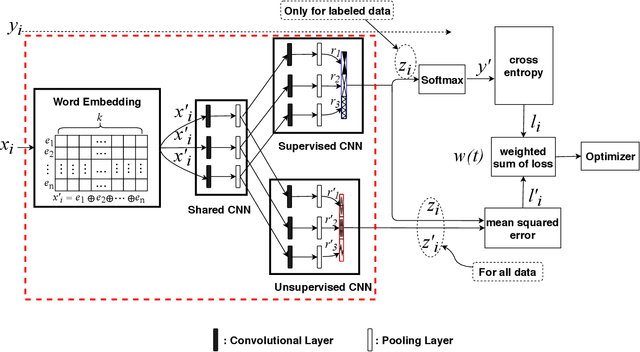
News in social media such as Twitter has been generated in high volume and speed. However, very few of them are labeled (as fake or true news) by professionals in near real time. In order to achieve timely detection of fake news in social media, a novel framework of two-path deep semi-supervised learning is proposed where one path is for supervised learning and the other is for unsupervised learning. The supervised learning path learns on the limited amount of labeled data while the unsupervised learning path is able to learn on a huge amount of unlabeled data. Furthermore, these two paths implemented with convolutional neural networks (CNN) are jointly optimized to complete semi-supervised learning. In addition, we build a shared CNN to extract the low level features on both labeled data and unlabeled data to feed them into these two paths. To verify this framework, we implement a Word CNN based semi-supervised learning model and test it on two datasets, namely, LIAR and PHEME. Experimental results demonstrate that the model built on the proposed framework can recognize fake news effectively with very few labeled data.
Deep Two-path Semi-supervised Learning for Fake News Detection
Jun 10, 2019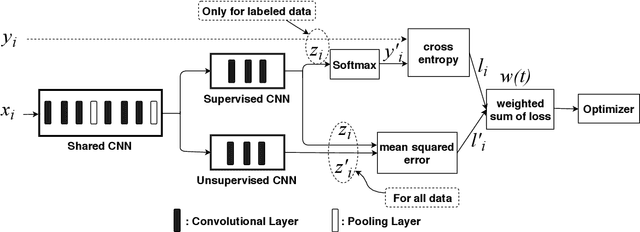
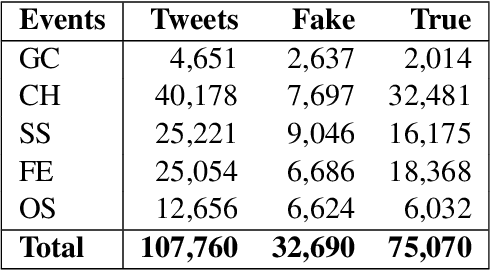
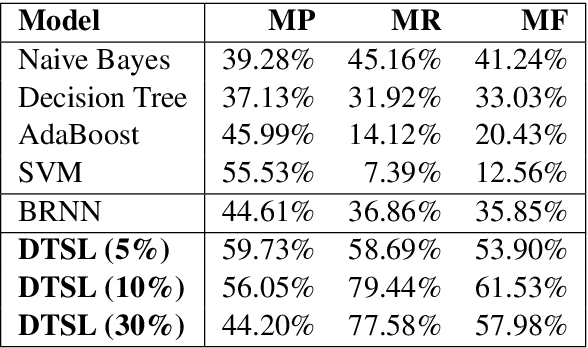
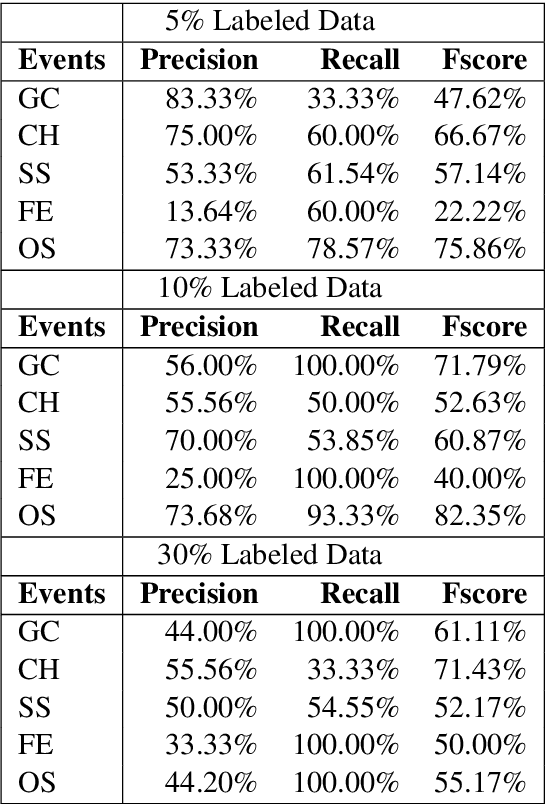
News in social media such as Twitter has been generated in high volume and speed. However, very few of them can be labeled (as fake or true news) in a short time. In order to achieve timely detection of fake news in social media, a novel deep two-path semi-supervised learning model is proposed, where one path is for supervised learning and the other is for unsupervised learning. These two paths implemented with convolutional neural networks are jointly optimized to enhance detection performance. In addition, we build a shared convolutional neural networks between these two paths to share the low level features. Experimental results using Twitter datasets show that the proposed model can recognize fake news effectively with very few labeled data.