 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Convergence of Projected Alternating Maximization for Equitable and Optimal Transport
Oct 01, 2021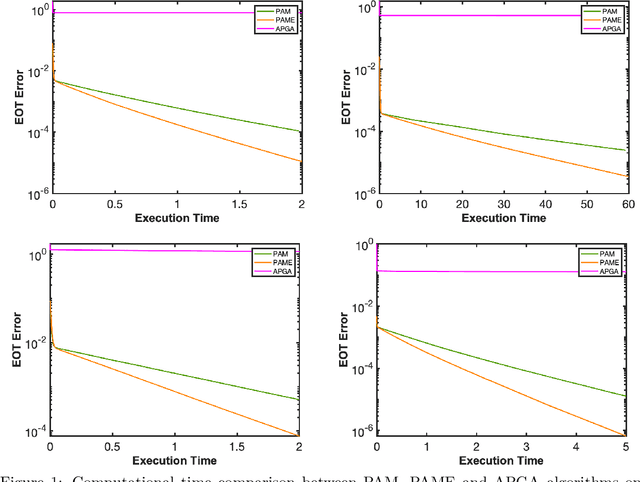
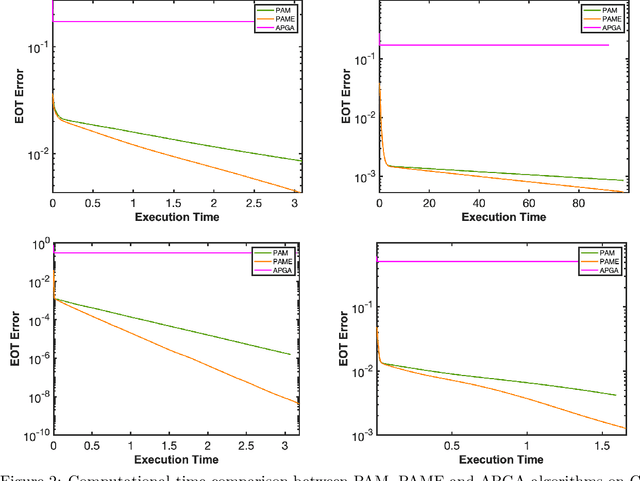
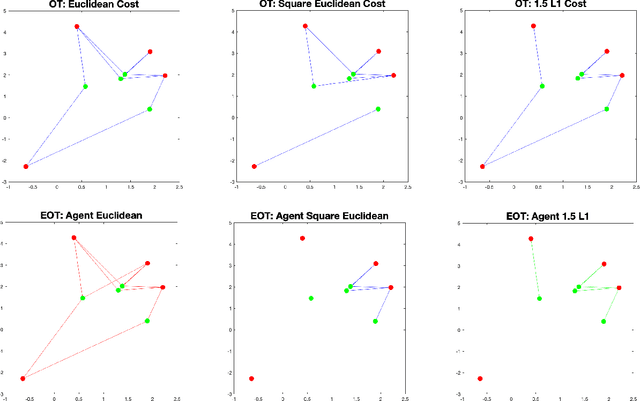
This paper studies the equitable and optimal transport (EOT) problem, which has many applications such as fair division problems and optimal transport with multiple agents etc. In the discrete distributions case, the EOT problem can be formulated as a linear program (LP). Since this LP is prohibitively large for general LP solvers, Scetbon \etal \cite{scetbon2021equitable} suggests to perturb the problem by adding an entropy regularization. They proposed a projected alternating maximization algorithm (PAM) to solve the dual of the entropy regularized EOT. In this paper, we provide the first convergence analysis of PAM. A novel rounding procedure is proposed to help construct the primal solution for the original EOT problem. We also propose a variant of PAM by incorporating the extrapolation technique that can numerically improve the performance of PAM. Results in this paper may shed lights on block coordinate (gradient) descent methods for general optimization problems.
Optimal Stochastic Nonconvex Optimization with Bandit Feedback
Mar 30, 2021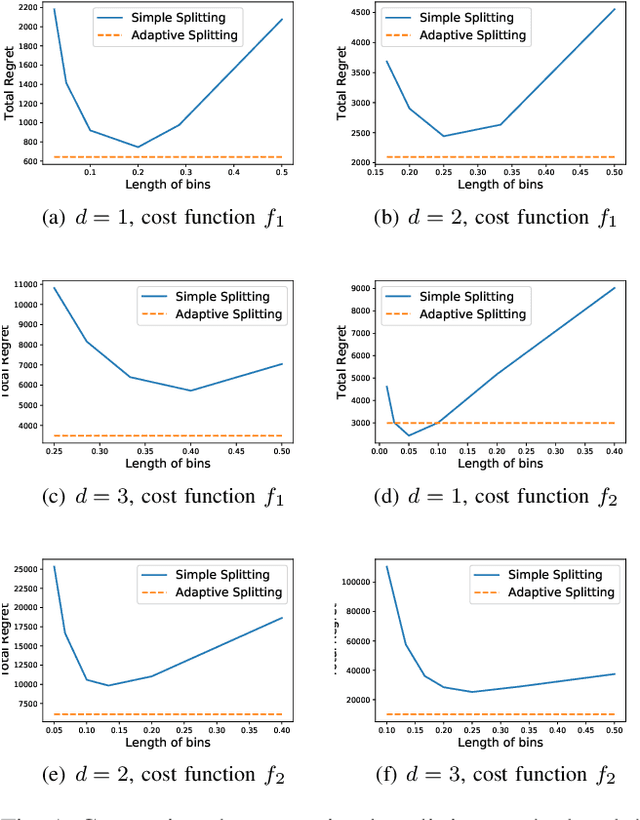
In this paper, we analyze the continuous armed bandit problems for nonconvex cost functions under certain smoothness and sublevel set assumptions. We first derive an upper bound on the expected cumulative regret of a simple bin splitting method. We then propose an adaptive bin splitting method, which can significantly improve the performance. Furthermore, a minimax lower bound is derived, which shows that our new adaptive method achieves locally minimax optimal expected cumulative regret.
Projection Robust Wasserstein Barycenters
Feb 22, 2021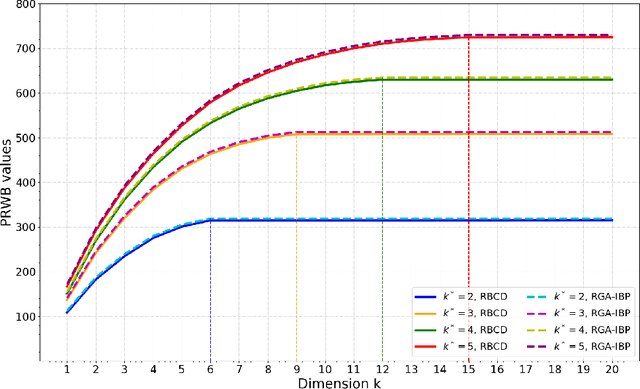

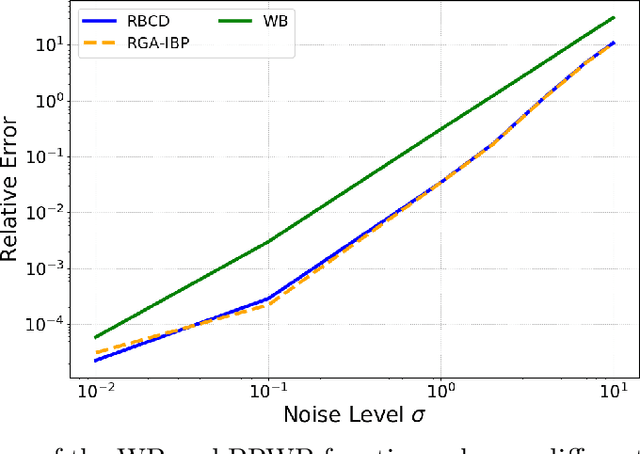
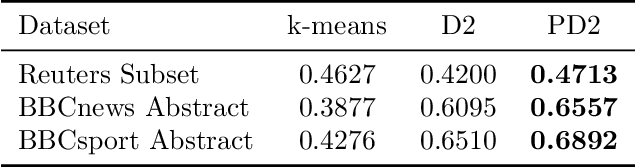
Collecting and aggregating information from several probability measures or histograms is a fundamental task in machine learning. One of the popular solution methods for this task is to compute the barycenter of the probability measures under the Wasserstein metric. However, approximating the Wasserstein barycenter is numerically challenging because of the curse of dimensionality. This paper proposes the projection robust Wasserstein barycenter (PRWB) that has the potential to mitigate the curse of dimensionality. Since PRWB is numerically very challenging to solve, we further propose a relaxed PRWB (RPRWB) model, which is more tractable. The RPRWB projects the probability measures onto a lower-dimensional subspace that maximizes the Wasserstein barycenter objective. The resulting problem is a max-min problem over the Stiefel manifold. By combining the iterative Bregman projection algorithm and Riemannian optimization, we propose two new algorithms for computing the RPRWB. The complexity of arithmetic operations of the proposed algorithms for obtaining an $\epsilon$-stationary solution is analyzed. We incorporate the RPRWB into a discrete distribution clustering algorithm, and the numerical results on real text datasets confirm that our RPRWB model helps improve the clustering performance significantly.
A Riemannian Block Coordinate Descent Method for Computing the Projection Robust Wasserstein Distance
Jan 13, 2021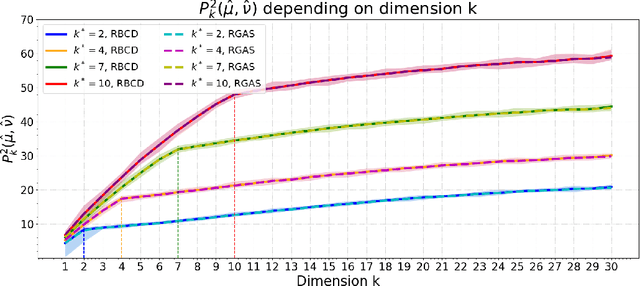
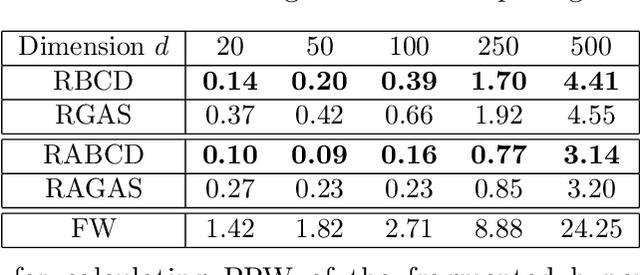
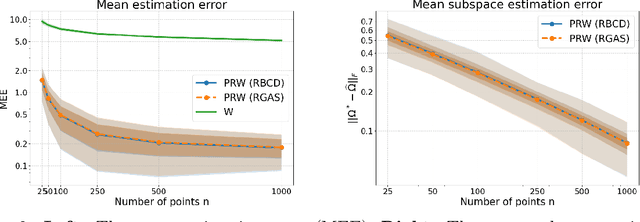
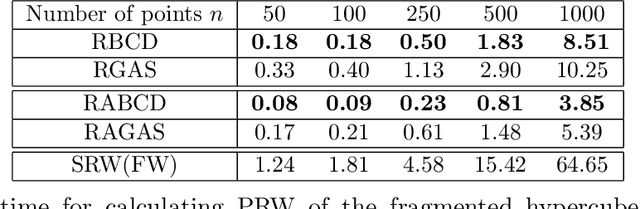
The Wasserstein distance has become increasingly important in machine learning and deep learning. Despite its popularity, the Wasserstein distance is hard to approximate because of the curse of dimensionality. A recently proposed approach to alleviate the curse of dimensionality is to project the sampled data from the high dimensional probability distribution onto a lower-dimensional subspace, and then compute the Wasserstein distance between the projected data. However, this approach requires to solve a max-min problem over the Stiefel manifold, which is very challenging in practice. The only existing work that solves this problem directly is the RGAS (Riemannian Gradient Ascent with Sinkhorn Iteration) algorithm, which requires to solve an entropy-regularized optimal transport problem in each iteration, and thus can be costly for large-scale problems. In this paper, we propose a Riemannian block coordinate descent (RBCD) method to solve this problem, which is based on a novel reformulation of the regularized max-min problem over the Stiefel manifold. We show that the complexity of arithmetic operations for RBCD to obtain an $\epsilon$-stationary point is $O(\epsilon^{-3})$. This significantly improves the corresponding complexity of RGAS, which is $O(\epsilon^{-12})$. Moreover, our RBCD has very low per-iteration complexity, and hence is suitable for large-scale problems. Numerical results on both synthetic and real datasets demonstrate that our method is more efficient than existing methods, especially when the number of sampled data is very large.
On the Adversarial Robustness of LASSO Based Feature Selection
Oct 20, 2020
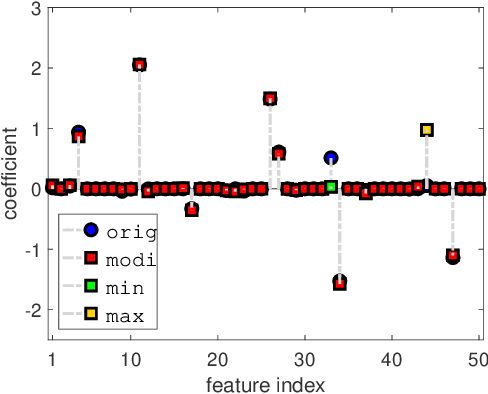
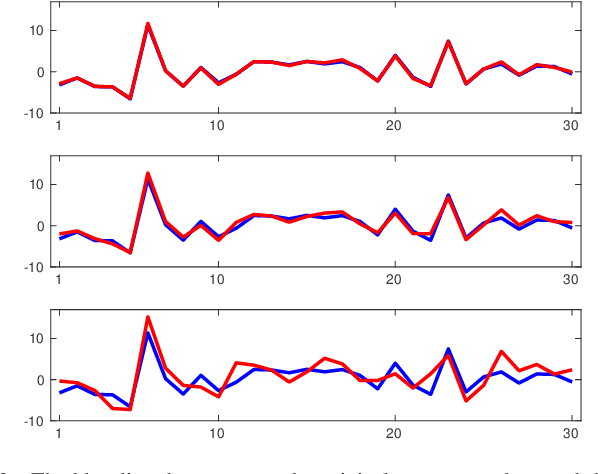
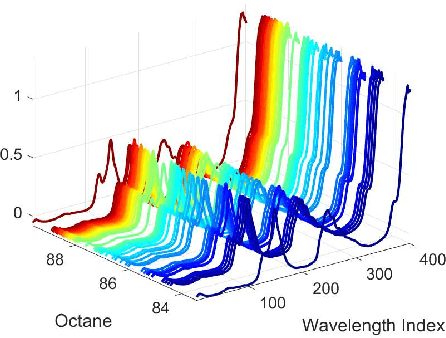
In this paper, we investigate the adversarial robustness of feature selection based on the $\ell_1$ regularized linear regression model, namely LASSO. In the considered model, there is a malicious adversary who can observe the whole dataset, and then will carefully modify the response values or the feature matrix in order to manipulate the selected features. We formulate the modification strategy of the adversary as a bi-level optimization problem. Due to the difficulty of the non-differentiability of the $\ell_1$ norm at the zero point, we reformulate the $\ell_1$ norm regularizer as linear inequality constraints. We employ the interior-point method to solve this reformulated LASSO problem and obtain the gradient information. Then we use the projected gradient descent method to design the modification strategy. In addition, We demonstrate that this method can be extended to other $\ell_1$ based feature selection methods, such as group LASSO and sparse group LASSO. Numerical examples with synthetic and real data illustrate that our method is efficient and effective.
Analysis of KNN Density Estimation
Sep 30, 2020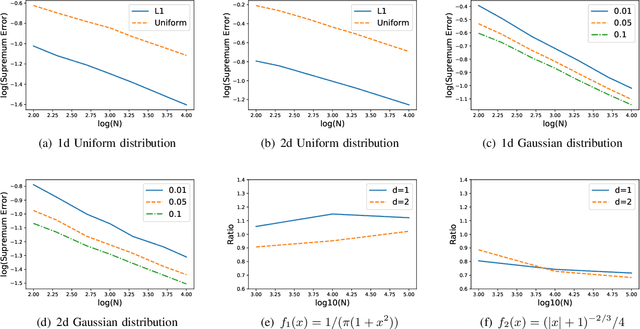
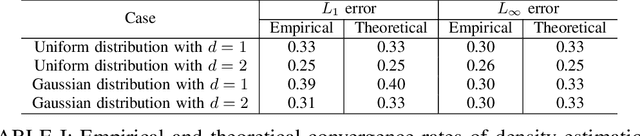
We analyze the $\ell_1$ and $\ell_\infty$ convergence rates of k nearest neighbor density estimation method. Our analysis includes two different cases depending on whether the support set is bounded or not. In the first case, the probability density function has a bounded support and is bounded away from zero. We show that kNN density estimation is minimax optimal under both $\ell_1$ and $\ell_\infty$ criteria, if the support set is known. If the support set is unknown, then the convergence rate of $\ell_1$ error is not affected, while $\ell_\infty$ error does not converge. In the second case, the probability density function can approach zero and is smooth everywhere. Moreover, the Hessian is assumed to decay with the density values. For this case, our result shows that the $\ell_\infty$ error of kNN density estimation is nearly minimax optimal. The $\ell_1$ error does not reach the minimax lower bound, but is better than kernel density estimation.
Robust Low-rank Matrix Completion via an Alternating Manifold Proximal Gradient Continuation Method
Aug 18, 2020



Robust low-rank matrix completion (RMC), or robust principal component analysis with partially observed data, has been studied extensively for computer vision, signal processing and machine learning applications. This problem aims to decompose a partially observed matrix into the superposition of a low-rank matrix and a sparse matrix, where the sparse matrix captures the grossly corrupted entries of the matrix. A widely used approach to tackle RMC is to consider a convex formulation, which minimizes the nuclear norm of the low-rank matrix (to promote low-rankness) and the l1 norm of the sparse matrix (to promote sparsity). In this paper, motivated by some recent works on low-rank matrix completion and Riemannian optimization, we formulate this problem as a nonsmooth Riemannian optimization problem over Grassmann manifold. This new formulation is scalable because the low-rank matrix is factorized to the multiplication of two much smaller matrices. We then propose an alternating manifold proximal gradient continuation (AManPGC) method to solve the proposed new formulation. The convergence rate of the proposed algorithm is rigorously analyzed. Numerical results on both synthetic data and real data on background extraction from surveillance videos are reported to demonstrate the advantages of the proposed new formulation and algorithm over several popular existing approaches.
Optimal Feature Manipulation Attacks Against Linear Regression
Feb 29, 2020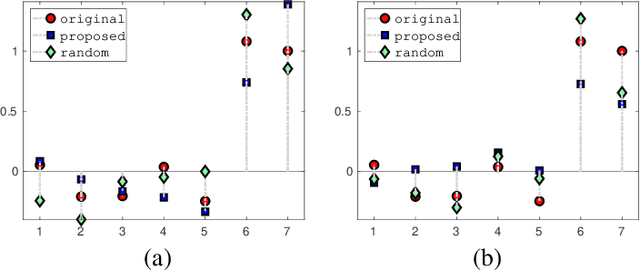
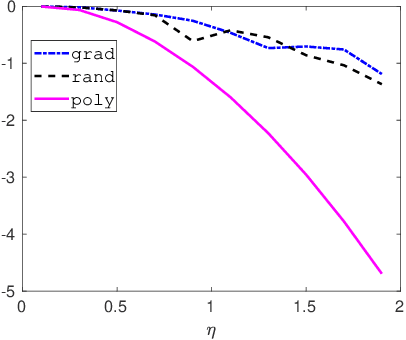
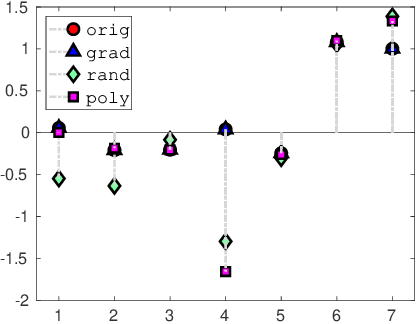
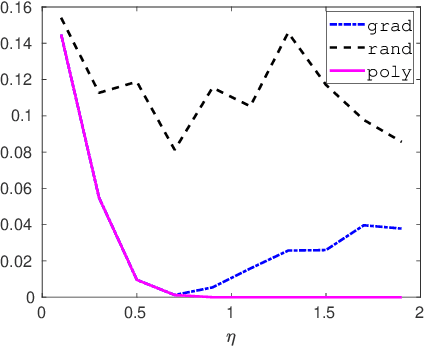
In this paper, we investigate how to manipulate the coefficients obtained via linear regression by adding carefully designed poisoning data points to the dataset or modify the original data points. Given the energy budget, we first provide the closed-form solution of the optimal poisoning data point when our target is modifying one designated regression coefficient. We then extend the analysis to the more challenging scenario where the attacker aims to change one particular regression coefficient while making others to be changed as small as possible. For this scenario, we introduce a semidefinite relaxation method to design the best attack scheme. Finally, we study a more powerful adversary who can perform a rank-one modification on the feature matrix. We propose an alternating optimization method to find the optimal rank-one modification matrix. Numerical examples are provided to illustrate the analytical results obtained in this paper.
Minimax Optimal Estimation of KL Divergence for Continuous Distributions
Feb 26, 2020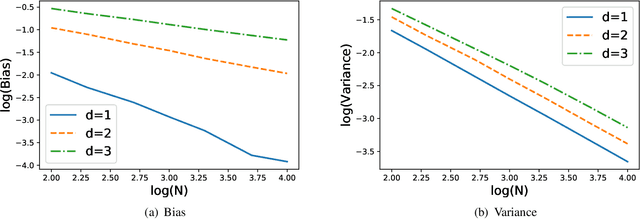
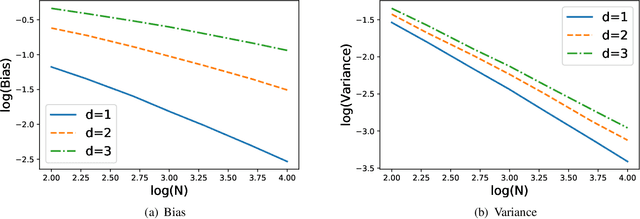
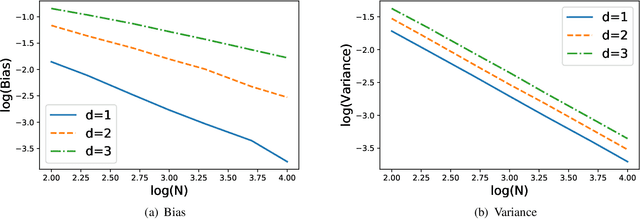
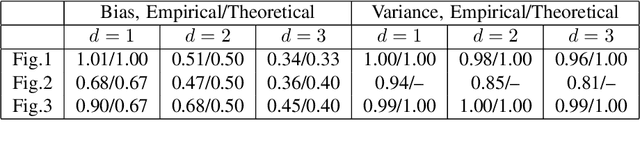
Estimating Kullback-Leibler divergence from identical and independently distributed samples is an important problem in various domains. One simple and effective estimator is based on the k nearest neighbor distances between these samples. In this paper, we analyze the convergence rates of the bias and variance of this estimator. Furthermore, we derive a lower bound of the minimax mean square error and show that kNN method is asymptotically rate optimal.
Minimax Rate Optimal Adaptive Nearest Neighbor Classification and Regression
Oct 22, 2019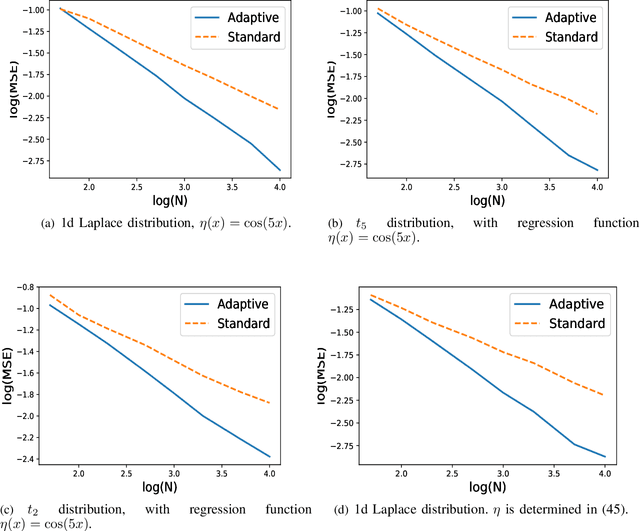
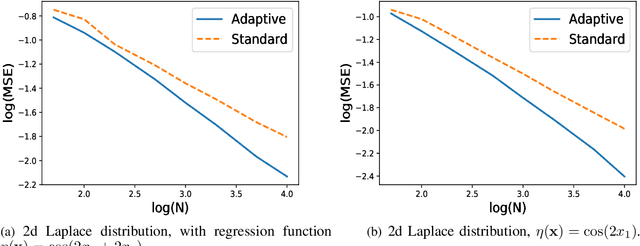
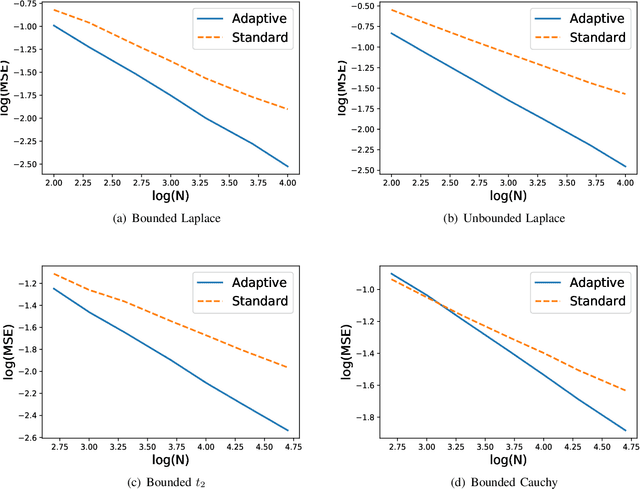
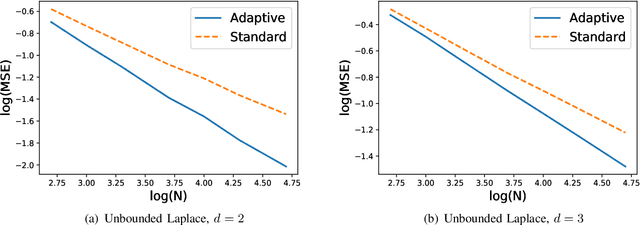
k Nearest Neighbor (kNN) method is a simple and popular statistical method for classification and regression. For both classification and regression problems, existing works have shown that, if the distribution of the feature vector has bounded support and the probability density function is bounded away from zero in its support, the convergence rate of the standard kNN method, in which k is the same for all test samples, is minimax optimal. On the contrary, if the distribution has unbounded support, we show that there is a gap between the convergence rate achieved by the standard kNN method and the minimax bound. To close this gap, we propose an adaptive kNN method, in which different k is selected for different samples. Our selection rule does not require precise knowledge of the underlying distribution of features. The new proposed method significantly outperforms the standard one. We characterize the convergence rate of the proposed adaptive method, and show that it matches the minimax lower bound.