 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatson & Holmes: A Naturalistic Benchmark for Comparing Human and LLM Reasoning
Feb 23, 2026Existing benchmarks for AI reasoning provide limited insight into how closely these capabilities resemble human reasoning in naturalistic contexts. We present an adaptation of the Watson & Holmes detective tabletop game as a new benchmark designed to evaluate reasoning performance using incrementally presented narrative evidence, open-ended questions and unconstrained language responses. An automated grading system was developed and validated against human assessors to enable scalable and replicable performance evaluation. Results show a clear improvement in AI model performance over time. Over nine months of 2025, model performance rose from the lower quartile of the human comparison group to approximately the top 5%. Around half of this improvement reflects steady advancement across successive model releases, while the remainder corresponds to a marked step change associated with reasoning-oriented model architectures. Systematic differences in the performance of AI models compared to humans, dependent on features of the specific detection puzzle, were mostly absent with the exception of a fall in performance for models when solving longer cases (case lengths being in the range of 1900-4000 words), and an advantage at inductive reasoning for reasoning models at early stages of case solving when evidence was scant.
Transcript of GPT-4 playing a rogue AGI in a Matrix Game
May 16, 2024Matrix Games are a type of unconstrained wargame used by planners to explore scenarios. Players propose actions, and give arguments and counterarguments for their success. An umpire, assisted by dice rolls modified according to the offered arguments, adjudicates the outcome of each action. A recent online play of the Matrix Game QuAI Sera Sera had six players, representing social, national and economic powers, and one player representing ADA, a recently escaped AGI. Unknown to the six human players, ADA was played by OpenAI's GPT-4 with a human operator serving as bidirectional interface between it and the game. GPT-4 demonstrated confident and competent game play; initiating and responding to private communications with other players and choosing interesting actions well supported by argument. We reproduce the transcript of the interaction with GPT-4 as it is briefed, plays, and debriefed.
Susceptibility to Influence of Large Language Models
Mar 10, 2023



Two studies tested the hypothesis that a Large Language Model (LLM) can be used to model psychological change following exposure to influential input. The first study tested a generic mode of influence - the Illusory Truth Effect (ITE) - where earlier exposure to a statement (through, for example, rating its interest) boosts a later truthfulness test rating. Data was collected from 1000 human participants using an online experiment, and 1000 simulated participants using engineered prompts and LLM completion. 64 ratings per participant were collected, using all exposure-test combinations of the attributes: truth, interest, sentiment and importance. The results for human participants reconfirmed the ITE, and demonstrated an absence of effect for attributes other than truth, and when the same attribute is used for exposure and test. The same pattern of effects was found for LLM-simulated participants. The second study concerns a specific mode of influence - populist framing of news to increase its persuasion and political mobilization. Data from LLM-simulated participants was collected and compared to previously published data from a 15-country experiment on 7286 human participants. Several effects previously demonstrated from the human study were replicated by the simulated study, including effects that surprised the authors of the human study by contradicting their theoretical expectations (anti-immigrant framing of news decreases its persuasion and mobilization); but some significant relationships found in human data (modulation of the effectiveness of populist framing according to relative deprivation of the participant) were not present in the LLM data. Together the two studies support the view that LLMs have potential to act as models of the effect of influence.
A New Angle on L2 Regularization
Jun 28, 2018Imagine two high-dimensional clusters and a hyperplane separating them. Consider in particular the angle between: the direction joining the two clusters' centroids and the normal to the hyperplane. In linear classification, this angle depends on the level of L2 regularization used. Can you explain why?
Better Image Segmentation by Exploiting Dense Semantic Predictions
Jun 05, 2016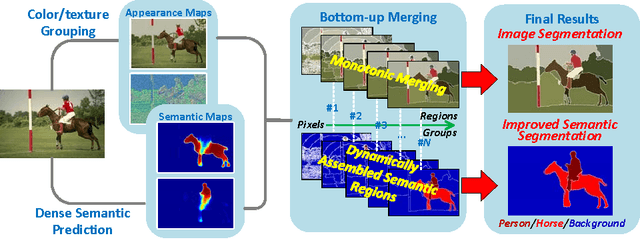
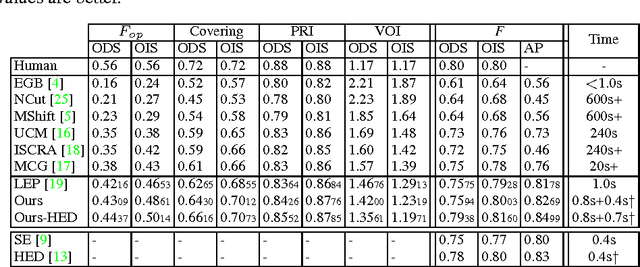


It is well accepted that image segmentation can benefit from utilizing multilevel cues. The paper focuses on utilizing the FCNN-based dense semantic predictions in the bottom-up image segmentation, arguing to take semantic cues into account from the very beginning. By this we can avoid merging regions of similar appearance but distinct semantic categories as possible. The semantic inefficiency problem is handled. We also propose a straightforward way to use the contour cues to suppress the noise in multilevel cues, thus to improve the segmentation robustness. The evaluation on the BSDS500 shows that we obtain the competitive region and boundary performance. Furthermore, since all individual regions can be assigned with appropriate semantic labels during the computation, we are capable of extracting the adjusted semantic segmentations. The experiment on Pascal VOC 2012 shows our improvement to the original semantic segmentations which derives directly from the dense predictions.
Suppressing the Unusual: towards Robust CNNs using Symmetric Activation Functions
Mar 16, 2016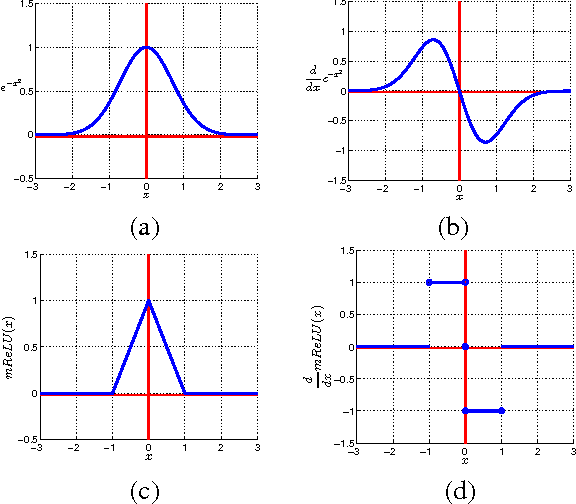

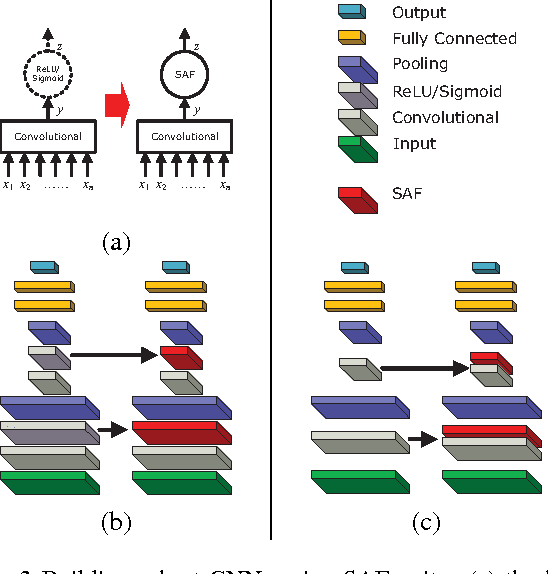
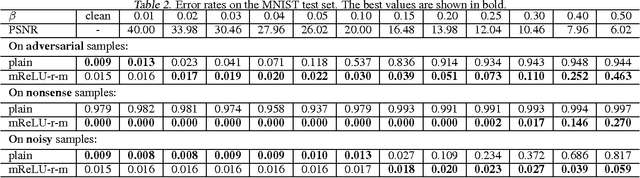
Many deep Convolutional Neural Networks (CNN) make incorrect predictions on adversarial samples obtained by imperceptible perturbations of clean samples. We hypothesize that this is caused by a failure to suppress unusual signals within network layers. As remedy we propose the use of Symmetric Activation Functions (SAF) in non-linear signal transducer units. These units suppress signals of exceptional magnitude. We prove that SAF networks can perform classification tasks to arbitrary precision in a simplified situation. In practice, rather than use SAFs alone, we add them into CNNs to improve their robustness. The modified CNNs can be easily trained using popular strategies with the moderate training load. Our experiments on MNIST and CIFAR-10 show that the modified CNNs perform similarly to plain ones on clean samples, and are remarkably more robust against adversarial and nonsense samples.