 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOVA: A Verification-Aware Agent Harness for Architecture Evolution in Industrial Recommender Systems
Jun 25, 2026Industrial advertising recommender models are continuously improved through architecture evolution. Upgrades such as RankMixer, TokenMixer-Large, and MixFormer show that better structures remain a key source of quality and business gains. Yet developing such upgrades in production is expert-intensive and difficult to scale. Existing automation is insufficient: AutoML mainly tunes hyper-parameters, while effective gains often require cross-module changes under strict constraints; generic LLM coding agents optimize for runnable code, but runnable code does not imply a valid recommender architecture. Candidates may pass local tests while causing silent failures that degrade performance. We present NOVA, a level-aware agent harness for verification-aware architecture evolution. NOVA uses an architecture gradient, an SGD-inspired, non-differentiable update signal that aggregates prior modifications, verification diagnostics, metric feedback, and trajectory memory to guide the next modification. A verification cascade checks structure semantics, local executability, offline effectiveness, and online impact; invalid candidates are blocked early, with failure patterns recorded as forbidden directions. L1--L4 task-level control matches automation to task complexity and risk, routing high-risk tasks to Copilot for human oversight. Deployed in an industrial advertising system, NOVA achieves the highest effective pass rate on L2 ScaleUp and L3 Literature-to-Production tasks (54.5% and 60.0%), reduces silent failures compared with coding-agent baselines, and shortens one literature-to-production cycle by over 13x in human-attended time. In online A/B testing, the selected L3 candidate improves GMV on three pCVR objectives by +1.25%, +1.70%, and +2.02%, while reducing pCVR bias by 58.8%, 66.7%, and 37.3%.
AdaptiveReID: Adaptive L2 Regularization in Person Re-Identification
Jul 15, 2020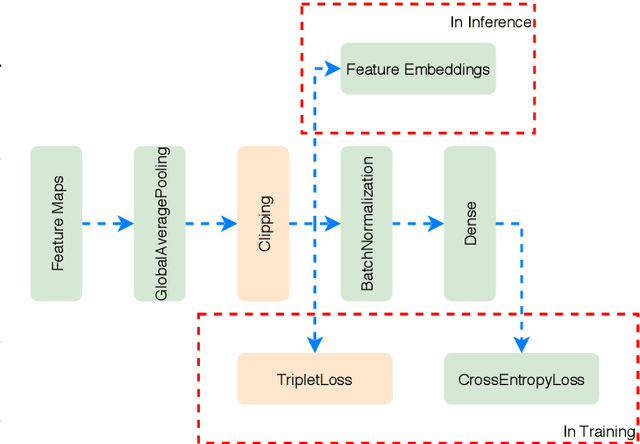
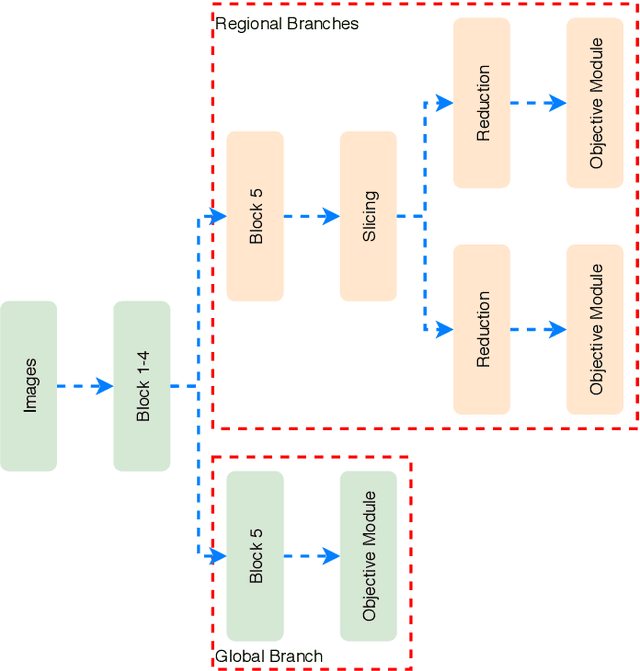
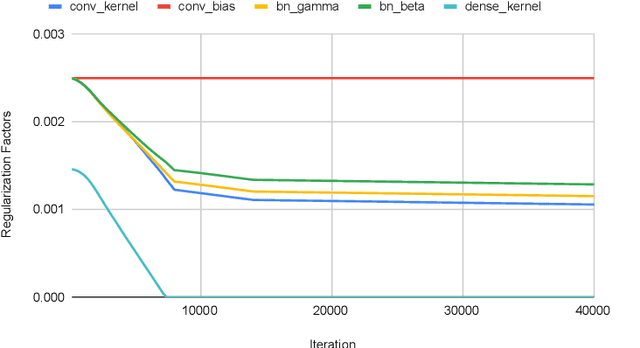
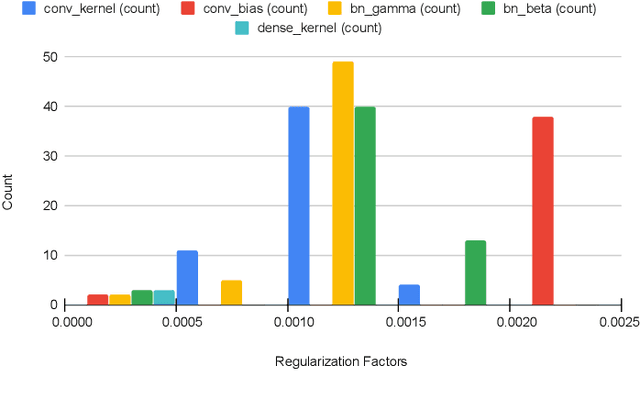
We introduce an adaptive L2 regularization mechanism termed AdaptiveReID, in the setting of person re-identification. In the literature, it is common practice to utilize hand-picked regularization factors which remain constant throughout the training procedure. Unlike existing approaches, the regularization factors in our proposed method are updated adaptively through backpropagation. This is achieved by incorporating trainable scalar variables as the regularization factors, which are further fed into a scaled hard sigmoid function. Extensive experiments on the Market-1501, DukeMTMC-reID and MSMT17 datasets validate the effectiveness of our framework. Most notably, we obtain state-of-the-art performance on MSMT17, which is the largest dataset for person re-identification. Source code will be published at https://github.com/nixingyang/AdaptiveReID.