Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Nontrivial Connectivity for Automatic Speech Recognition
Nov 28, 2017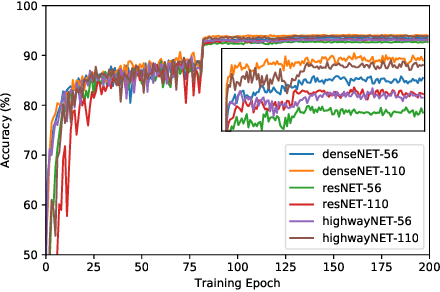
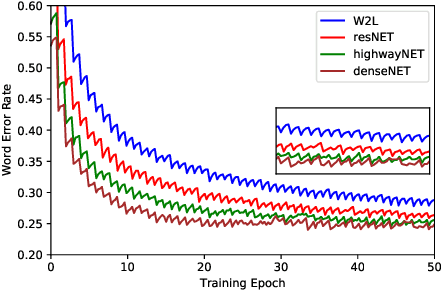

Nontrivial connectivity has allowed the training of very deep networks by addressing the problem of vanishing gradients and offering a more efficient method of reusing parameters. In this paper we make a comparison between residual networks, densely-connected networks and highway networks on an image classification task. Next, we show that these methodologies can easily be deployed into automatic speech recognition and provide significant improvements to existing models.
* Accepted at the ML4Audio workshop at the NIPS 2017
Via