 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reproducible Log-Driven AutoML Framework for Interpretable Pipeline Optimization in Healthcare Risk Prediction
May 19, 2026Accurate and reproducible disease risk prediction remains challenging due to heterogeneous features, limited samples, and severe class imbalance. This study introduces yvsoucom-iterkit, a deterministic and log-driven automated machine learning framework that formulates pipeline optimization as a fully reproducible, configuration-level system. Each pipeline is encoded as a traceable log entity, enabling analysis of component attribution, interactions, similarity, and cross-seed robustness. Experiments on the Pima Indians Diabetes and Stroke datasets across more than 18,000 pipeline configurations reveal a structured and partially redundant search space, where performance is governed by a small subset of interacting components. Random Forest importance analysis identifies augmentation (0.454), model choice (0.198), and imbalance handling (0.101) as key drivers on Pima, while imbalance handling dominates Stroke (0.406). Component similarity analysis shows strong redundancy, with feature selection variants (biMax-biMean) exhibiting low RMS distance (0.0252), mixup closely matching no augmentation (0.0279), and TomekLinks aligning with no imbalance handling (0.0325), whereas Gaussian noise shows greater divergence from no augmentation (0.10). The framework achieves strong and stable performance using ensemble models (Weighted-F1 0.89, Macro-F1 0.88 on Pima; Weighted-F1 0.94 on Stroke), while Macro-F1 remains lower on Stroke (0.67) due to class imbalance. Cross-seed analysis reveals a performance-robustness trade-off, with ensembles showing lower variability (0.023-0.026) than SVM. These results indicate that effective AutoML optimization can focus on a reduced set of high-impact components.
Chinese Traditional Poetry Generating System Based on Deep Learning
Oct 24, 2021
Chinese traditional poetry is an important intangible cultural heritage of China and an artistic carrier of thought, culture, spirit and emotion. However, due to the strict rules of ancient poetry, it is very difficult to write poetry by machine. This paper proposes an automatic generation method of Chinese traditional poetry based on deep learning technology, which extracts keywords from each poem and matches them with the previous text to make the poem conform to the theme, and when a user inputs a paragraph of text, the machine obtains the theme and generates poem sentence by sentence. Using the classic word2vec model as the preprocessing model, the Chinese characters which are not understood by the computer are transformed into matrix for processing. Bi-directional Long Short-Term Memory is used as the neural network model to generate Chinese characters one by one and make the meaning of Chinese characters as accurate as possible. At the same time, TF-IDF and TextRank are used to extract keywords. Using the attention mechanism based encoding-decoding model, we can solve practical problems by transforming the model, and strengthen the important information of long-distance information, so as to grasp the key points without losing important information. In the aspect of emotion judgment, Long Short-Term Memory network is used. The final result shows that it can get good poetry outputs according to the user input text.
Bach Style Music Authoring System based on Deep Learning
Oct 06, 2021

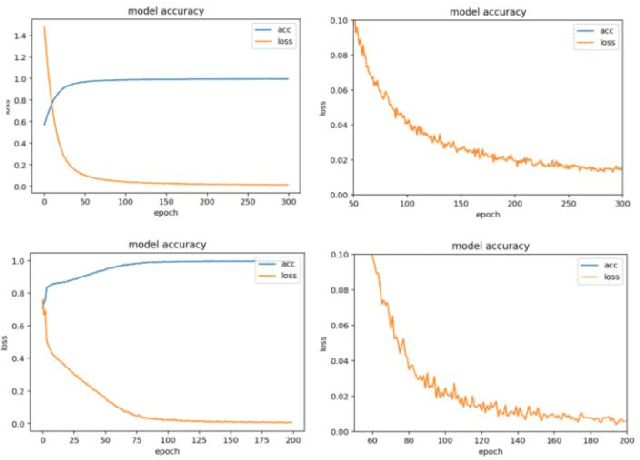
With the continuous improvement in various aspects in the field of artificial intelligence, the momentum of artificial intelligence with deep learning capabilities into the field of music is coming. The research purpose of this paper is to design a Bach style music authoring system based on deep learning. We use a LSTM neural network to train serialized and standardized music feature data. By repeated experiments, we find the optimal LSTM model which can generate imitation of Bach music. Finally the generated music is comprehensively evaluated in the form of online audition and Turing test. The repertoires which the music generation system constructed in this article are very close to the style of Bach's original music, and it is relatively difficult for ordinary people to distinguish the musics Bach authored and AI created.