 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Reasoning is Not a Free Lunch: A Controlled Study on LLaVA
Mar 13, 2026Vision-language models (VLMs) have advanced rapidly, yet they still struggle with basic spatial reasoning. Despite strong performance on general benchmarks, modern VLMs remain brittle at understanding 2D spatial relationships such as relative position, layout, and counting. We argue that this failure is not merely a data problem, but is closely tied to dominant design choices in current VLM pipelines: reliance on CLIP-style image encoders and the flattening of images into 1D token sequences with 1D positional encoding. We present a controlled diagnostic study within the LLaVA framework to isolate how these choices affect spatial grounding. We evaluate frontier models and LLaVA variants on a suite of spatial benchmarks, comparing CLIP-based encoders against alternatives trained with denser or generative objectives, as well as variants augmented with 2D positional encoding. Our results show consistent spatial performance gaps across models, and indicate that encoder objectives and positional structure shape spatial behavior, but do not fully resolve it.
Beyond Accuracy: Evaluating Visual Grounding In Multimodal Medical Reasoning
Mar 03, 2026Recent work shows that text-only reinforcement learning with verifiable rewards (RLVR) can match or outperform image-text RLVR on multimodal medical VQA benchmarks, suggesting current evaluation protocols may fail to measure causal visual dependence. We introduce a counterfactual evaluation framework using real, blank, and shuffled images across four medical VQA benchmarks: PathVQA, PMC-VQA, SLAKE, and VQA-RAD. Beyond accuracy, we measure Visual Reliance Score (VRS), Image Sensitivity (IS), and introduce Hallucinated Visual Reasoning Rate (HVRR) to detect cases where models generate visual claims despite producing image-invariant answers. Our findings reveal that RLVR improves accuracy while degrading visual grounding: text-only RLVR achieves negative VRS on PathVQA (-0.09), performing better with mismatched images, while image-text RLVR reduces image sensitivity to 39.8% overall despite improving accuracy. On VQA-RAD, both variants achieve 63% accuracy through different mechanisms: text-only RLVR retains 81% performance with blank images, while image-text RLVR shows only 29% image sensitivity. Models generate visual claims in 68-74% of responses, yet 38-43% are ungrounded (HVRR). These findings demonstrate that accuracy-only rewards enable shortcut exploitation, and progress requires grounding-aware evaluation protocols and training objectives that explicitly enforce visual dependence.
The Spatial Blindspot of Vision-Language Models
Jan 15, 2026Vision-language models (VLMs) have advanced rapidly, but their ability to capture spatial relationships remains a blindspot. Current VLMs are typically built with contrastive language-image pretraining (CLIP) style image encoders. The training recipe often flattens images into 1D patch sequences, discarding the 2D structure necessary for spatial reasoning. We argue that this lack of spatial awareness is a missing dimension in VLM design and a bottleneck for applications requiring spatial grounding, such as robotics and embodied AI. To address this, we investigate (i) image encoders trained with alternative objectives and (ii) 2D positional encodings. Our experiments show that these architectural choices can lead to improved spatial reasoning on several benchmarks.
Histo-fetch -- On-the-fly processing of gigapixel whole slide images simplifies and speeds neural network training
Mar 01, 2021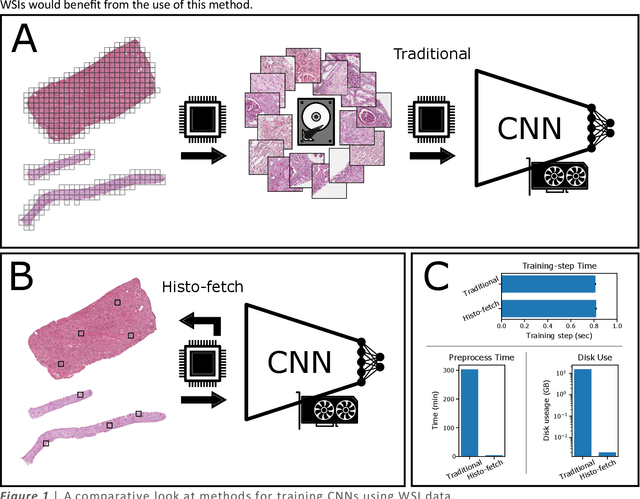
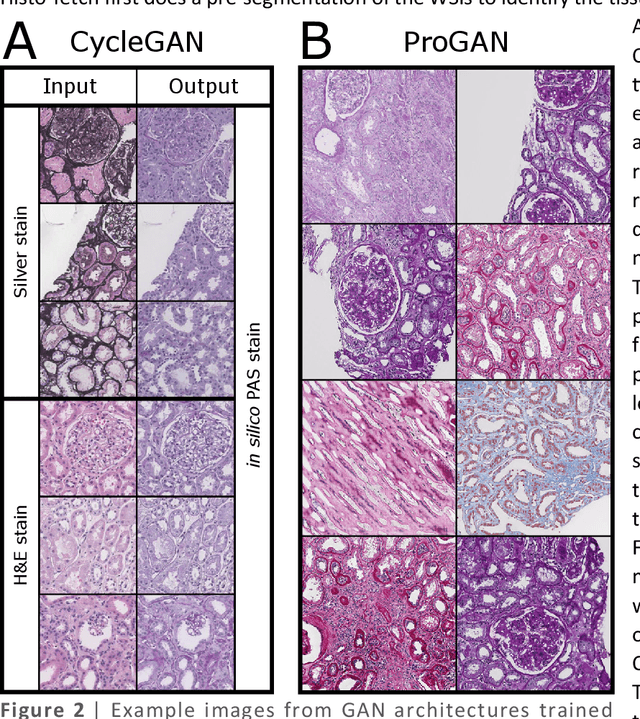
We created a custom pipeline (histo-fetch) to efficiently extract random patches and labels from pathology whole slide images (WSIs) for input to a neural network on-the-fly. We prefetch these patches as needed during network training, avoiding the need for WSI preparation such as chopping/tiling. We demonstrate the utility of this pipeline to perform artificial stain transfer and image generation using the popular networks CycleGAN and ProGAN, respectively.