 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly supervised segment annotation via expectation kernel density estimation
Dec 15, 2018

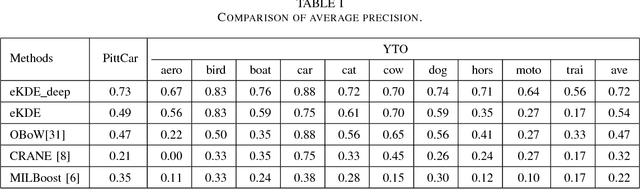
Since the labelling for the positive images/videos is ambiguous in weakly supervised segment annotation, negative mining based methods that only use the intra-class information emerge. In these methods, negative instances are utilized to penalize unknown instances to rank their likelihood of being an object, which can be considered as a voting in terms of similarity. However, these methods 1) ignore the information contained in positive bags, 2) only rank the likelihood but cannot generate an explicit decision function. In this paper, we propose a voting scheme involving not only the definite negative instances but also the ambiguous positive instances to make use of the extra useful information in the weakly labelled positive bags. In the scheme, each instance votes for its label with a magnitude arising from the similarity, and the ambiguous positive instances are assigned soft labels that are iteratively updated during the voting. It overcomes the limitations of voting using only the negative bags. We also propose an expectation kernel density estimation (eKDE) algorithm to gain further insight into the voting mechanism. Experimental results demonstrate the superiority of our scheme beyond the baselines.
Feature and Region Selection for Visual Learning
Jan 19, 2016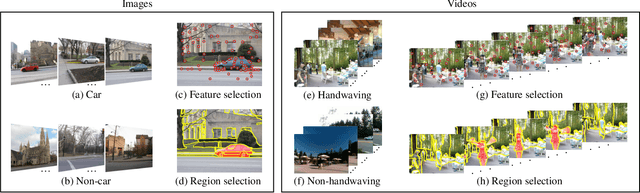


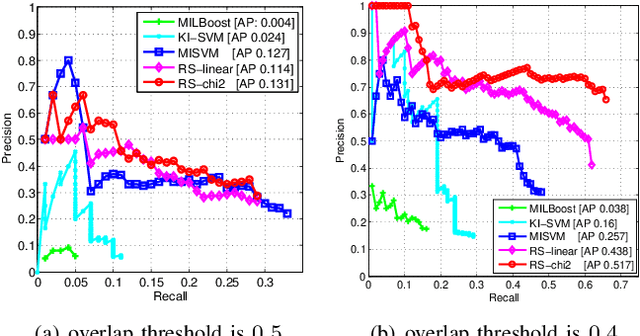
Visual learning problems such as object classification and action recognition are typically approached using extensions of the popular bag-of-words (BoW) model. Despite its great success, it is unclear what visual features the BoW model is learning: Which regions in the image or video are used to discriminate among classes? Which are the most discriminative visual words? Answering these questions is fundamental for understanding existing BoW models and inspiring better models for visual recognition. To answer these questions, this paper presents a method for feature selection and region selection in the visual BoW model. This allows for an intermediate visualization of the features and regions that are important for visual learning. The main idea is to assign latent weights to the features or regions, and jointly optimize these latent variables with the parameters of a classifier (e.g., support vector machine). There are four main benefits of our approach: (1) Our approach accommodates non-linear additive kernels such as the popular $\chi^2$ and intersection kernel; (2) our approach is able to handle both regions in images and spatio-temporal regions in videos in a unified way; (3) the feature selection problem is convex, and both problems can be solved using a scalable reduced gradient method; (4) we point out strong connections with multiple kernel learning and multiple instance learning approaches. Experimental results in the PASCAL VOC 2007, MSR Action Dataset II and YouTube illustrate the benefits of our approach.